Download as PDF, PPTX


















![● RAG projects are both Statistical
and Machine Learning projects
Careful what you ask for…
Was there a [Cosine Similarity] distance result threshold
where I could programmatically disregard the query as
irrelevant?
“Will the Cleveland Browns win the
AFC North?”
Returned a result with a distance of 0.0141!
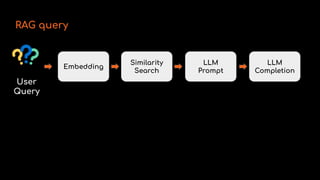
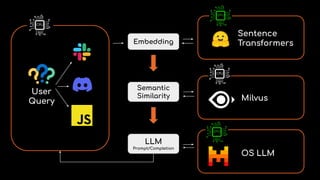
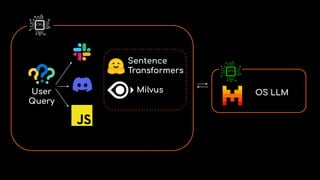
RAG
201](https://image.slidesharecdn.com/ragpipelineswithreal-timedata-241031222150-2e95d35e/85/RAG-Pipelines-with-Real-Time-data-Cloudera-21-320.jpg)
![Careful what you ask for…
Was there a [Cosine Similarity] distance result threshold
where I could programmatically disregard the query as
irrelevant?
“Will the Cleveland Browns win the
AFC North?”
Returned a result with a distance of 0.0141!
“...and select "Align vertically" to
achieve these results”
RAG
201
● RAG projects are both Statistical
and Machine Learning projects](https://image.slidesharecdn.com/ragpipelineswithreal-timedata-241031222150-2e95d35e/85/RAG-Pipelines-with-Real-Time-data-Cloudera-22-320.jpg)










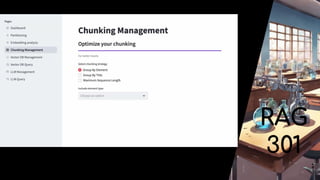


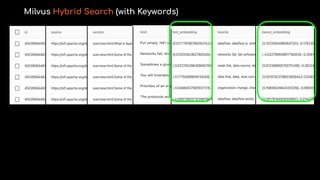









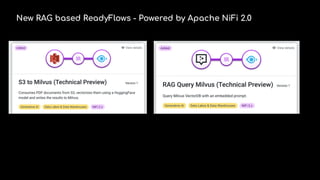
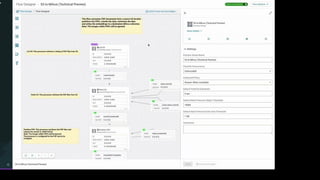




The document highlights rag pipelines with real-time data and their recognition as a visionary in the 2024 Gartner Magic Quadrant for data science and machine learning platforms. It discusses the advantages of deploying trusted AI, reducing costs and complexities, and emphasizes the importance of data management strategies like partitioning and chunking in optimizing machine learning projects. Zilliz is notably recognized for its cloud-native vector database capabilities that enhance real-time AI applications.



































































