Download as PDF, PPTX














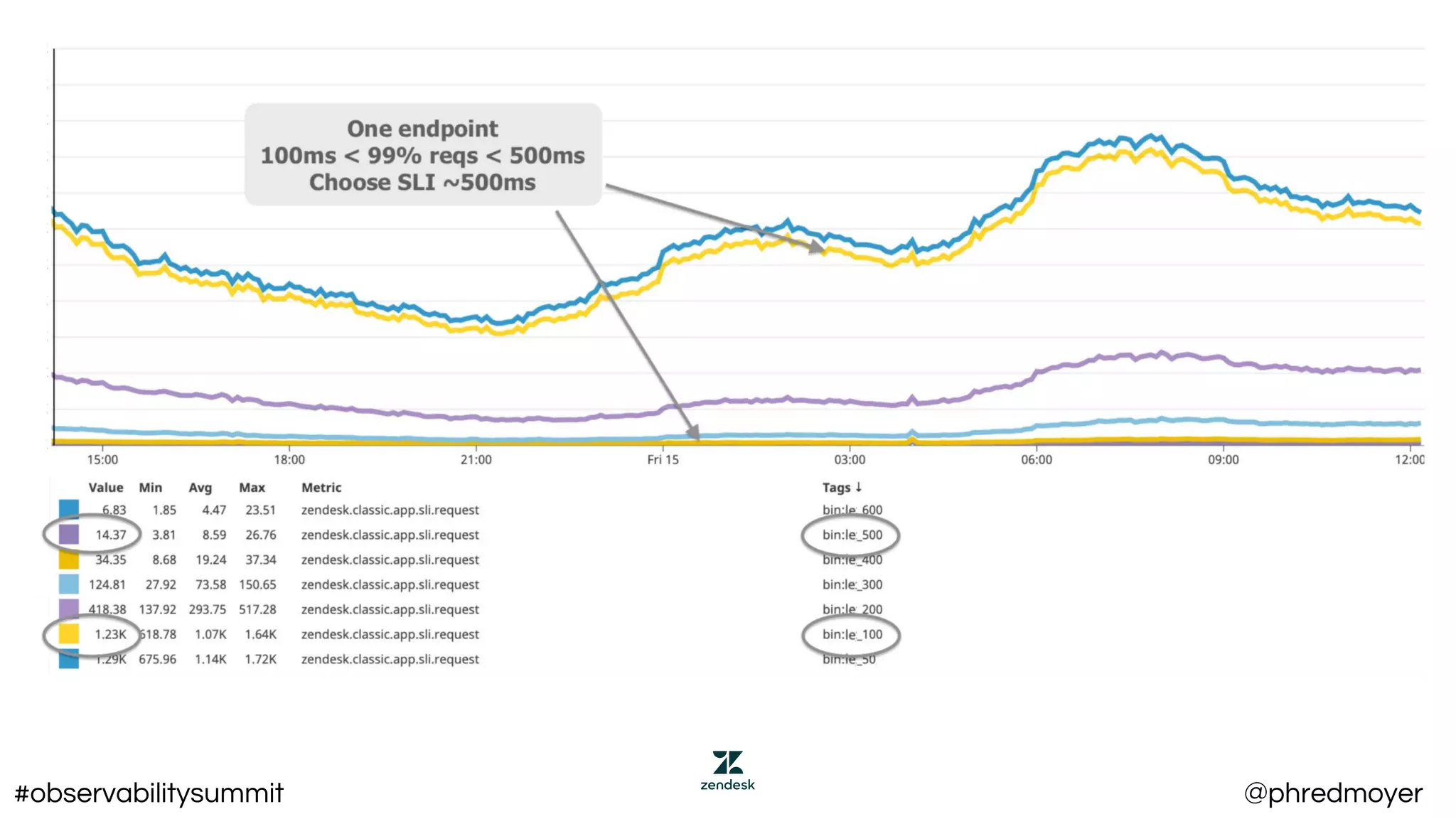
![95th percentile home page latency over 5
minutes < 500ms
Home page request response code != 5xx
Home page request served in < 100ms
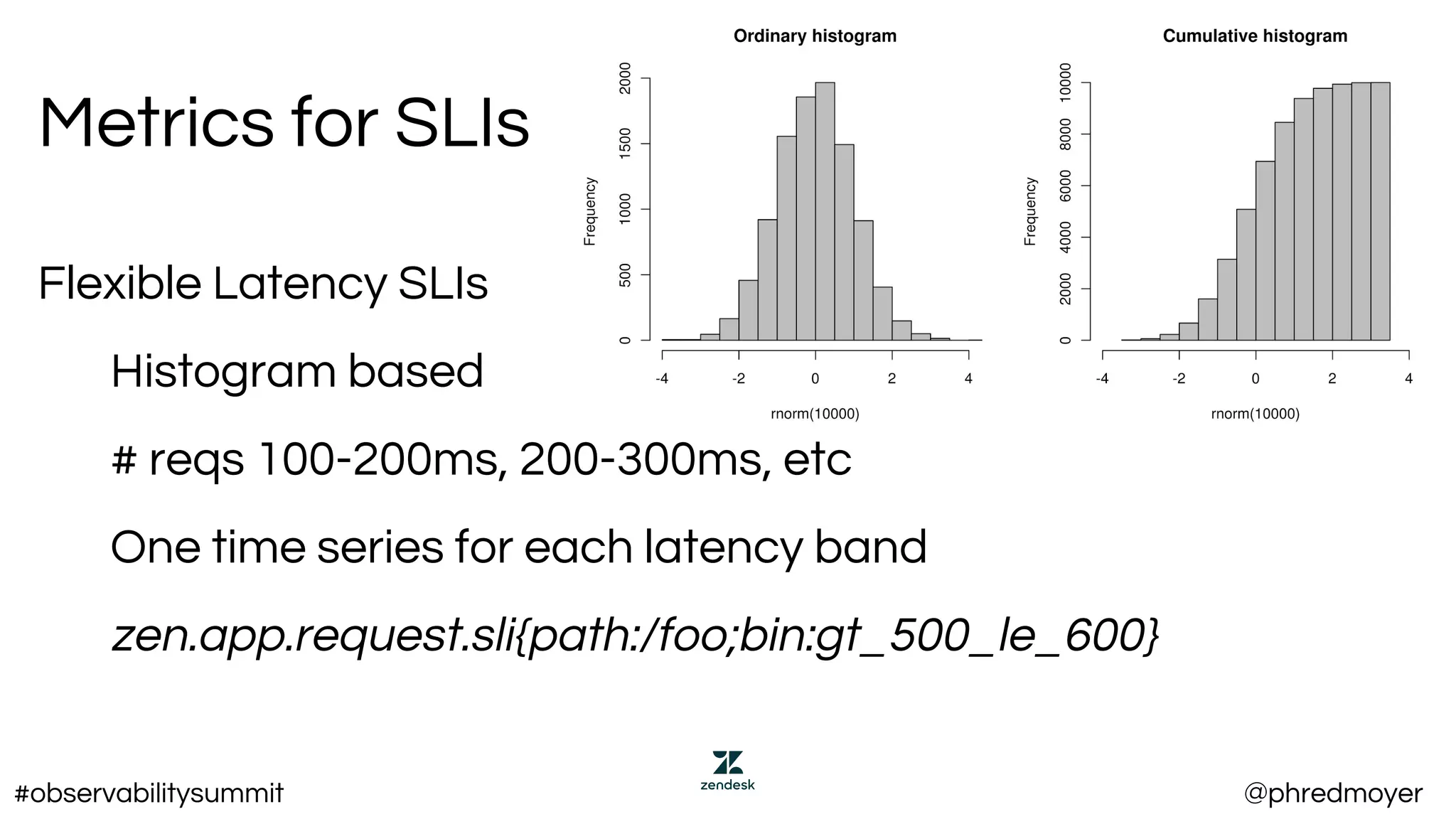
Metric Identifier
[Metric Identifier] [Operator] [Metric Value]
EXAMPLE SLIS
#observabilitysummit @phredmoyer](https://image.slidesharecdn.com/reliableobservabilityatscale-200408165930/75/Reliable-observability-at-scale-Error-Budgets-for-1-000-21-2048.jpg)
![95th percentile home page latency over 5
minutes < 500ms
Home page request response code != 5xx
Homepage request served in < 100ms
Operator
[Metric Identifier] [Operator] [Metric Value]
EXAMPLE SLIS
#observabilitysummit @phredmoyer](https://image.slidesharecdn.com/reliableobservabilityatscale-200408165930/75/Reliable-observability-at-scale-Error-Budgets-for-1-000-22-2048.jpg)
