Download as PDF, PPTX






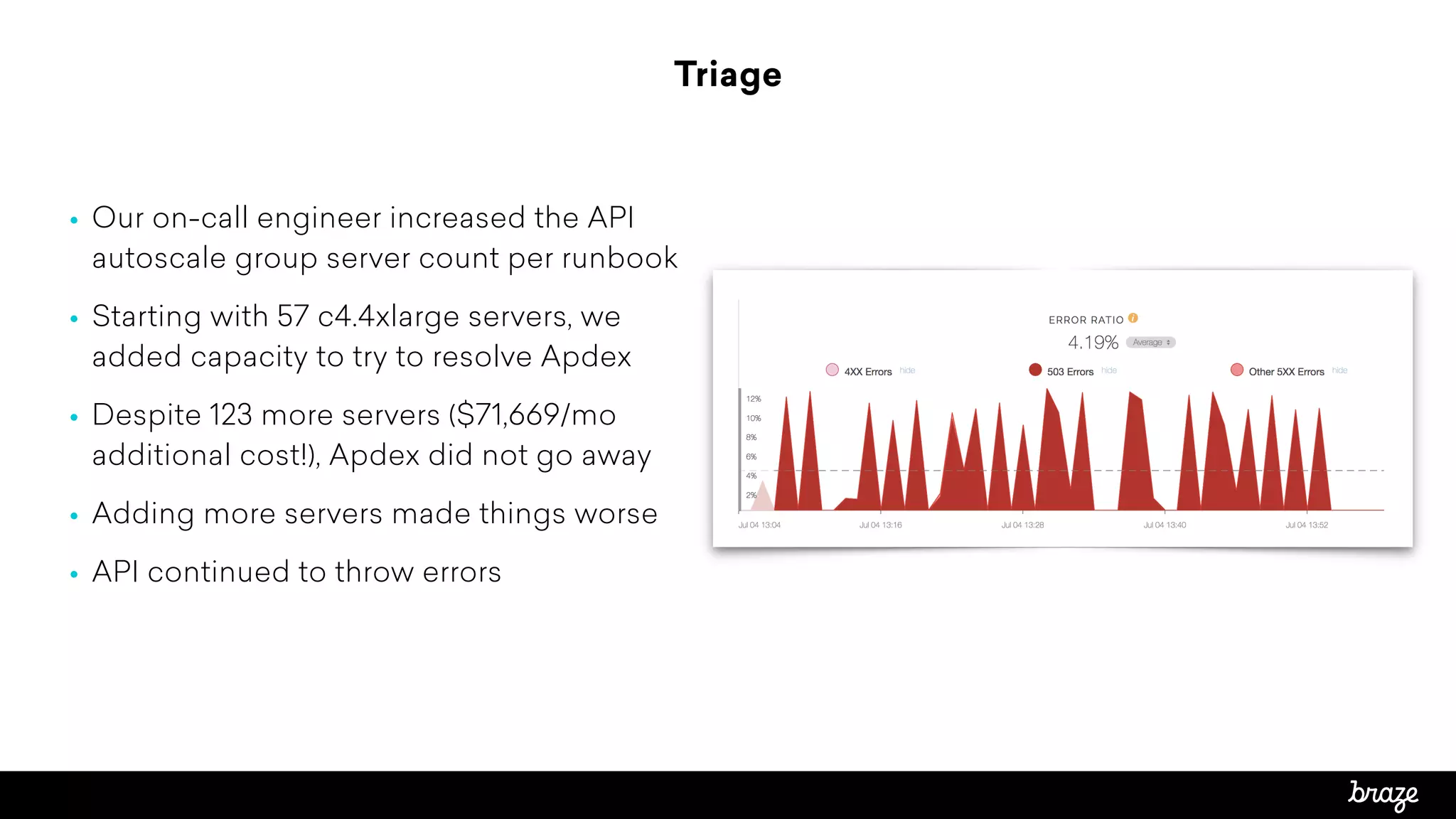
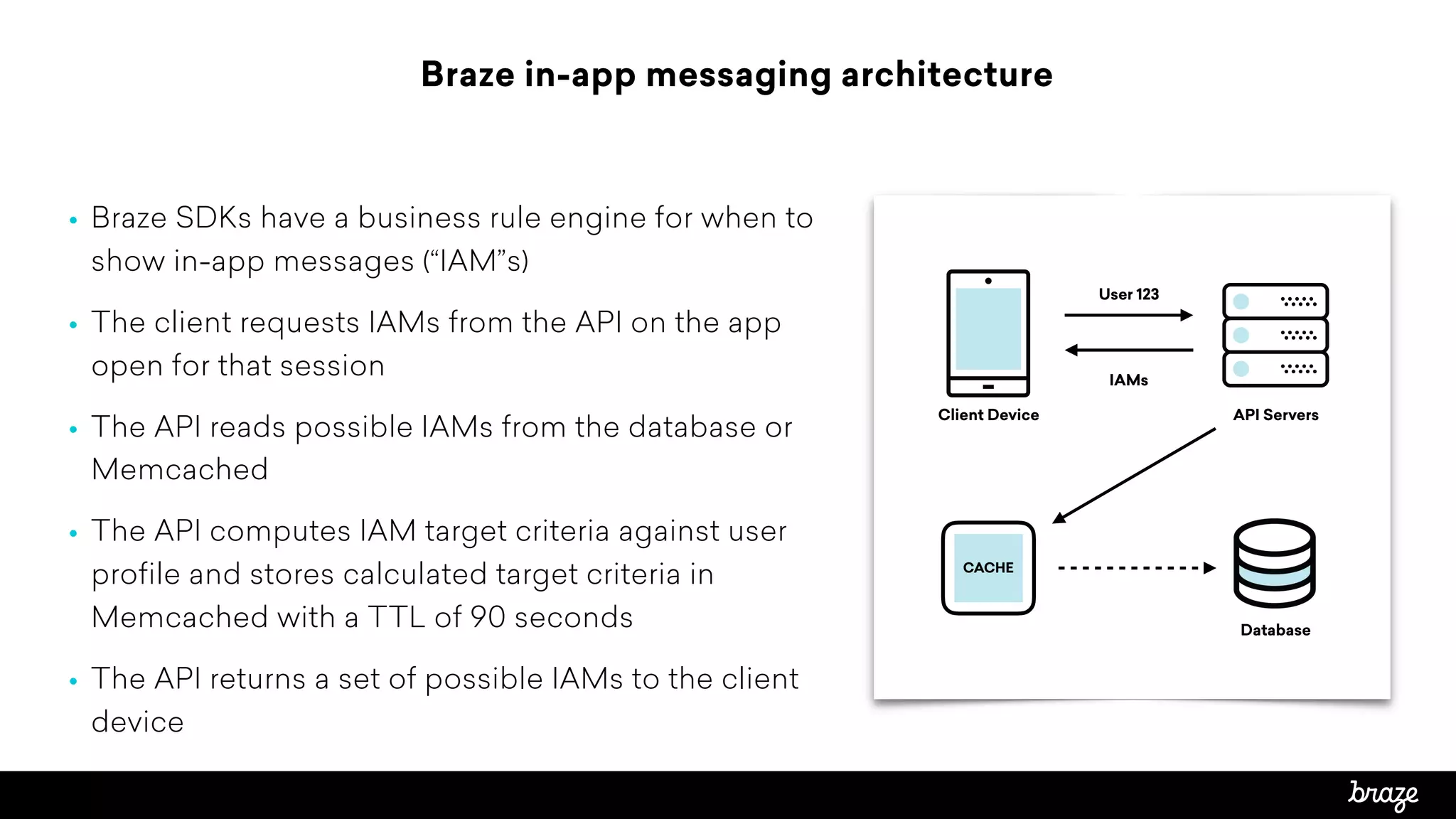






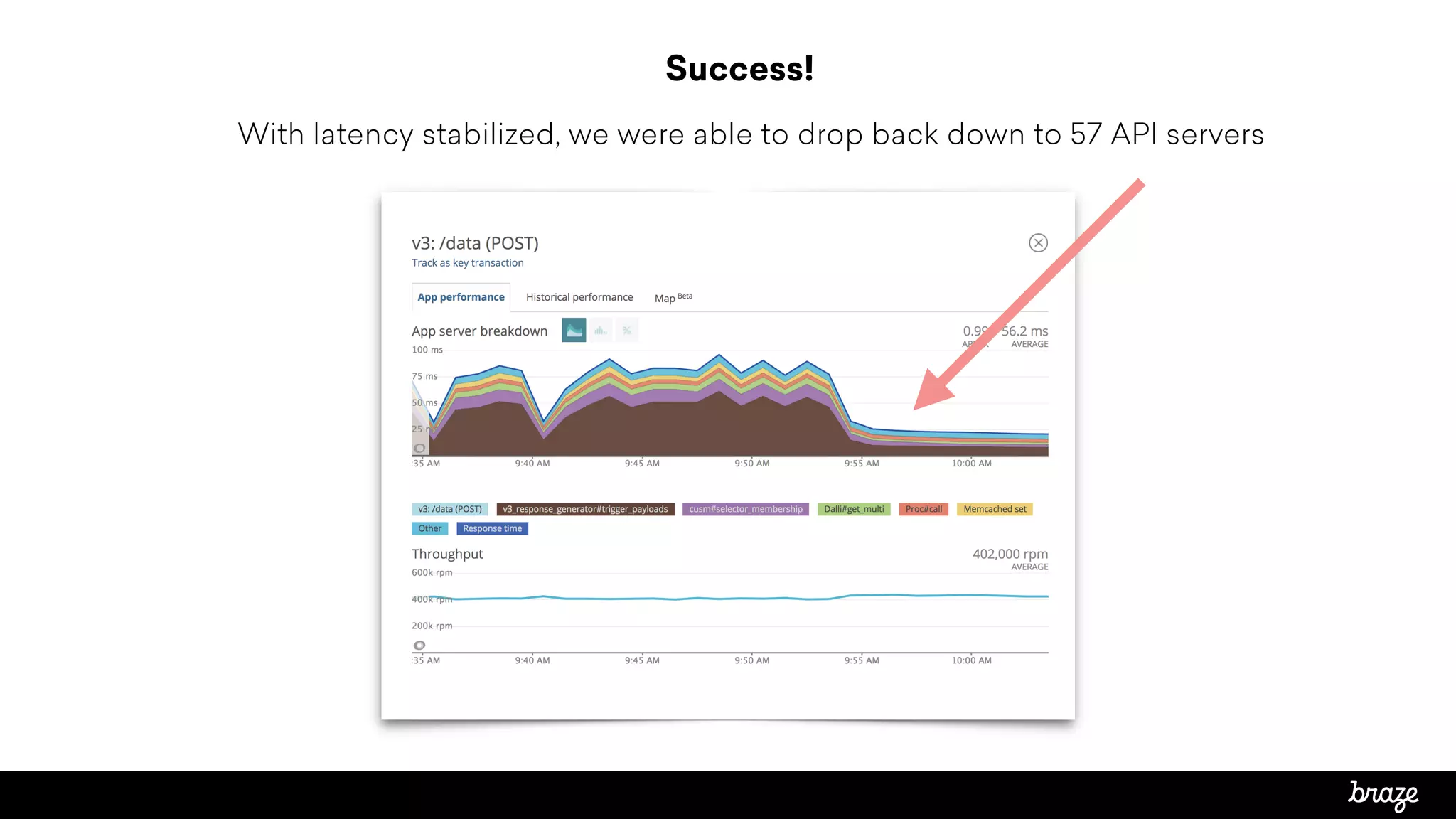



The document summarizes how Braze, a customer engagement platform, optimized their API performance using Redis. Braze saw high API latency and server utilization from cache stampeding when in-app message targeting rules were recomputed every 90 seconds by thousands of requests. To fix this, Braze used Redis to control cache refresh using SETNX locks, extending the cache TTL to 180 seconds with one process refreshing every 90 seconds. This reduced computation concurrency and dropped API requests to 1 per period. Latency stabilized at 3-4 seconds and server count could be reduced, optimizing performance and costs.























































































