Download as PDF, PPTX



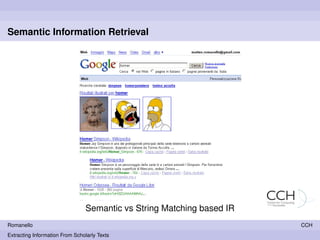












1) The document describes a project to develop an automatic system to extract semantic information from unstructured scholarly texts in classics, focusing on named entities and references. 2) The goal is to build knowledge bases integrating information from multiple sources to improve information retrieval over a classics corpus. 3) The project involves building corpora from online archives, processing texts to extract entities and references, and developing techniques to recognize canonical and bibliographic references.
![[poster] Extracting Information From Classics Scholarly Texts](https://cdn.slidesharecdn.com/ss_thumbnails/cameraready-100126051443-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)























































