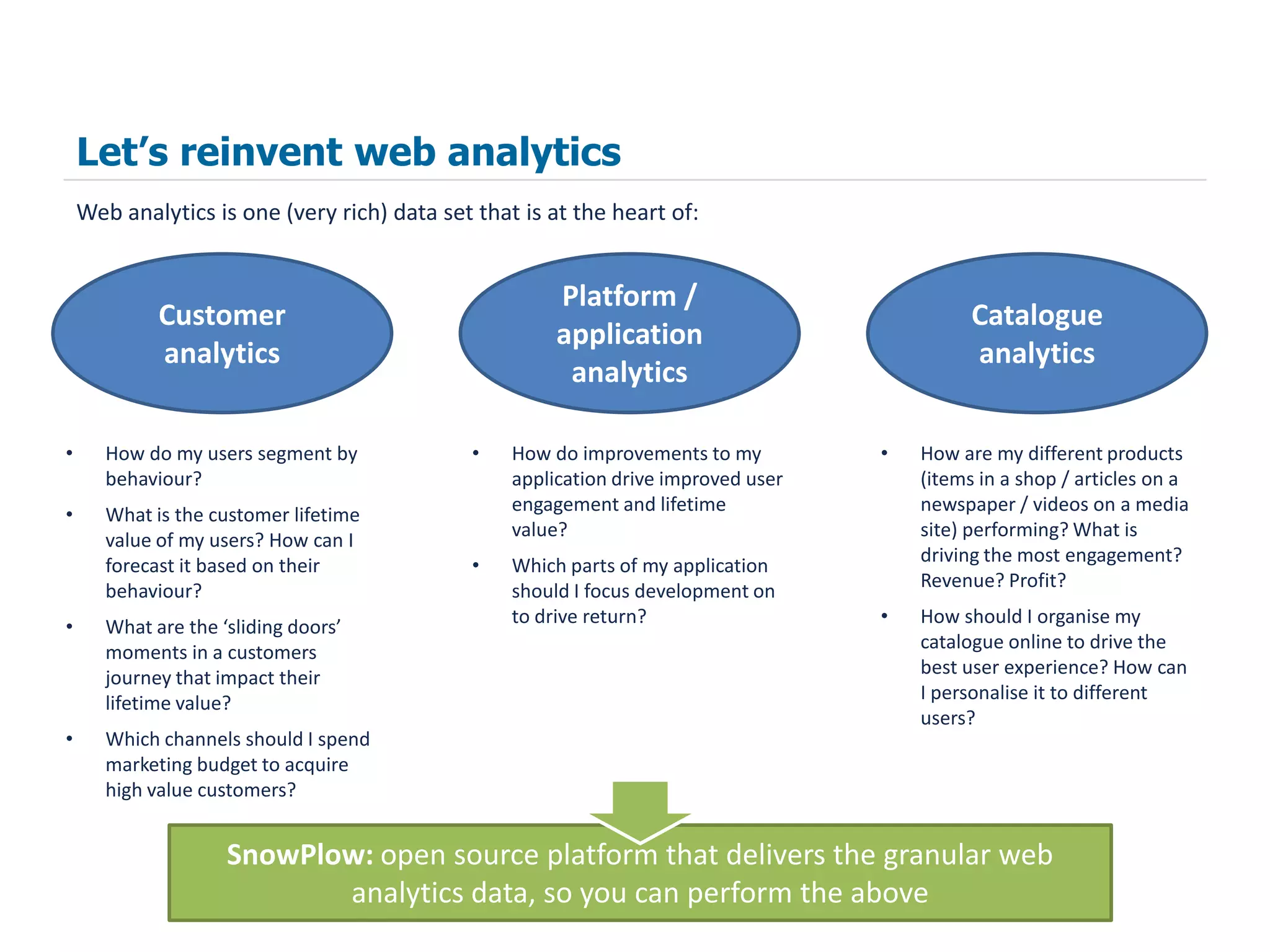
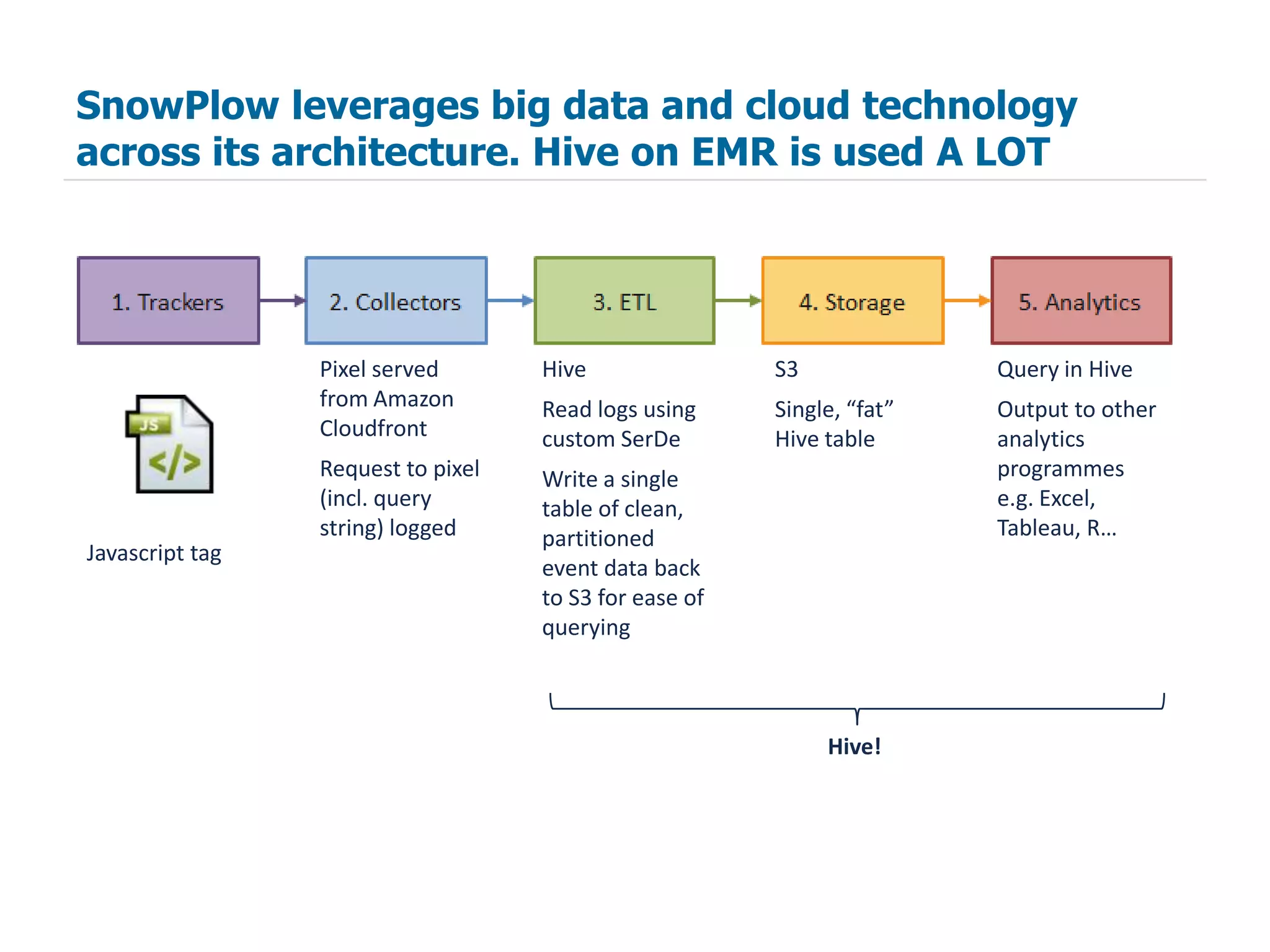
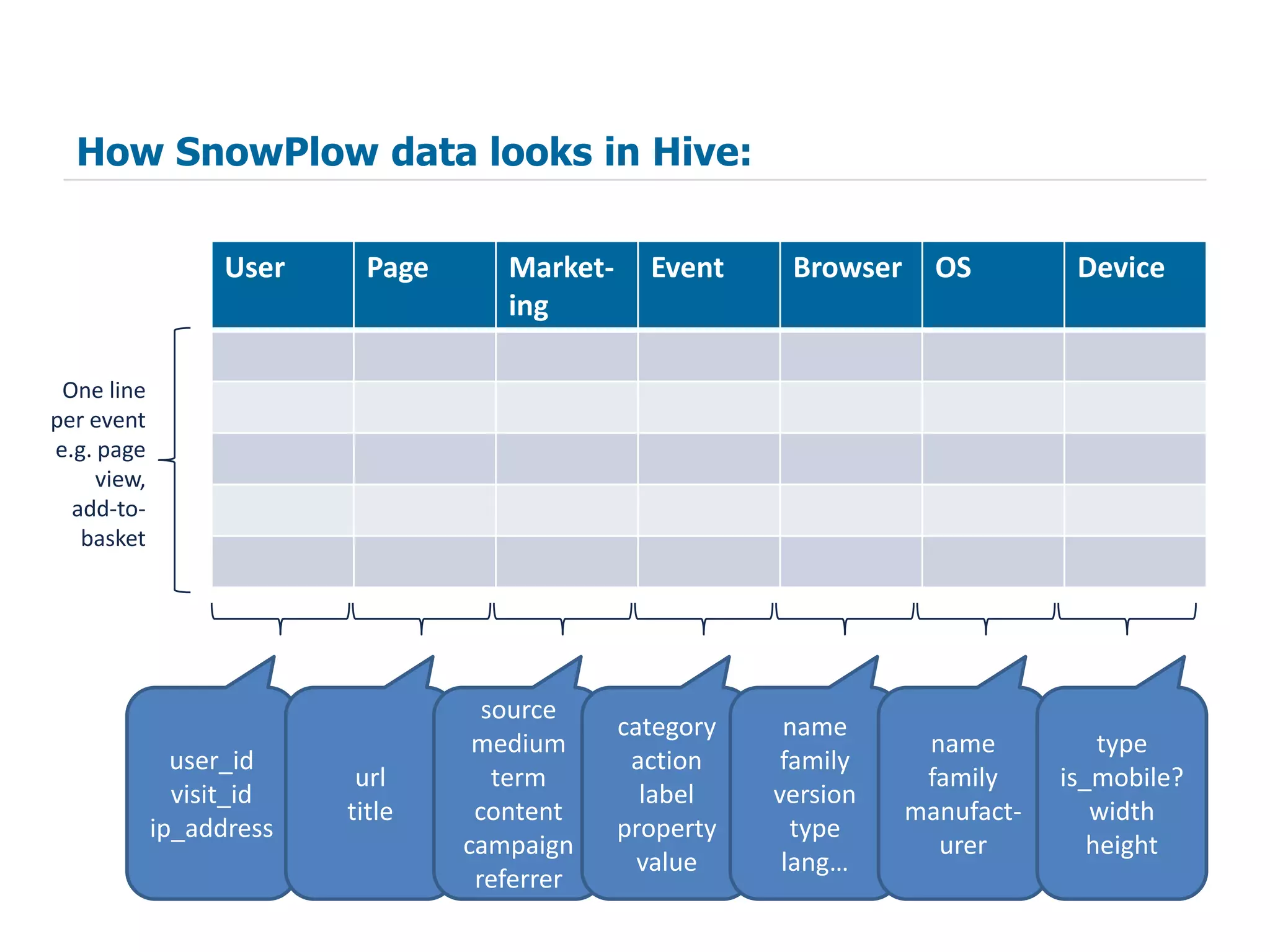
