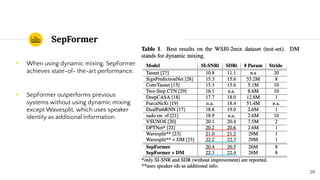
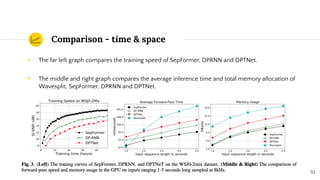
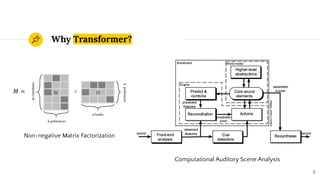
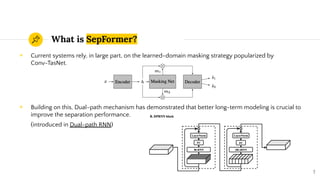
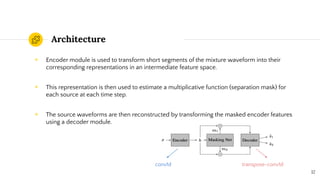
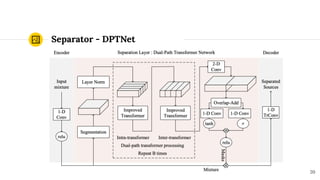
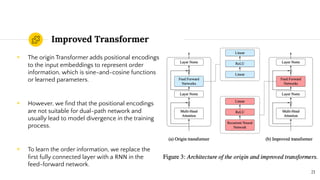
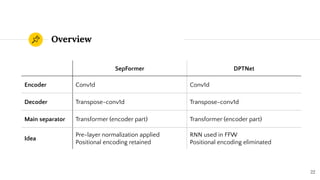
SepFormer and DPTNet are Transformer-based models for monaural speech separation that achieve state-of-the-art performance. SepFormer uses dual-path Transformers to model short and long-term dependencies without RNNs, allowing parallel processing. DPTNet introduces an improved Transformer with a recurrent layer to directly model contextual information in speech sequences. Experiments on standard datasets show SepFormer achieves SOTA results and is faster to train and infer than RNN baselines like DPRNN. Both models obtain competitive separation but SepFormer has advantages in parallelization and efficiency due to its RNN-free design.
![Speech Separation by Transformer:
SepFormer1
& DPTNet2
Presenter : 何冠勳 61047017s
Date : 2022/06/23
1: Neil Zeghidour, David Grangier, Published in arXiv:2010.13154v2 [eess.AS] 8 Mar 2021
2: Jingjing Chen, Qirong Mao, Dong Liu, Published in arXiv:2007.13975v3 [eess.AS] 14 Aug 2020](https://image.slidesharecdn.com/sepformerdptnet-220717043106-35df5d51/85/Sepformer-DPTNet-pdf-1-320.jpg)
![Speech Separation by Transformer:
SepFormer1
& DPTNet2
Presenter : 何冠勳 61047017s
Date : 2022/06/23
1: Neil Zeghidour, David Grangier, Published in arXiv:2010.13154v2 [eess.AS] 8 Mar 2021
2: Jingjing Chen, Qirong Mao, Dong Liu, Published in arXiv:2007.13975v3 [eess.AS] 14 Aug 2020](https://image.slidesharecdn.com/sepformerdptnet-220717043106-35df5d51/75/Sepformer-DPTNet-pdf-1-2048.jpg)













![Configurations - SepFormer
◉ Numbers of
○ Encoder basis 256 ; Kernel size 16 ; Chunk size 250 .
○ Transformers 8 ; SepFormer blocks 2 ; Attention heads 8 ; Dimension 1024 .
◉ We explored the use of dynamic mixing data augmentation which consists in on-the-fly creation of
new mixtures from single speaker sources, along with speed perturbation in [95%, 105%].
◉ Training process also apply learning rate halving, gradient clipping and mixed-precision.
◉ Mixed-precision training is a technique for substantially reducing neural net training time by
performing as many operations as possible in half-precision floating point, fp16, instead of the
single-precision floating point, fp32.
26](https://image.slidesharecdn.com/sepformerdptnet-220717043106-35df5d51/85/Sepformer-DPTNet-pdf-26-320.jpg)