Downloaded 16 times







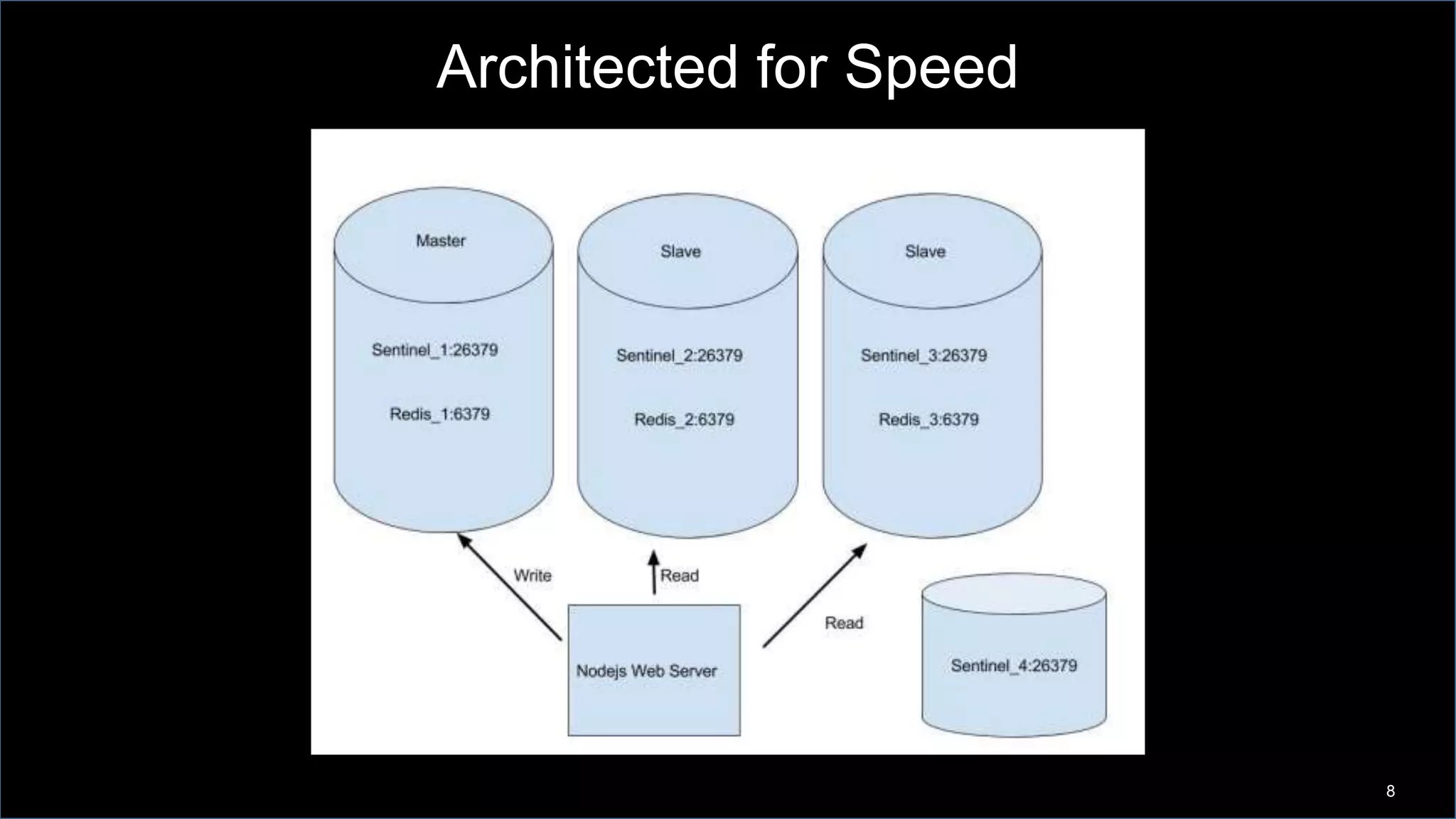














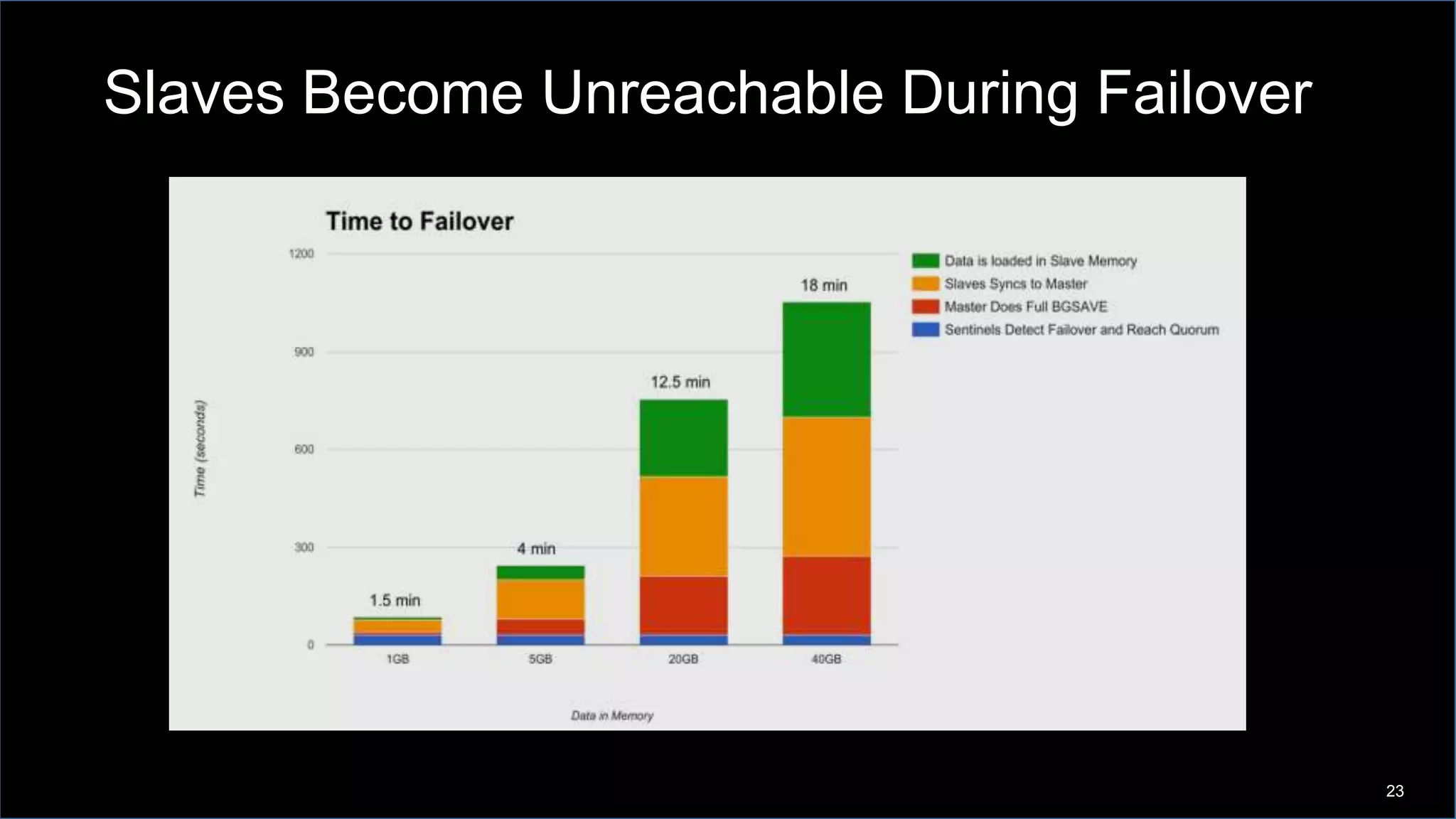




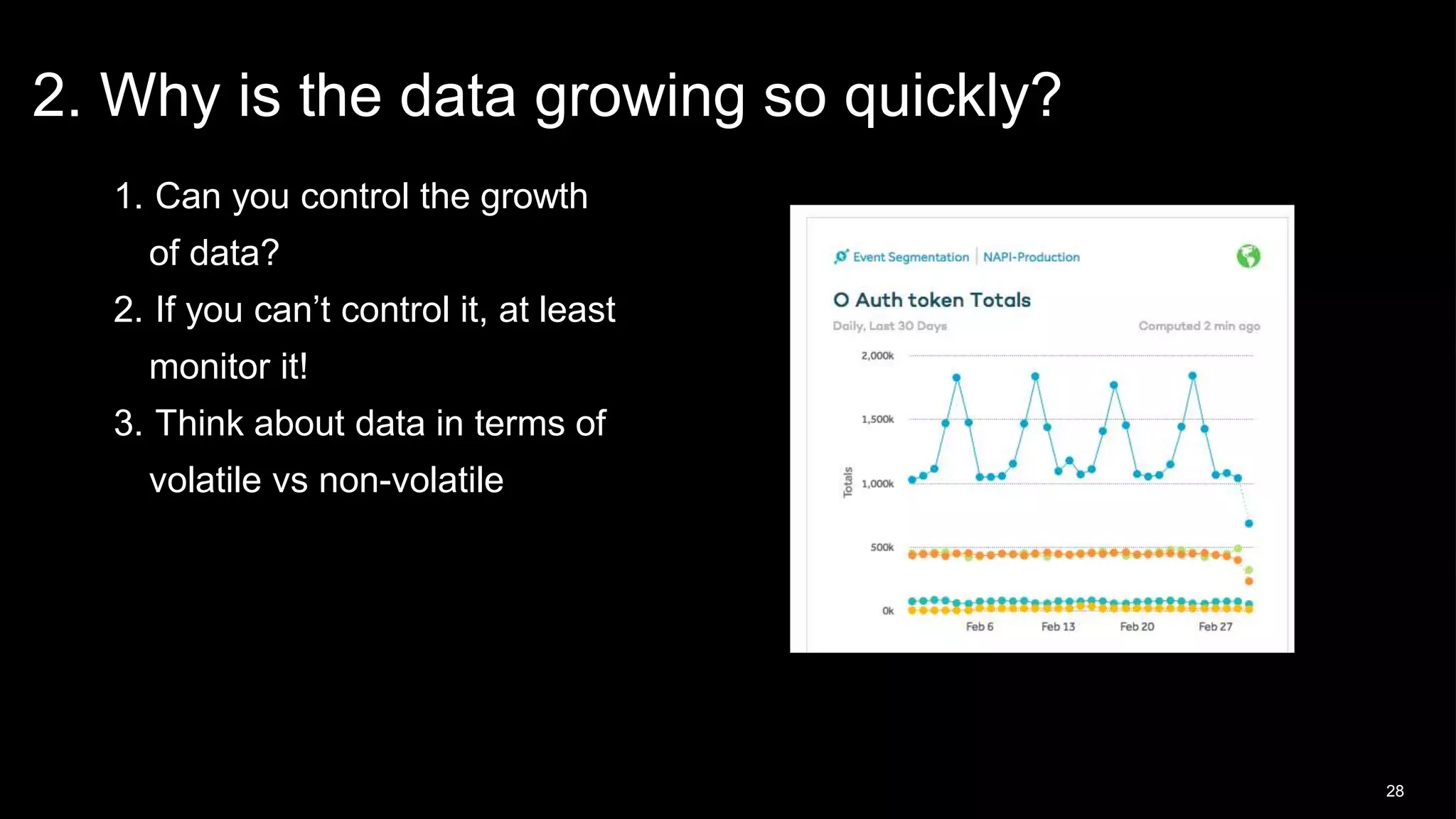




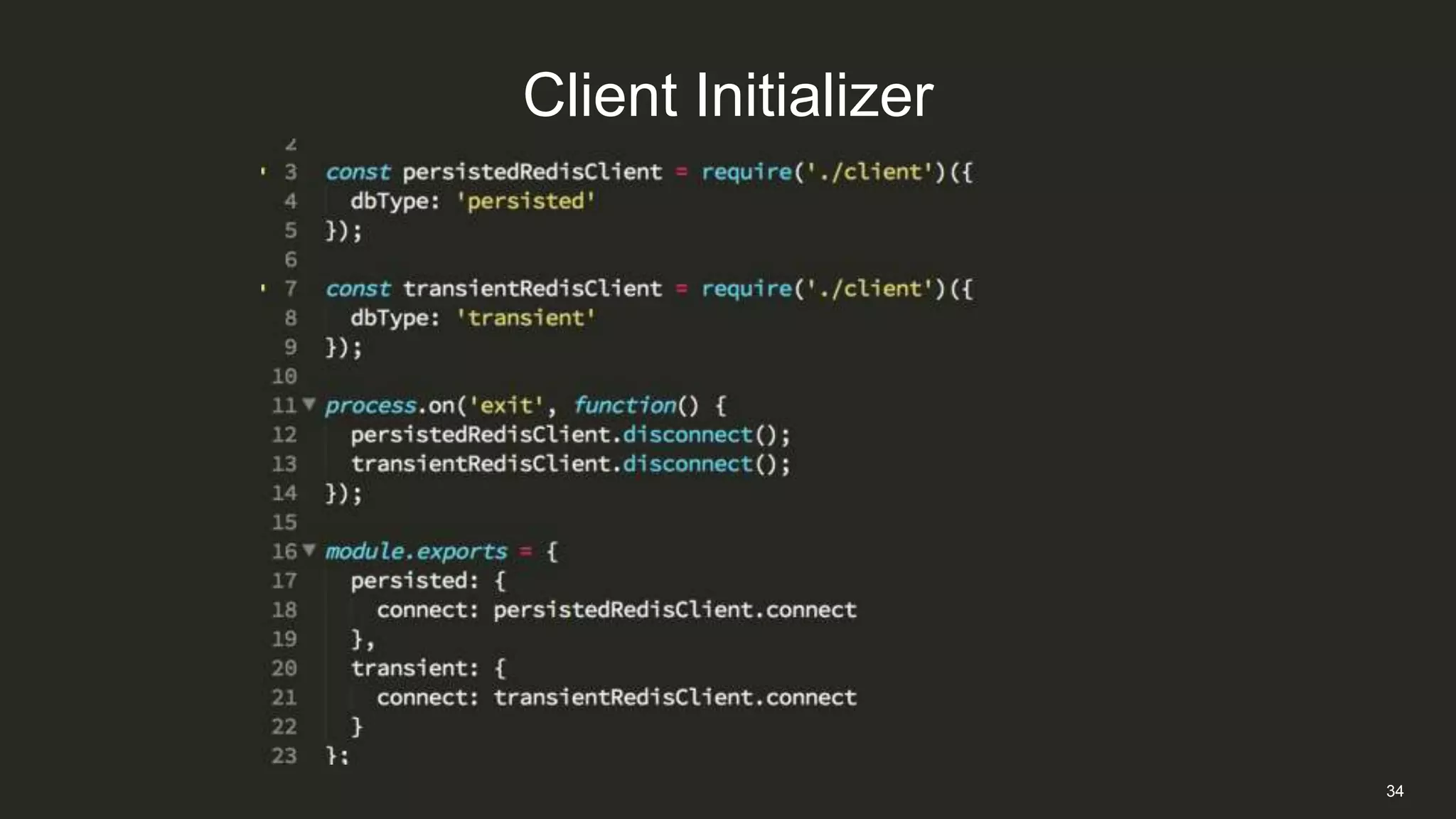
