• Machine Learning
•Automatic Machine Translation Evaluation Basics
• Key techniques
• State-of-the-art
• Goal & Motivation
• Study plan
3.
Machine Learning
• Abranch of AI; A scientific discipline concerned with the design
and development of algorithms that take as input empirical
data, and yield patterns or predictions thought to be features of
the underlying mechanism that generated the data
Automatic Machine Translation
Basics
•What is Machine Translation ( MT )?
• What is Machine Translation Evaluation?
More art than science:
数学+语言学+计算机科学
信、达、雅? 结果质量想多了! 多大程度上,某项任务
系统开发者:体现系统问题,修复完善翻译系统
用户:系统可用性
State-of-the-art
• BLEU系统 (BilingualEvaluation Understudy)
• 准确率(precision)与召回率(recall)
• N-gram match
• METEOR系统
• 在BLEU的基础上增加了词根还原和同义词检测
• 评价标准
System A: Israeli officials responsibility of airport safety
Reference: Israeli officials are responsible for airport security
System B: airport security Israeli officials are responsible
BLEU: A is better
METEOR: B is better
14.
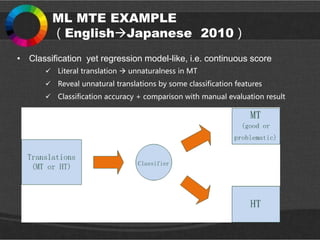
ML MTE EXAMPLE
(EnglishJapanese2010)
• Classification yet regression model-like, i.e. continuous score
Literal translation unnaturalness in MT
Reveal unnatural translations by some classification features
Classification accuracy + comparison with manual evaluation result
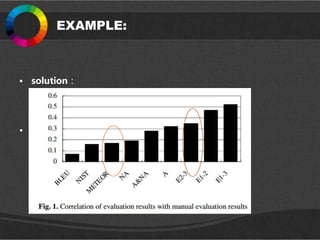
EXAMPLE:
• solution:
• Classificationfeature: aligned word pairs feature
• SVM
• Scores? The distance to the hyper-plane
• Experiments and test:
流程:
比较各个模型的性能,相关系数
17.
MT Evaluation KeyTechniques
(so far)
• including but not limited to:
SVM
I. popular/successful
II. various problem:
a) linearly separable : maximal margin hyperlane
b) linearly inseparable: soft margin, noise
c) nonlinear: 属性变换,或者 kernel
III. robust
IV. learning problem solved using
18.
Goal & Motivation
•一、实现上述论文中的基于分类器评价系统算法
• 二、实现其他论文中基于回归的评价系统
• 三、混合两种评价系统
Motivation:
• 因为本身对语言比较感兴趣,对机器翻译问题好奇。
• 机器学习是以后学习研究的主要工具,这次毕设相当于一次入门和实
践
• Challenge: 评测则是 more art than science , 不好定量。需要多了
解别人的思想
#15 Literal translation often makes MTs unnatural. Therefore, a critical issue in MT development is how to deal with literal translation. If a classifier uses classification features that reveal unnatural literal translations, classification results will reveal problematic MTs. Reducing unnatural literal translations would improve MTs
#18 –SVM is among the most popular/successful classifiers – It provides a principled way to learn a robust classifier (i.e., a decision boundary) – chooses the one with maximum margin principle – has sound theoretical guarantee – extends to nonlinear decision boundary by using kernel trick – learning problem efficiently solved using convex optimization techniques