مقاالت
1. Large-scale experimentalevaluation of GPU
strategies for evolutionary machine learning
María A. Franco, Jaume Bacardit
2016 Elsevier B.V. All rights reserved
2. Improving the scalability of rule-based
evolutionary learning
Jaume Bacardit, Edmund K. Burke, Natalio Krasnogor
2009
2
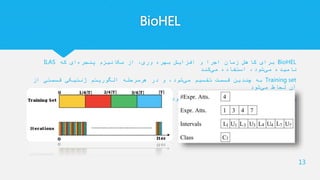
BioHEL
Procedure BioHEL generalworkflow
Input : TrainingSet
RuleSet = ∅
stop = false
Do
BestRule = null
For repetition=1 to NumRepetitionsRuleLearning
CandidateRule = RunGA(TrainingSet)
If CandidateRule is better than BestRule
BestRule = CandidateRule
EndIf
EndFor
Matched = Examples from TrainingSet matched by BestRule
If class of BestRule is the majority class in Matched
Remove Matched from TrainingSet
Add BestRule to RuleSet
Else
stop = true
EndIf
While stop is false
Output : RuleSet
9
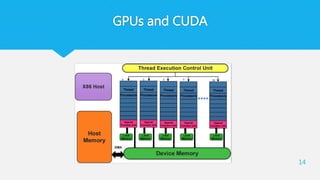
types of memoryin CUDA
Device mem
Texture
mem
Shared mem بینThreadیک هایBlockاست مشترک
Constant
mem
توسط فقطHostاست نوشتن قابل
Local thread
mem
هر مخصوصThread
16
Experimental design
Intel(R)Core(TM) i7 CPU
8 cores
3.07 GHz
12 GB of RAM
Tesla C2070
6 GB of internal memory
448 CUDA cores
14 multiprocessors x 32 CUDA Cores/MP
25
Experimental design
Pentium4
3.6 GHz
hyper-threading
2 GB of RAM
Tesla C1060
4 GB of global memory
30 multiprocessors
27
28.
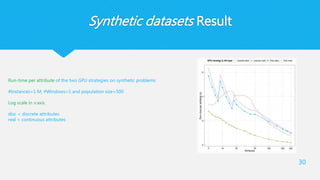
Synthetic datasets Result
28
Run-timeof the two GPU strategies on
synthetic problems
#Windows=1 and population size=500
Log scale is used for both axis
disc = discrete attributes
real = continuous attributes
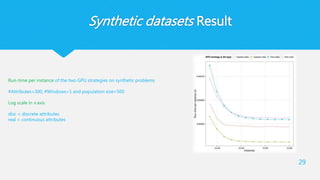
29.
Synthetic datasets Result
29
Run-timeper instance of the two GPU strategies on synthetic problems
#Attributes=300, #Windows=1 and population size=500
Log scale in x axis
disc = discrete attributes
real = continuous attributes
30.
Synthetic datasets Result
30
Run-timeper attribute of the two GPU strategies on synthetic problems
#Instances=1 M, #Windows=1 and population size=500
Log scale in x axis
disc = discrete attributes
real = continuous attributes
31.
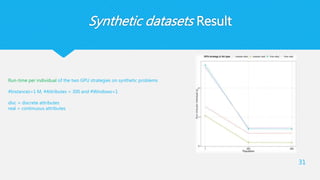
Synthetic datasets Result
31
Run-timeper individual of the two GPU strategies on synthetic problems
#Instances=1 M, #Attributes = 300 and #Windows=1
disc = discrete attributes
real = continuous attributes
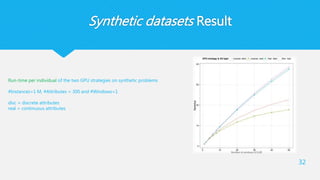
32.
Synthetic datasets Result
32
Run-timeper individual of the two GPU strategies on synthetic problems
#Instances=1 M, #Attributes = 300 and #Windows=1
disc = discrete attributes
real = continuous attributes
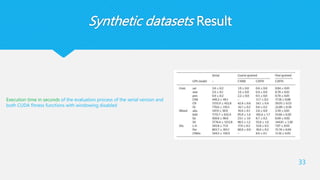
33.
Synthetic datasets Result
33
Executiontime in seconds of the evaluation process of the serial version and
both CUDA fitness functions with windowing disabled
34.
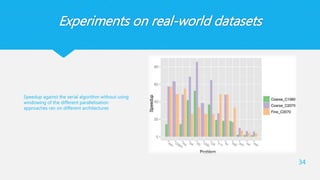
Experiments on real-worlddatasets
34
Speedup against the serial algorithm without using
windowing of the different parallelisation
approaches ran on different architectures
35.
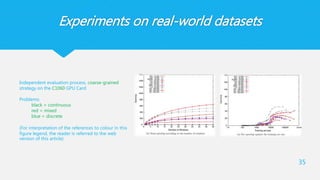
Experiments on real-worlddatasets
35
Independent evaluation process, coarse-grained
strategy on the C1060 GPU Card
Problems:
black = continuous
red = mixed
blue = discrete
(For interpretation of the references to colour in this
figure legend, the reader is referred to the web
version of this article)
36.
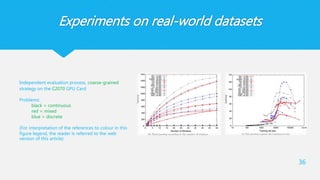
Experiments on real-worlddatasets
36
Independent evaluation process, coarse-grained
strategy on the C2070 GPU Card
Problems:
black = continuous
red = mixed
blue = discrete
(For interpretation of the references to colour in this
figure legend, the reader is referred to the web
version of this article)
37.
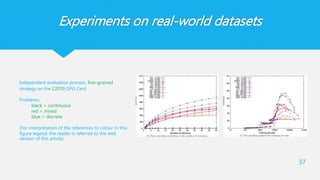
Experiments on real-worlddatasets
37
Independent evaluation process, fine-grained
strategy on the C2070 GPU Card
Problems:
black = continuous
red = mixed
blue = discrete
(For interpretation of the references to colour in this
figure legend, the reader is referred to the web
version of this article)