Download as PDF, PPTX






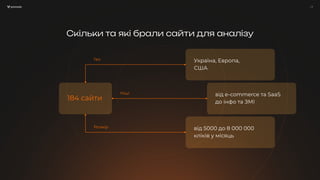
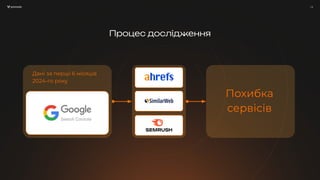

















Презентація Владислава Трішкіна з SEO-конференції Collaborator, що відбулася 11 жовтня 2024 року Тези дововіді: 1. Мета та методолія дослідження: як рахували, які показники порівнювали та навіщо взагалі взялися за цю роботу. 2. Відсоток похибки: сильні та слабкі сторони кожного з інструментів 3. Як прогнозувати трафік або обʼєм ніші власноруч, без використання даних з сервісів Про спікера: Владислав займається SEO більше 5-ти років. У портфелі проєктів: Ukr.net, Sinoptik, Concert.ua тощо. Полюбляє Ahrefs, зачитується керівництвом для асесорів Google та завжди готовий подискутувати з питань SEO. Його основна спеціалізація: просування контентних та медіа проєктів, має велику кількість успішних кейсів.















































