Download to read offline














![Vrije Universiteit Amsterdam
22
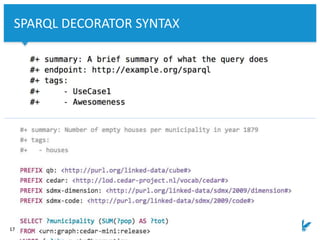
ENUMERATIONS & DROPDOWNS
• Fills in the
swag[paths][op][method][
parameters][enum] array
• Uses the triple pattern of
the SPARQL query’s BGP
against the same SPARQL
endpoint](https://image.slidesharecdn.com/grlc-dans-20170501-170501192859/85/Repeatable-Semantic-Queries-for-the-Linked-Data-Agnostic-22-320.jpg)










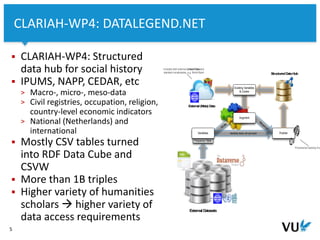
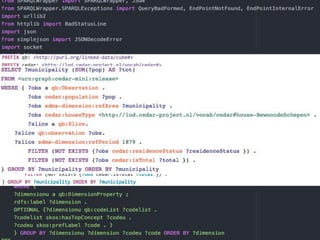
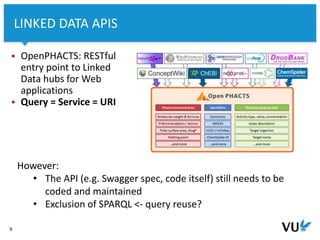
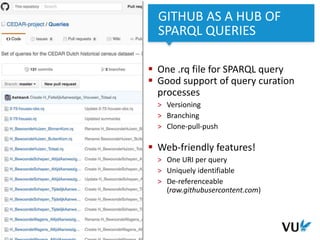
The document discusses the development of repeatable semantic queries for linked data, focusing on the challenges of integrating RDF data and SPARQL queries into web applications. It introduces tools like grlc, which provide a RESTful interface for accessing linked data, allowing for easier management and reuse of queries through GitHub. Additionally, it highlights the potential of these methods for social historians and data curation workflows, emphasizing the need for web-friendly access to structured data.

















































