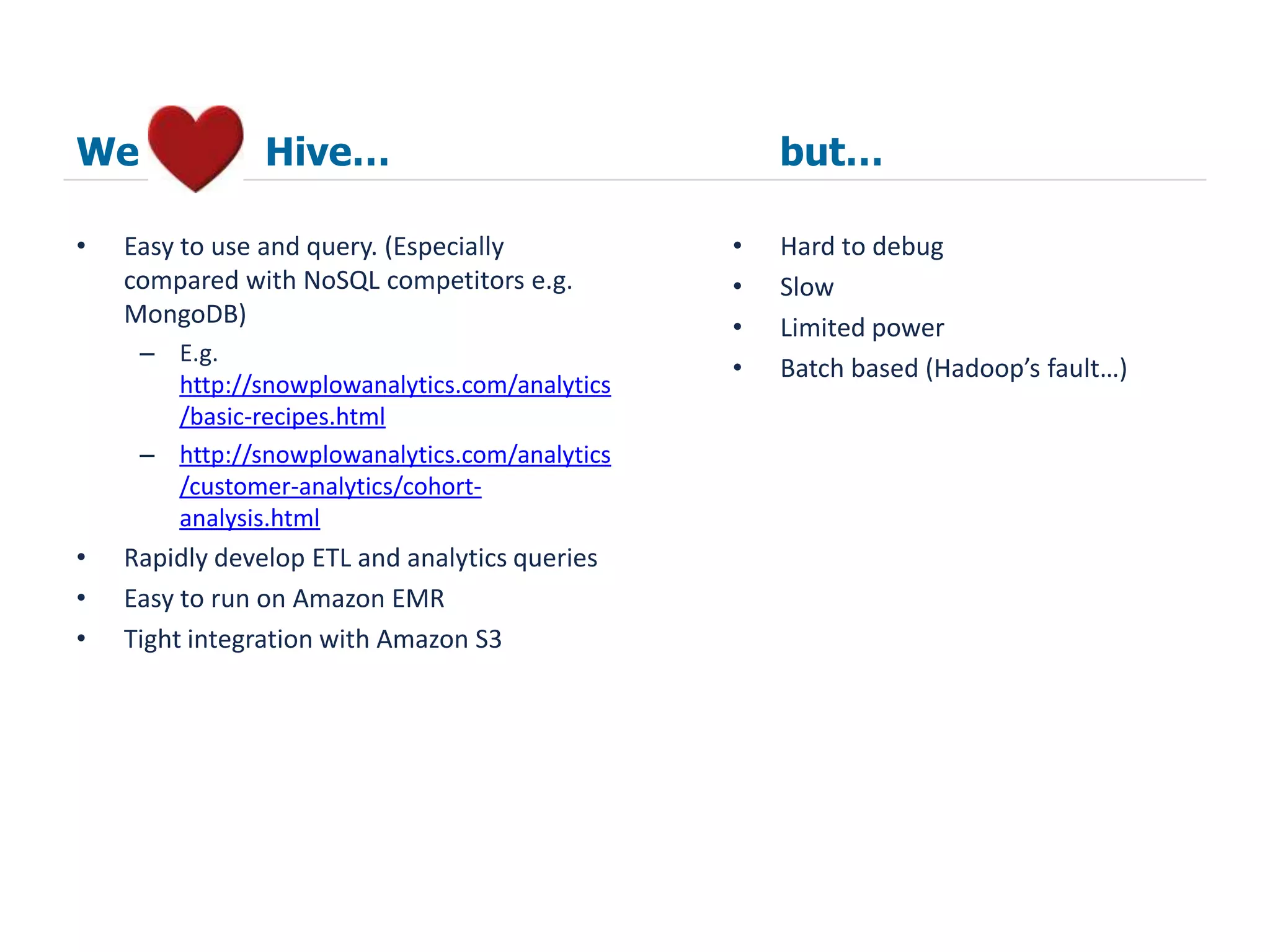
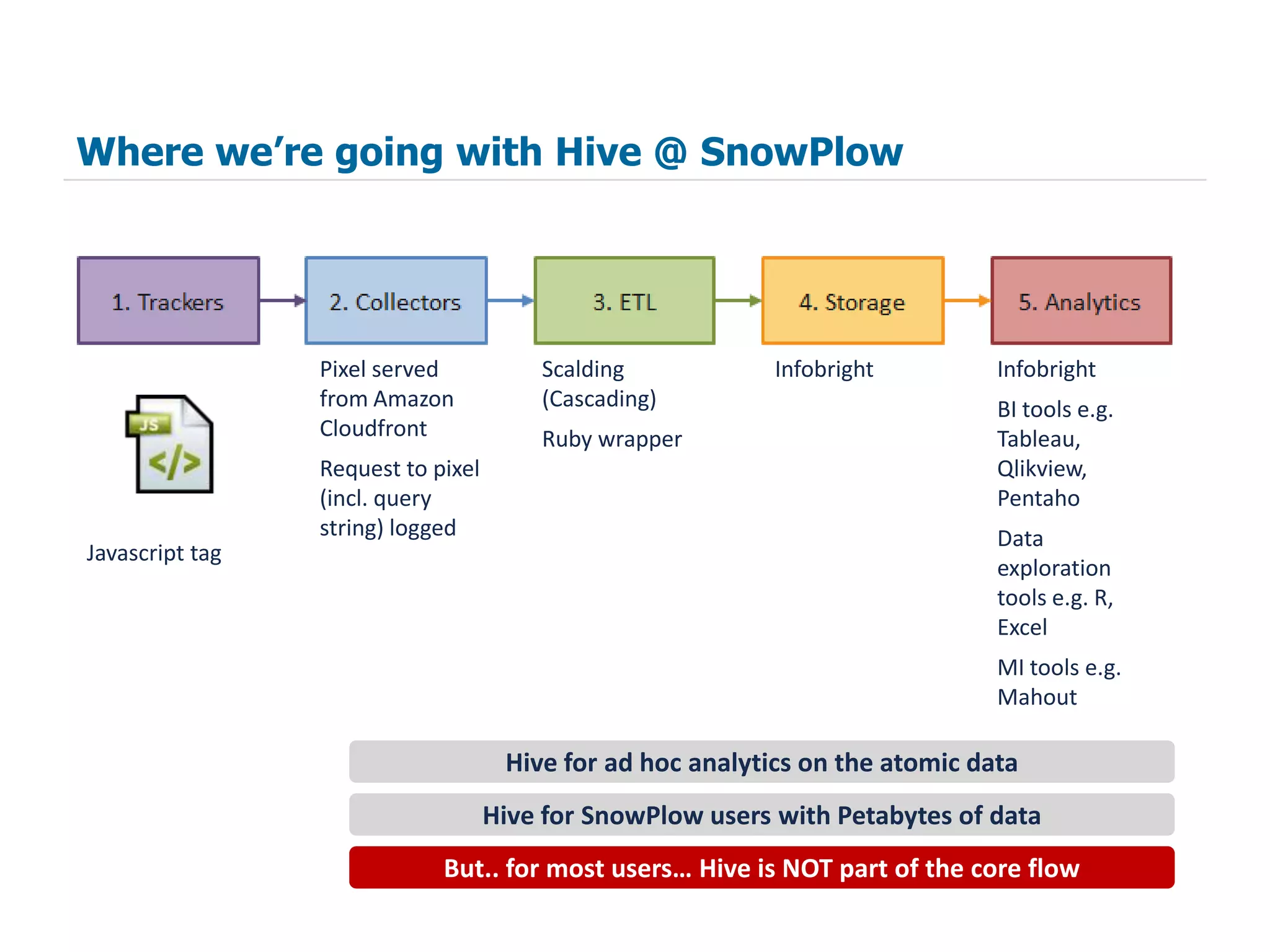
The document summarizes how SnowPlow uses Apache Hive and other big data technologies to perform web analytics. It discusses how Hive is used at SnowPlow, the strengths and weaknesses of Hive versus alternatives, and how SnowPlow is leveraging technologies like Scalding, Infobright, and Mahout for more robust ETL, faster queries, and machine learning capabilities beyond SQL.