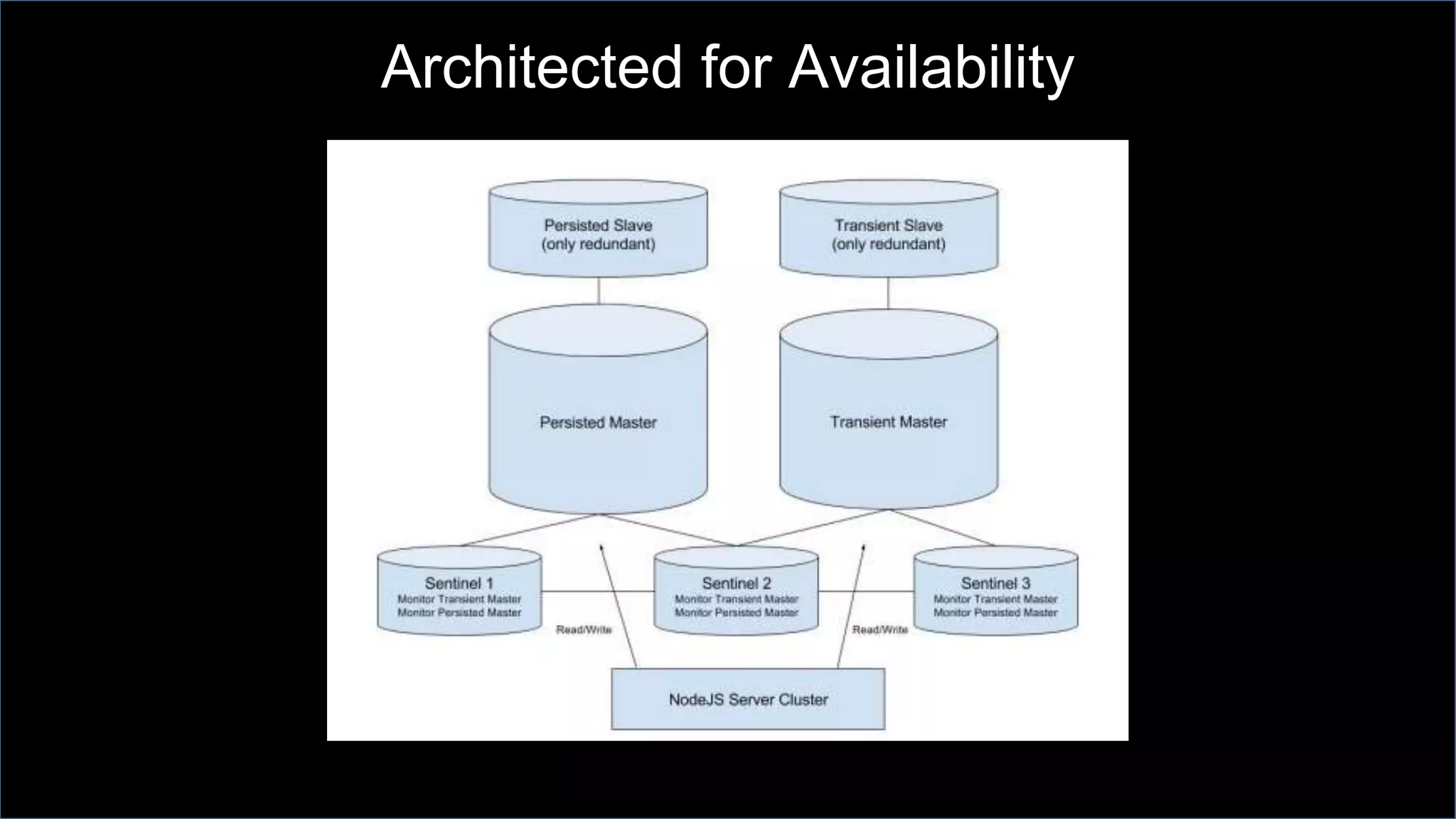



This document discusses Napster's use of Redis for caching and the problems they encountered with Redis failover at scale. As Napster's Redis data grew to tens of gigabytes, failover times increased to over 15 minutes, disrupting their API services. Napster addressed this by implementing connection pooling with ioredis to better handle connections during failovers, configuring Redis for availability rather than consistency, and architecting their systems to gracefully handle temporary Redis outages.






















![[En] IPVS for Docker Containers](https://cdn.slidesharecdn.com/ss_thumbnails/ipvsdockerconeu2015-fullversion-151119045345-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)






























































