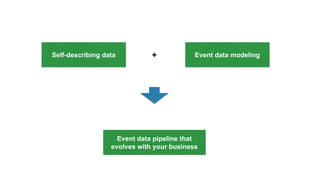
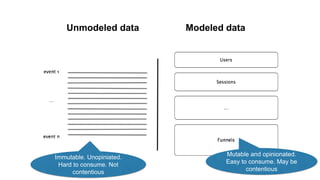
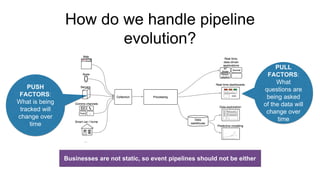
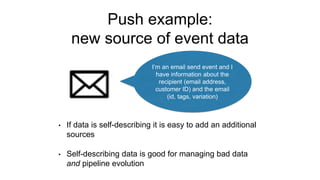
The document discusses the evolution of analytics using Snowplow, an open-source event data pipeline that allows businesses to model and define their own data events. It emphasizes the importance of self-describing data for adapting to changing business needs and supports both data validation and evolution of data models over time. Key components include event data modeling, managing data quality, and the ability to recompute historical data based on new models.






![You then define a schema
for each event and entity
{
"$schema":
"http://iglucentral.com/schemas/com.snowplowanalytics.self
-desc/schema/jsonschema/1-0-0#",
"description": "Schema for a fighter context",
"self": {
"vendor": "com.ufc",
"name": "fighter_context",
"format": "jsonschema",
"version": "1-0-1"
},
"type": "object",
"properties": {
"FirstName": {
"type": "string"
},
"LastName": {
"type": "string"
},
"Nickname": {
"type": "string"
},
"FacebookProfile": {
"type": "string"
},
"TwitterName": {
"type": "string"
},
"GooglePlusProfile": {
"type": "string"
},
"HeightFormat": {
"type": "string"
},
"HeightCm": {
"type": ["integer", "null"]
},
"Weight": {
"type": ["integer", "null"]
},
"WeightKg": {
"type": ["integer", "null"]
},
"Record": {
"type": "string",
"pattern": "^[0-9]+-[0-9]+-[0-9]+$"
},
"Striking": {
"type": ["number", "null"],
"maxdecimal": 15
},
"Takedowns": {
"type": ["number", "null"],
"maxdecimal": 15
},
"Submissions": {
"type": ["number", "null"],
"maxdecimal": 15
},
"LastFightUrl": {
"type": "string"
},
"LastFightEventText": {
"type": "string"
},
"NextFightUrl": {
"type": "string"
},
"NextFightEventText": {
"type": "string"
},
"LastFightDate": {
"type": "string",
"format": "timestamp"
}
},
"additionalProperties": false
}
Upload the
schema to
Iglu](https://image.slidesharecdn.com/snowplow-theevolvingdatapipeline-160805144508/85/Snowplow-the-evolving-data-pipeline-8-320.jpg)











































































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)







