Download to read offline


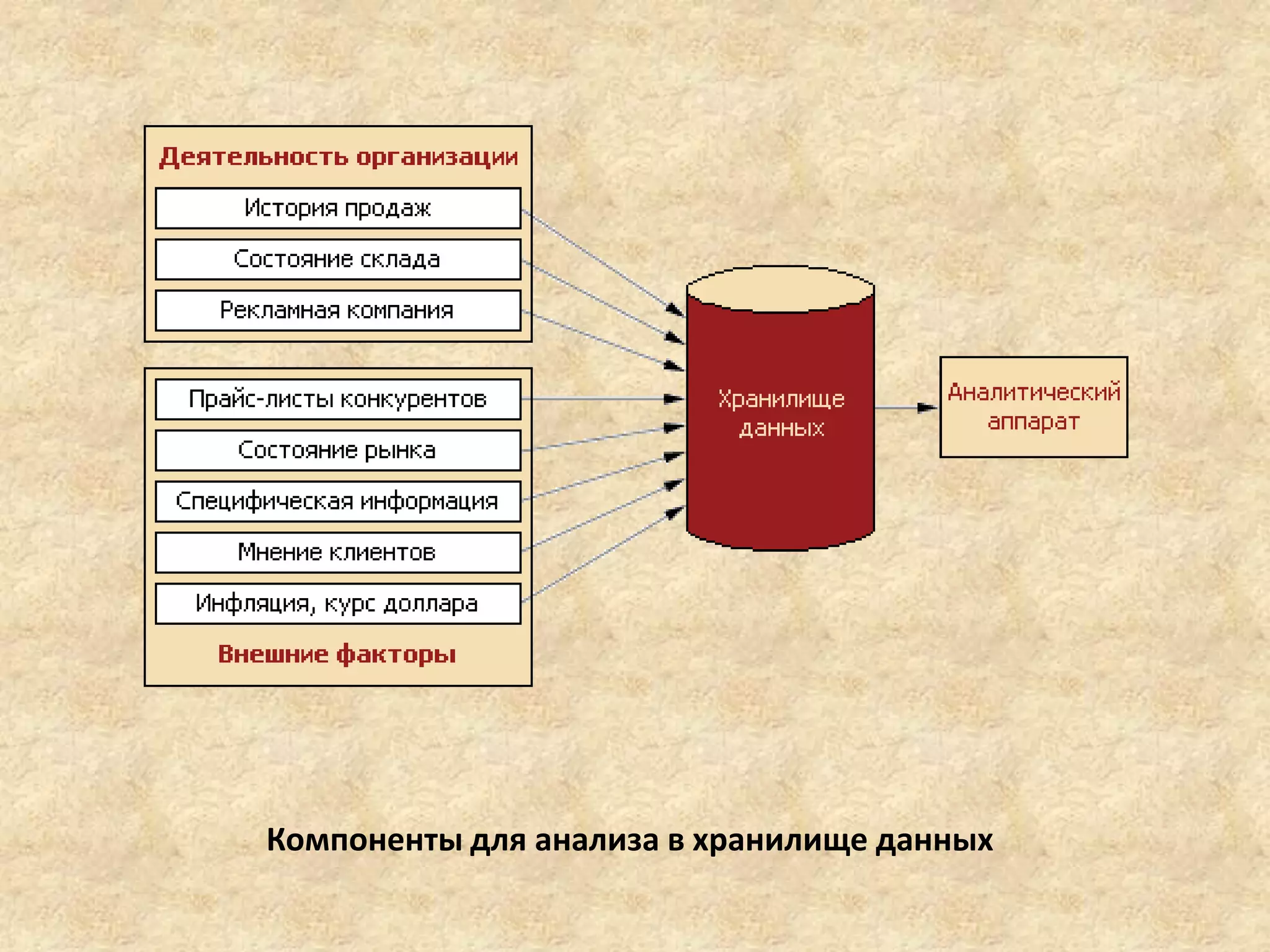










Хранилище данных является специализированной информационной базой для поддержки бизнес-анализа и принятия решений в организациях. Данные в нем доступны только для чтения и загружаются из транзакционных систем, обеспечивая интеграцию, неподверженность изменениям и зависимость от времени. Облачные хранилища позволяют клиентам использовать распределенные серверы, минимизируя затраты на инфраструктуру, но вызывают опасения по поводу безопасности и производительности.







































































