Downloaded 117 times


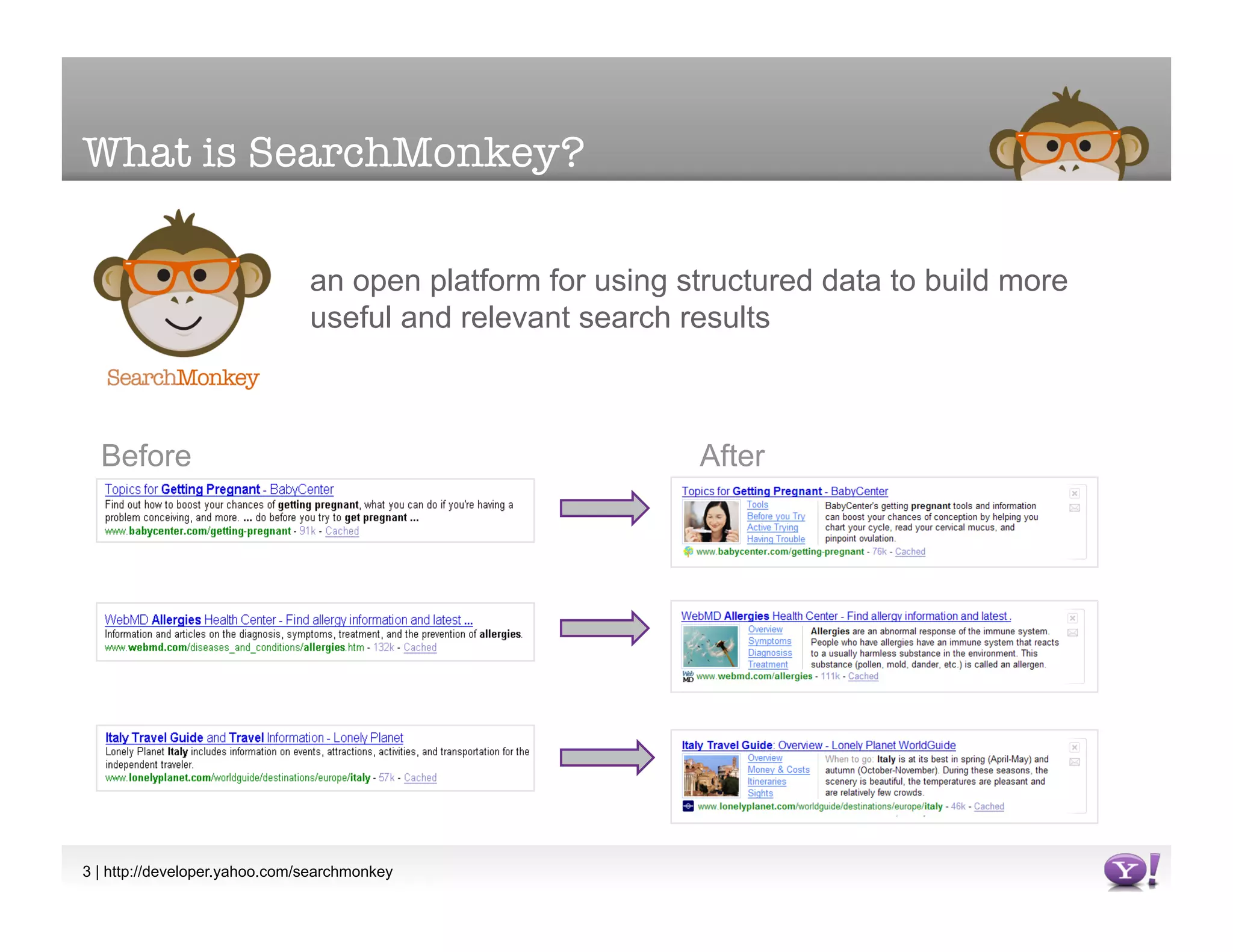


















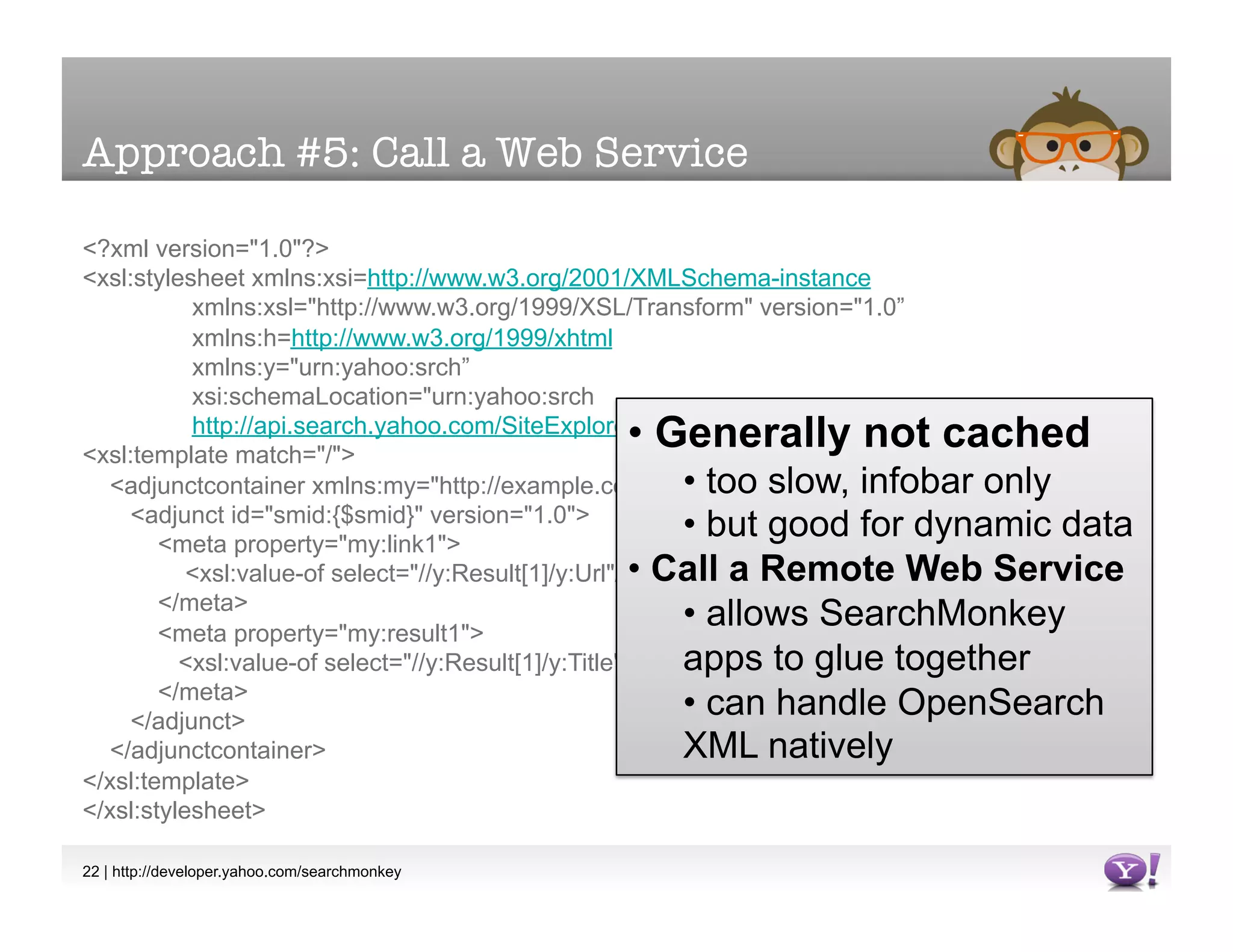




















The document discusses SearchMonkey, an open platform from Yahoo! that allows developers to build structured data into search results. It presents several approaches for providing structured data to SearchMonkey, including embedding RDF or microformats directly into web pages, generating a DataRSS feed from a database, extracting data via XSLT, or calling a remote web service. The document encourages developers to prototype with XSLT initially and provides resources for learning more about SearchMonkey and structured data standards.









































