![95th percentile home page latency over 5
minutes < 500ms
Home page request response code != 5xx
Home page request served in < 100ms
Metric Value
[Metric Identifier] [Operator] [Metric Value]
EXAMPLE SLIS
#observabilitysummit @phredmoyer](https://image.slidesharecdn.com/reliableobservabilityatscale-200408165930/75/Reliable-observability-at-scale-Error-Budgets-for-1-000-23-2048.jpg)
![95th percentile home page latency over 5
minutes < 500ms
Home page request response code != 5xx
Home page request served in < 100ms
[Metric Identifier] [Operator] [Metric Value]
EXAMPLE SLIS
#observabilitysummit @phredmoyer](https://image.slidesharecdn.com/reliableobservabilityatscale-200408165930/75/Reliable-observability-at-scale-Error-Budgets-for-1-000-24-2048.jpg)



![[Success Objective] [SLI] [Period]
Success Objective
99% of 95th percentile home page latency
over 5 minutes < 500ms over the trailing
month
99% of home page request response code
!= 5xx over last 7 days
95% of home page requests served in <
100ms over last 24 hours
EXAMPLE SLOS
#observabilitysummit @phredmoyer](https://image.slidesharecdn.com/reliableobservabilityatscale-200408165930/75/Reliable-observability-at-scale-Error-Budgets-for-1-000-28-2048.jpg)
![EXAMPLE SLOS
[Success Objective] [SLI] [Period]
SLI
99% of 95th percentile home page latency
over 5 minutes < 500ms over the trailing
month
99% of home page request response code
!= 5xx over last 7 days
95% of home page requests served in <
100ms over last 24 hours
#observabilitysummit @phredmoyer](https://image.slidesharecdn.com/reliableobservabilityatscale-200408165930/75/Reliable-observability-at-scale-Error-Budgets-for-1-000-29-2048.jpg)
