Download as PDF, PPTX






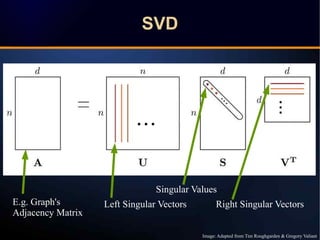
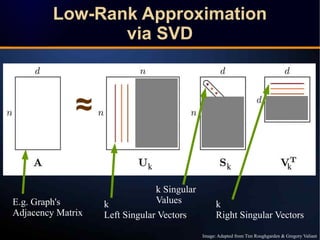
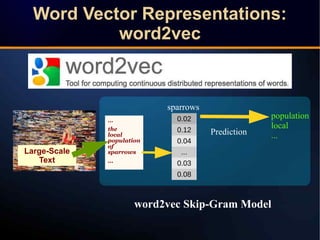
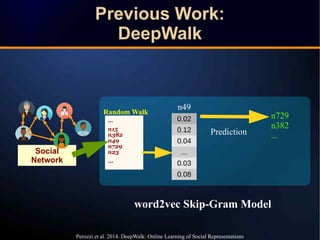



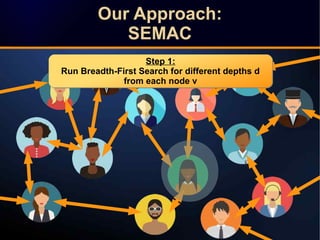

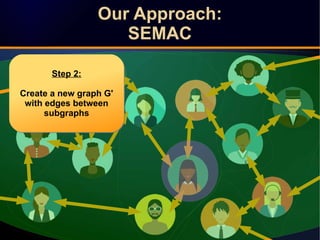
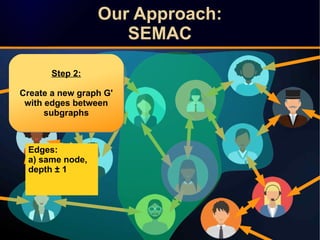

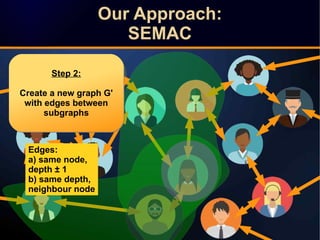



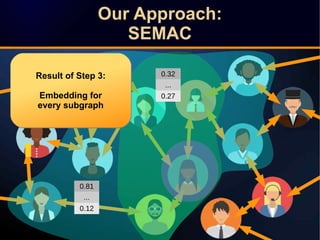
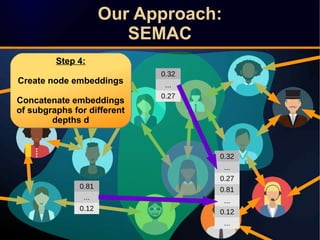








The document discusses a novel approach to link prediction through subgraph embedding and convex matrix completion, referred to as SEMAC. This method includes creating a new graph based on breadth-first search, learning subgraph embeddings, and using nuclear norm minimization for better accuracy in predicting connections. Results from various experiments on social networks, including Facebook and Wikipedia, indicate that SEMAC achieves state-of-the-art performance in link prediction tasks.
























![240506_JW_labseminar[Structural Deep Network Embedding].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240506jwlabseminarstructuraldeepnetworkembedding-240507042150-61ba62d3-thumbnail.jpg?width=640&height=640&fit=bounds)

![240408_JW_labseminar[Asymmetric Transitivity Preserving Graph Embedding].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240408jwlabseminarasymmetrictransitivitypreservinggraphembedding-240408122410-484bfecf-thumbnail.jpg?width=640&height=640&fit=bounds)


































