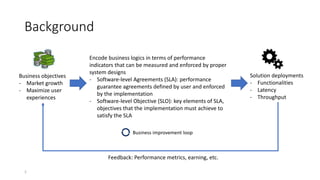
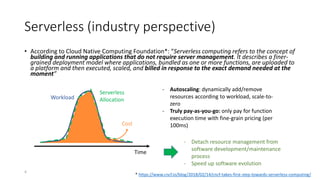
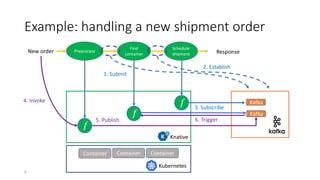
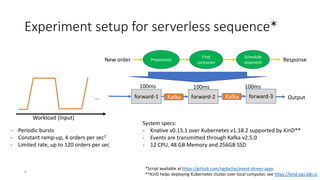
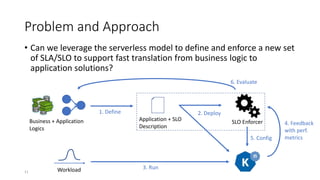
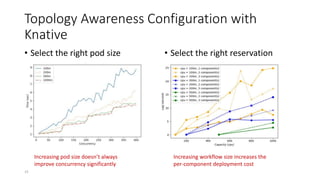
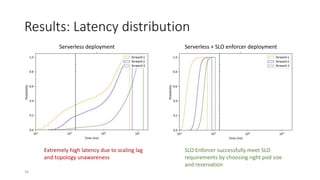
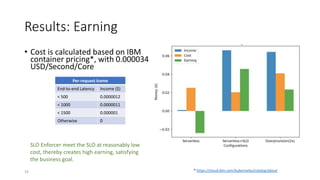
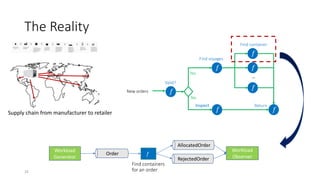
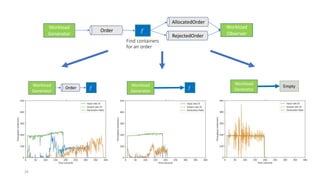
The document discusses service-level objectives (SLOs) and software-level agreements (SLAs) for serverless applications, emphasizing the importance of performance metrics in translating business goals into actionable implementations. It highlights the benefits of using serverless architectures, particularly with Kubernetes and Knative, to optimize resource management and enforce SLOs effectively. Future goals include improving SLO enforcement mechanisms and extending these concepts to broader serverless platforms.






































![[NGINX Webinar Forum] Tune health check parameter to reduce app down time slide](https://cdn.slidesharecdn.com/ss_thumbnails/tunehealth-checkparametertoreduceappdowntimeslide-211008040928-thumbnail.jpg?width=640&height=640&fit=bounds)









