![EXAMPLE SLOS
99% of 95th percentile home page latency
over 5 minutes < 500ms over the trailing
month
99% of home page request response code
!= 5xx over last 7 days
95% of home page requests served in <
100ms over last 24 hours
[Success Objective] [SLI] [Period]
Period
#observabilitysummit @phredmoyer](https://image.slidesharecdn.com/reliableobservabilityatscale-200408165930/75/Reliable-observability-at-scale-Error-Budgets-for-1-000-30-2048.jpg)
![EXAMPLE SLOS
99% of 95th percentile home page latency
over 5 minutes < 500ms over the trailing
month
99% of home page request response code
!= 5xx over last 7 days
95% of home page requests served in <
100ms over last 24 hours
[Success Objective] [SLI] [Period]
#observabilitysummit @phredmoyer](https://image.slidesharecdn.com/reliableobservabilityatscale-200408165930/75/Reliable-observability-at-scale-Error-Budgets-for-1-000-31-2048.jpg)



![EXAMPLE EBS
Allow 1% failure of 95th percentile home
page latency over 5 minutes < 500ms over
the trailing month
Allow 1% failure of home page request
response code != 5xx over last 7 days
Allow 5% failure of home page requests
served in < 100ms over last 24 hours
[Error Budget] [SLI] [Period]
Error Budget
#observabilitysummit @phredmoyer](https://image.slidesharecdn.com/reliableobservabilityatscale-200408165930/75/Reliable-observability-at-scale-Error-Budgets-for-1-000-35-2048.jpg)
![EXAMPLE EBS
Allow 1% failure of 95th percentile home
page latency over 5 minutes < 500ms over
the trailing month
Allow 1% failure of home page request
response code != 5xx over last 7 days
Allow 5% failure of home page requests
