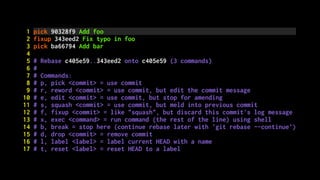
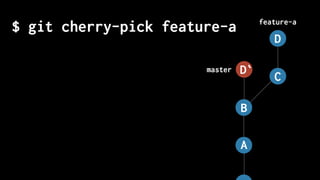
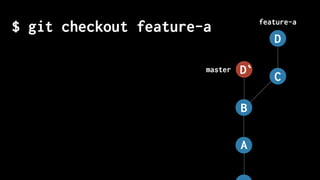
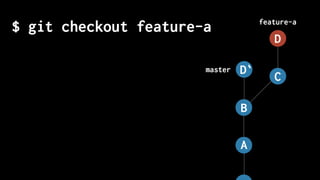
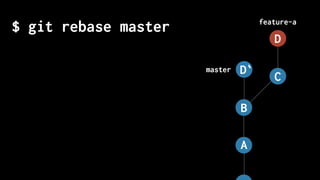
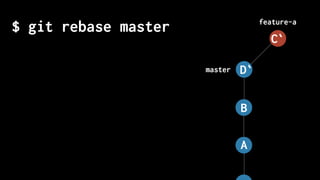
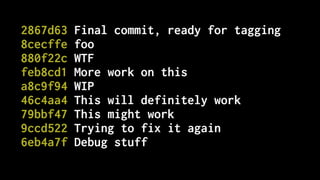
The document discusses five habits for simplifying code writing and managing changes in complex systems, focusing on effective use of version control systems, particularly Git. These habits include planning commits, using single purpose branches, making atomic commits, writing good commit messages, and rewriting history to maintain clarity in project development. The author emphasizes that employing these practices can enhance understanding and communication in coding processes.


































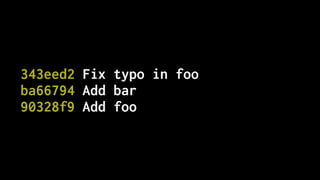
![$ git add --patch
diff --git a/layout/models.py b/layout/models.py
index f2dd5a8..b4dd522 100644
--- a/layout/models.py
+++ b/layout/models.py
@@ -27,7 +27,7 @@ class Layout(models.Model):
def __str__(self):
if self.is_layplan:
- return "Layplan: {}".format(self.data.get("slug", self.code))
+ return "Layplan: {}".format(self.data.get("name", self.code))
else:
return "Layout: {}".format(self.code)
Stage this hunk [y,n,q,a,d,e,?]?](https://image.slidesharecdn.com/simplify-with-deliberate-commits-london-python-march-2019-190328113737/85/Simplify-writing-code-with-deliberate-commits-London-Python-Meetup-44-320.jpg)




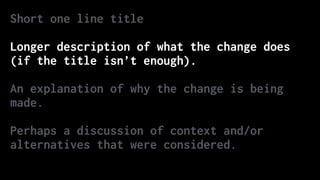



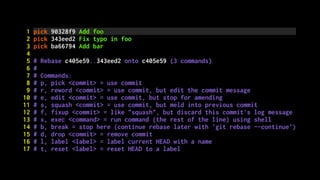
![Correct the colour of FAQ link in course notice footer
PT: https://www.pivotaltracker.com/story/show/84753832
In some email clients the colour of the FAQ link in the
course notice footer was being displayed as blue instead of
white. The examples given in PT are all different versions of
Outlook. Outlook won't implement CSS changes that include `!
important` inline[1]. Therefore, since we were using it to
define the colour of that link, Outlook wasn't applying that
style and thus simply set its default style (blue, like in
most browsers). Removing that `!important` should fix the
problem.
[1] https://www.campaignmonitor.com/blog/post/3143/
outlook-2007-and-the-inline-important-declaration/](https://image.slidesharecdn.com/simplify-with-deliberate-commits-london-python-march-2019-190328113737/85/Simplify-writing-code-with-deliberate-commits-London-Python-Meetup-54-320.jpg)