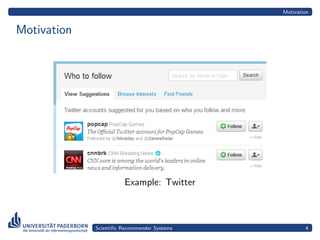
The document provides an overview of scientific recommender systems, detailing their motivation, categories, and implementations. It covers content-based, collaborative, and hybrid recommender systems, illustrating concepts with examples like Apache Mahout and SciPlore. Additionally, it discusses challenges in these systems and concludes with potential visualizations and references for further reading.