served in < 100ms over last 24 hours
[Error Budget] [SLI] [Period]
SLI
#observabilitysummit @phredmoyer](https://image.slidesharecdn.com/reliableobservabilityatscale-200408165930/75/Reliable-observability-at-scale-Error-Budgets-for-1-000-36-2048.jpg)
![EXAMPLE EBS
Allow 1% failure of 95th percentile home
page latency over 5 minutes < 500ms over
the trailing month
Allow 1% failure of home page request
response code != 5xx over last 7 days
Allow 5% failure of home page requests
served in < 100ms over last 24 hours
[Error Budget] [SLI] [Period]
Period
#observabilitysummit @phredmoyer](https://image.slidesharecdn.com/reliableobservabilityatscale-200408165930/75/Reliable-observability-at-scale-Error-Budgets-for-1-000-37-2048.jpg)
![EXAMPLE EBS
Allow 1% failure of 95th percentile home
page latency over 5 minutes < 500ms over
the trailing month
Allow 1% failure of home page request
response code != 5xx over last 7 days
Allow 5% failure of home page requests
served in < 100ms over last 24 hours
[Error Budget] [SLI] [Period]
#observabilitysummit @phredmoyer](https://image.slidesharecdn.com/reliableobservabilityatscale-200408165930/75/Reliable-observability-at-scale-Error-Budgets-for-1-000-38-2048.jpg)



![Lots of teams; lots of tools
Metrics: Prometheus / StatsD => Datadog
Logs: JSON => [ ELK, Datadog, AWS ]
APM: Datadog
Network: [ Datadog, ThousandEyes ]
Distributed Tracing: WIP
#observabilitysummit @phredmoyer](https://image.slidesharecdn.com/reliableobservabilityatscale-200408165930/75/Reliable-observability-at-scale-Error-Budgets-for-1-000-42-2048.jpg)









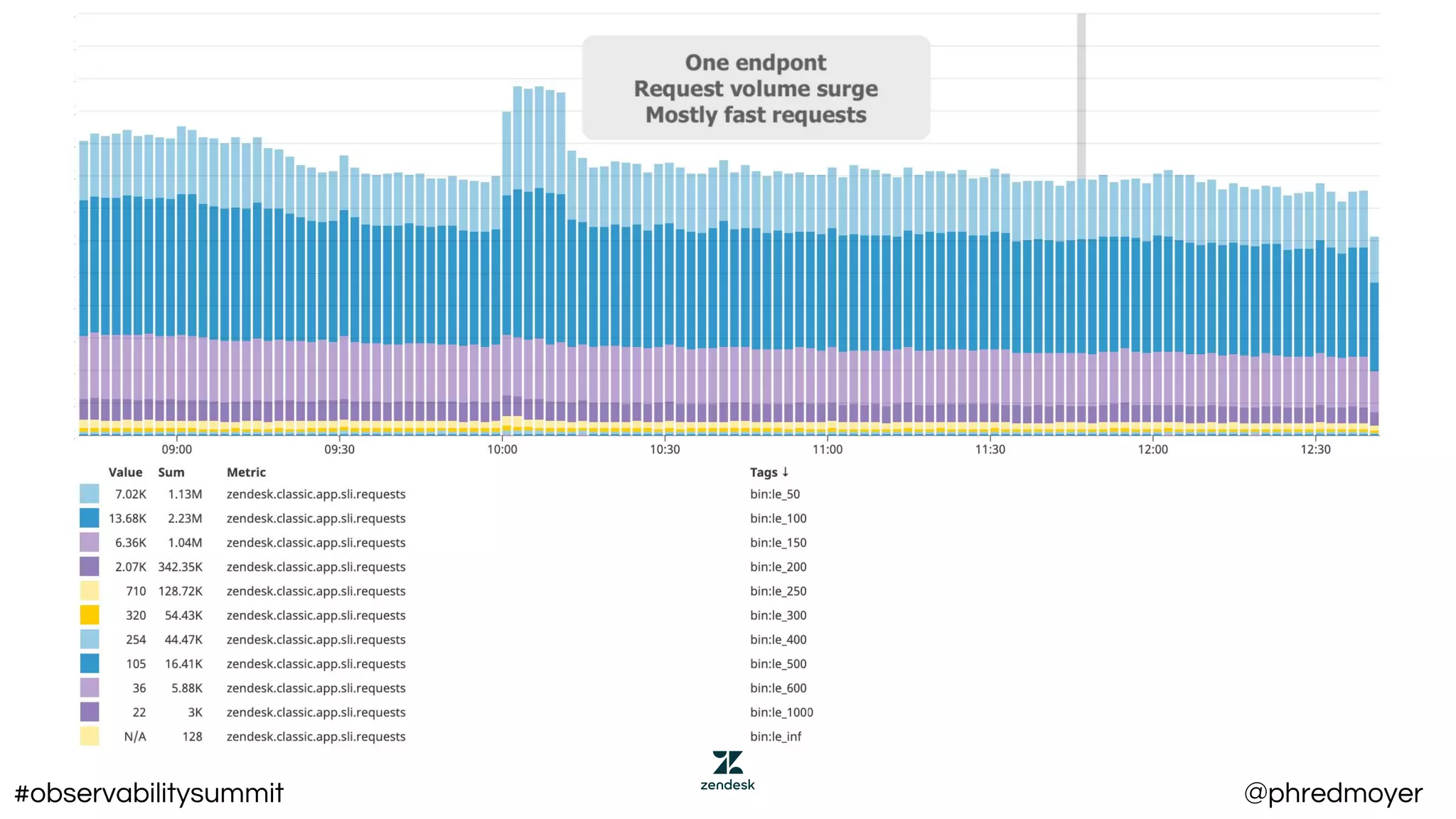

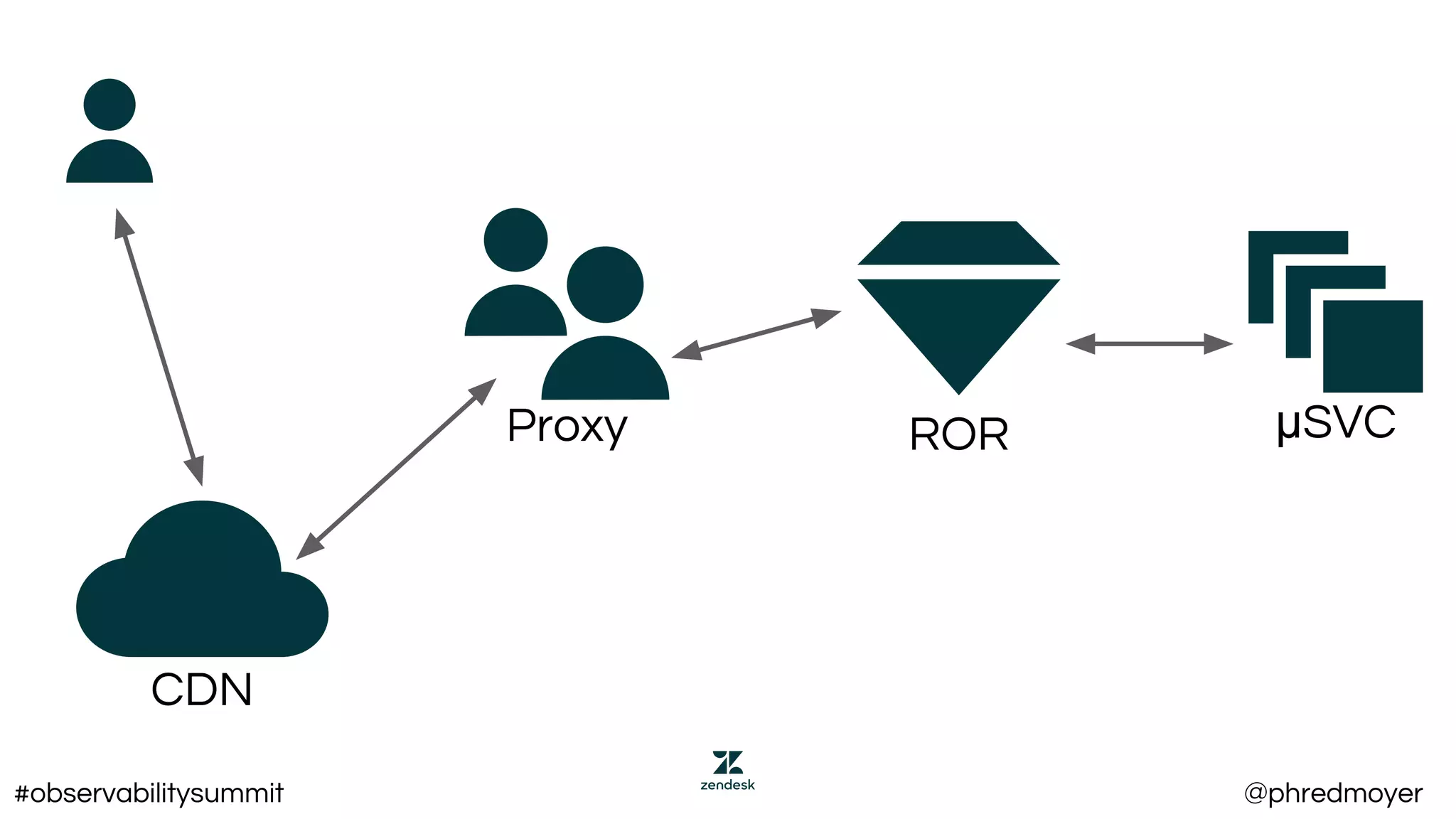
