Download as PDF, PPTX








![Straggling Nested JSON Retrieval
> Need to store JSON file in memory in order to parse.
> e.g. AWS CloudTrail Log File Format
> Apache Drill or Presto based filter plugins?
> ‘FLATTEN’ very powerful and useful
> https://drill.apache.org/docs/flatten/
13
{
"Records": [{
"eventVersion": "1.0",
"userIdentity": {
"type": "IAMUser",
"principalId": "EX_PRINCIPAL_ID",
"arn": "arn:aws:iam::123456789012:user/Alice",
"accessKeyId": "EXAMPLE_KEY_ID",
"accountId": "123456789012",
"userName": "Alice"
}, … … ]}](https://image.slidesharecdn.com/muga-20170516-embulkmeetup3final-170517042555/75/Recent-Updates-at-Embulk-Meetup-3-13-2048.jpg)
















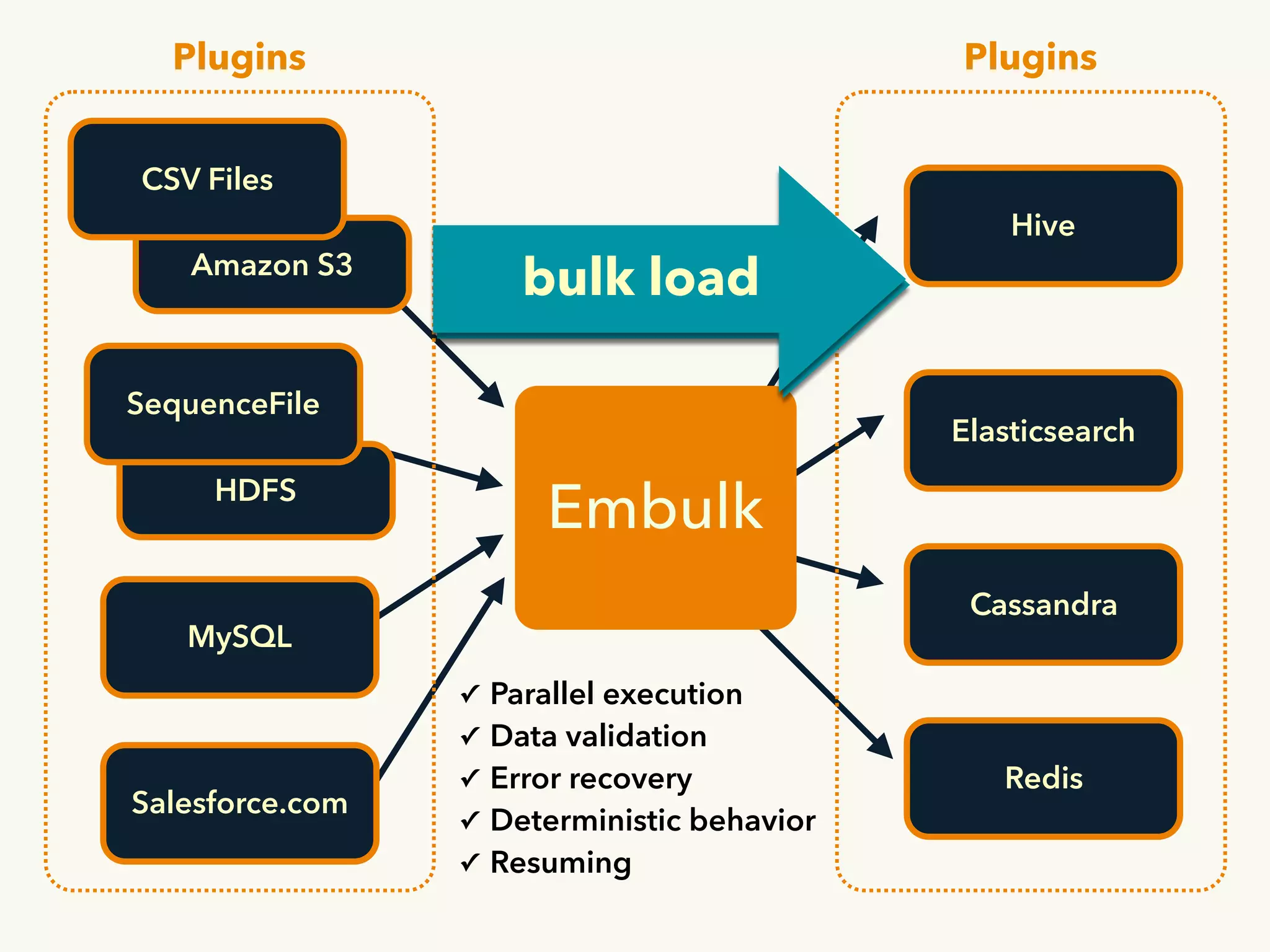
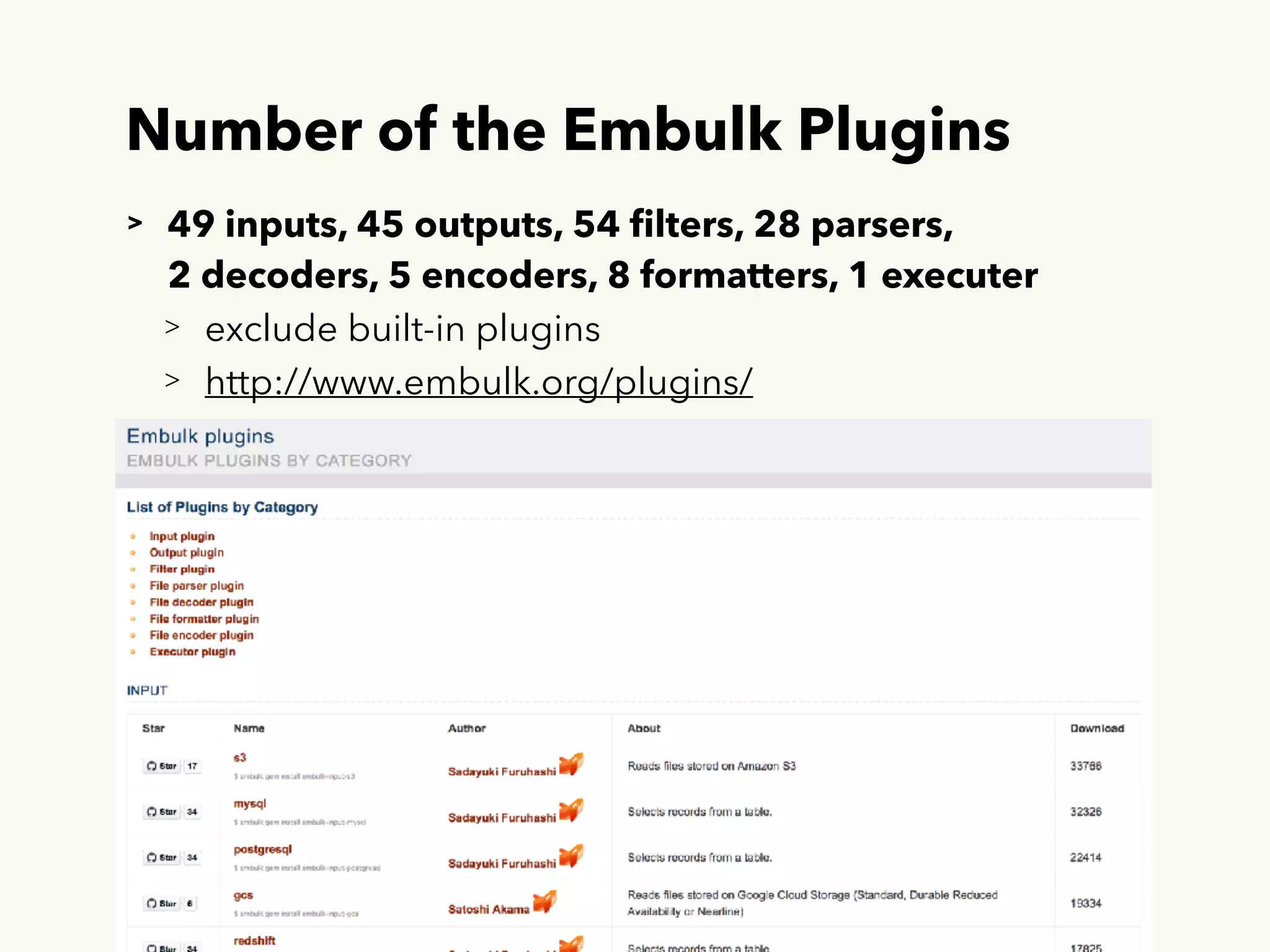
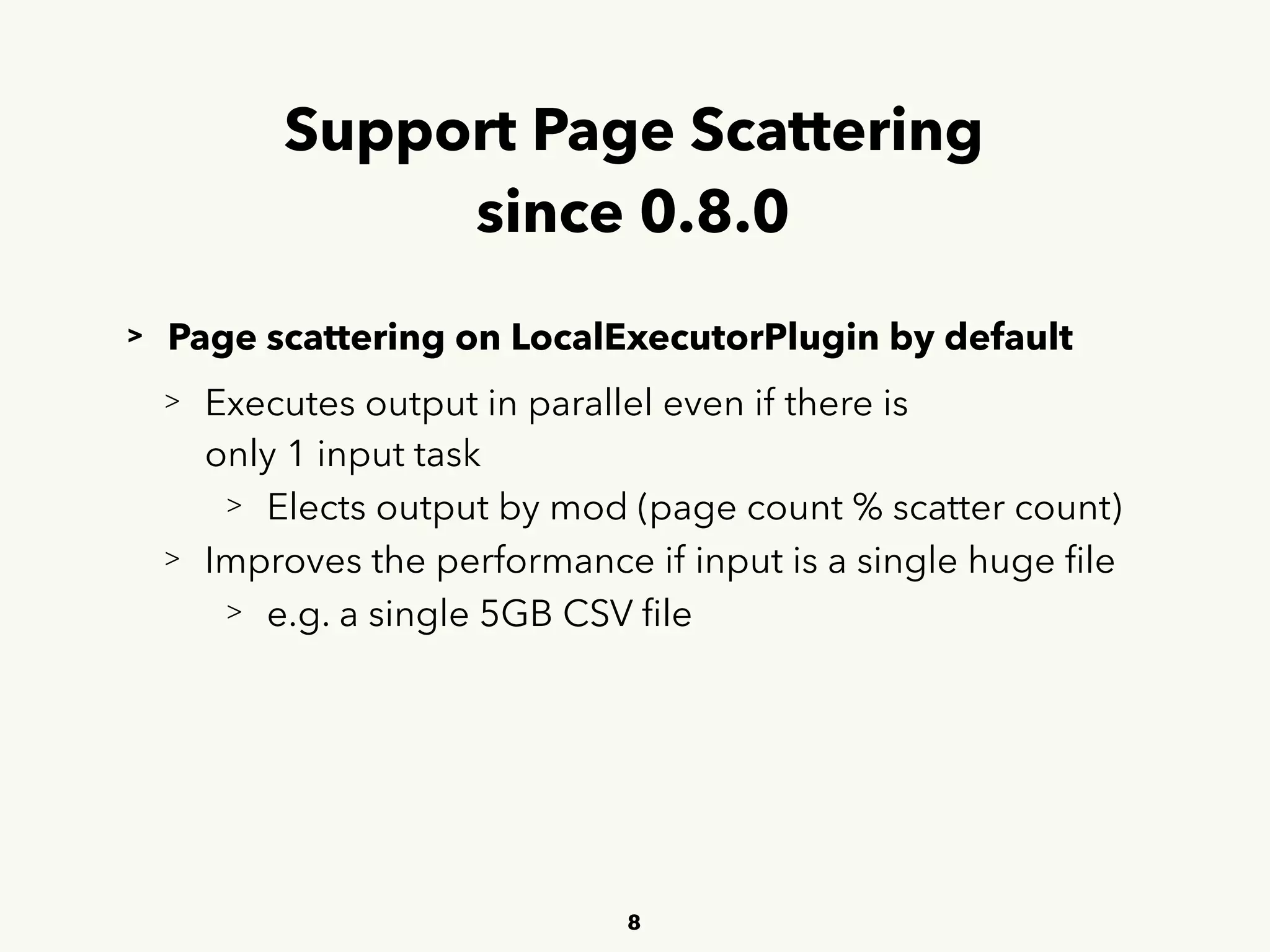
This document summarizes a presentation given by Muga Nishizawa on recent updates to Embulk. Some key points include: - Embulk is an open-source tool for parallel bulk data loading between various sources and destinations using plugins. - Recent updates include new plugins, performance improvements, and over 150 pull requests merged since the last meetup. - Future plans include improving tolerance to input source changes and a new "embulk-filter-calcite" plugin to transform data via SQL queries.













![[245] presto 내부구조 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/245presto-150915054242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





















