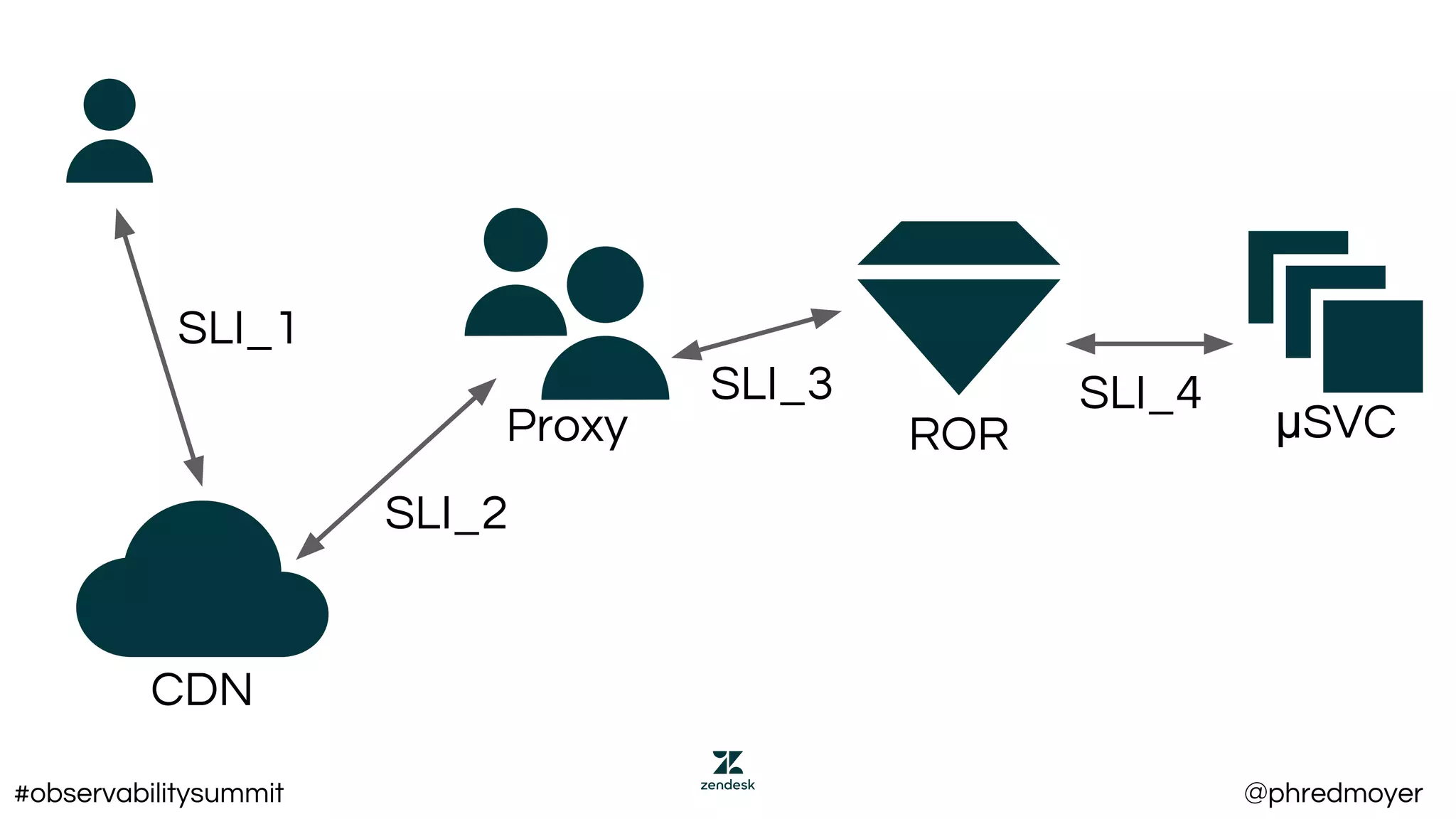
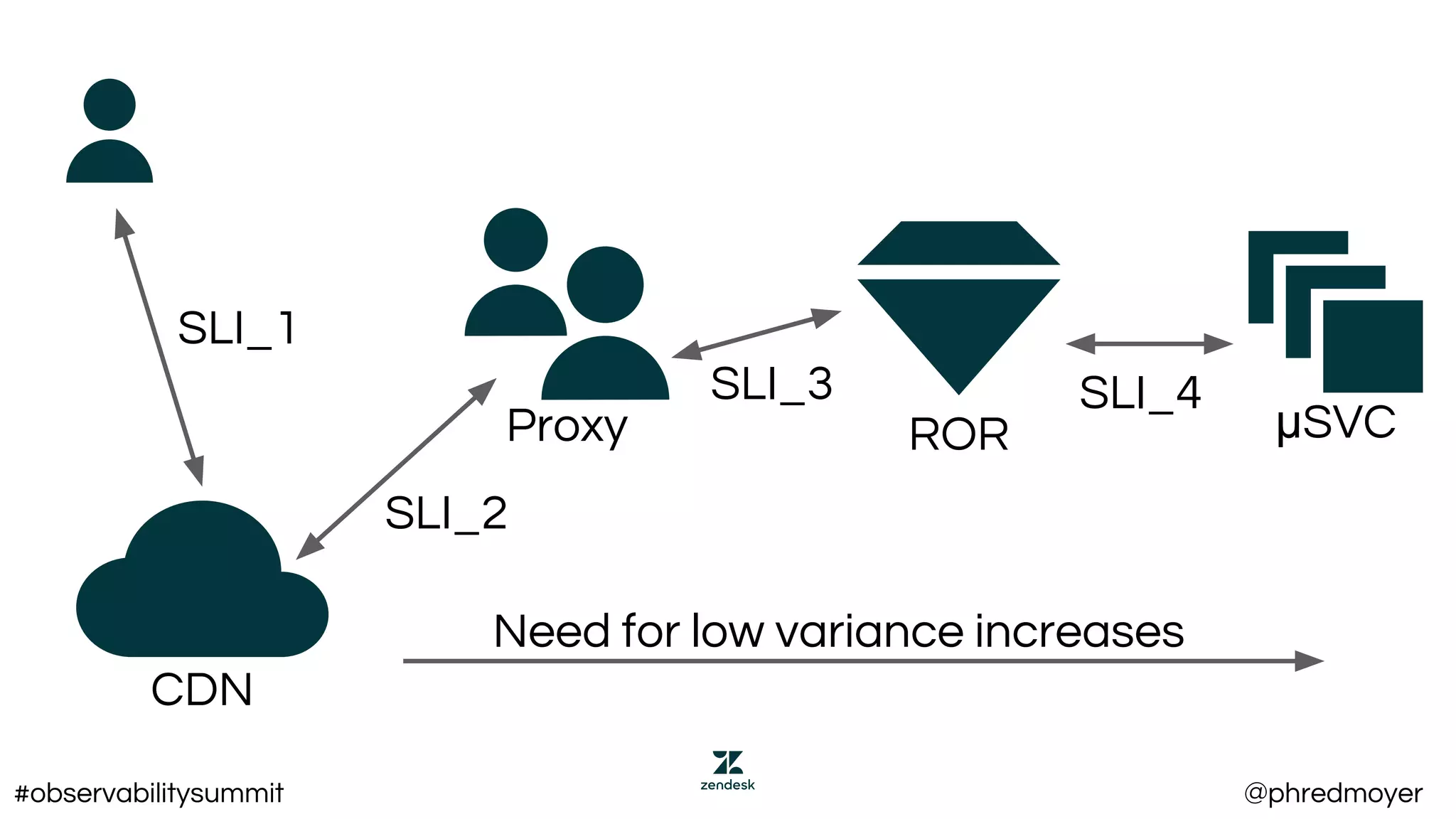

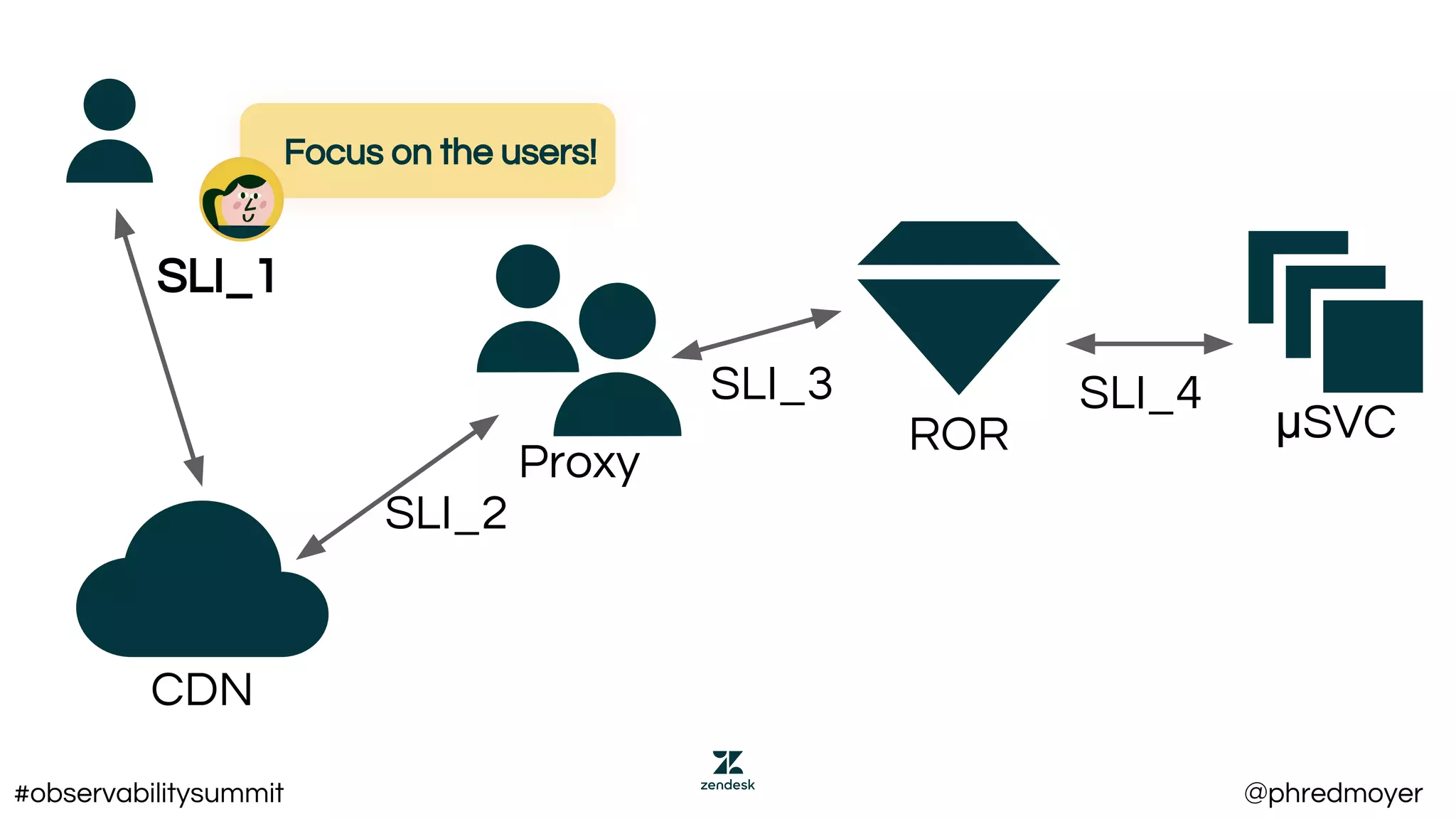




This document summarizes a presentation about implementing service level objectives (SLOs) and error budgets at scale. It discusses establishing service level indicators (SLIs) to define good and bad service, setting SLOs as targets for SLIs over time periods, and calculating error budgets as the complement of SLOs. The presentation provides examples of SLIs, SLOs, and error budgets for latency and availability. It also discusses challenges including variance from real users and different stakeholders' needs, and recommends approaches like flexible latency metrics and measuring as close to users as possible.







































































