Overview
2
Retrieval-Augmented Generation (RAG)
Agenda
•Why RAG exists: the “parametric memory” problem
• Core architecture: ingest retrieve generate
→ →
• What makes retrieval work (chunking, indexing, reranking)
• Evaluation: retrieval + generation metrics
• Security & production concerns
• When to choose RAG vs fine-tuning
3.
Motivation
3
Retrieval-Augmented Generation (RAG)
Theproblem: LLMs don't “know” your latest truth
Freshness
Models can't
“update”
instantly
Provenance
Hard to cite
sources
Accuracy
Hallucinations
happen
RAG is a pattern that adds **external context at runtime** so the model can:
• Answer using your docs / databases (not just training data)
• Provide traceable citations or snippets
• Stay current as documents change
4.
Concept
4
Retrieval-Augmented Generation (RAG)
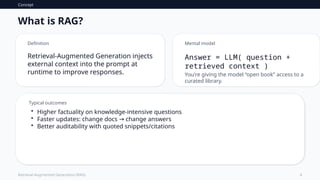
Whatis RAG?
Definition
Retrieval-Augmented Generation injects
external context into the prompt at
runtime to improve responses.
Mental model
Answer = LLM( question +
retrieved context )
You're giving the model “open book” access to a
curated library.
Typical outcomes
• Higher factuality on knowledge-intensive questions
• Faster updates: change docs change answers
→
• Better auditability with quoted snippets/citations
5.
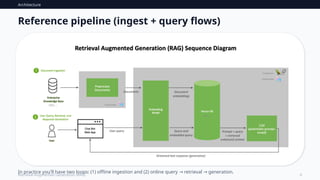
Architecture
5
Retrieval-Augmented Generation (RAG)
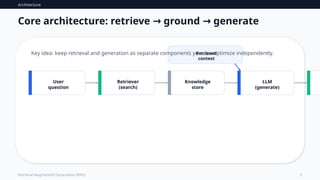
Corearchitecture: retrieve ground generate
→ →
User
question
Retriever
(search)
Knowledge
store
LLM
(generate)
Retrieved
context
Key idea: keep retrieval and generation as separate components you can optimize independently.
Ingestion
7
Retrieval-Augmented Generation (RAG)
Ingestion:turn documents into searchable chunks
Steps
• Load: PDFs, HTML, tickets, wikis, databases
• Clean: remove boilerplate, fix encoding,
normalize tables
• Split: chunk text with overlap
• Embed: create vectors + store metadata
• Index: build vector (and optionally keyword)
index
Metadata is your superpower
• source URL/path
• document type
• owner/team
• timestamp/version
• ACLs / permissions
Common knobs
• chunk size & overlap
• top‑k retrieved
• hybrid search weights
• reranker on/off
• context window budget
8.
Retrieval
8
Retrieval-Augmented Generation (RAG)
Retrievalstrategies (what to try first)
Dense (vector) search
• Best for semantic
matches
• Uses embeddings +
similarity
• Good default for Q&A
Sparse (keyword) search
• Best for exact terms / IDs
• BM25/TF‑IDF style
• Great for “error codes”
Hybrid + reranking
• Combine dense + sparse
• Rerank top‑N with
stronger model
• Often best quality
Rule of thumb: start dense add metadata filters add hybrid add reranking only if needed.
→ → →
9.
Retrieval
9
Retrieval-Augmented Generation (RAG)
Vectorindexes: fast similarity search at scale
What a vector index does
• Stores embeddings (vectors) + metadata
• Runs approximate nearest-neighbor (ANN)
search
• Returns top‑k chunks for a query embedding
• Often supports filters (type, owner, date, ACL)
Common index families
• HNSW (graph)
• IVF / PQ (quantization)
• Flat (exact, small corpora)
One popular OSS option
FAISS: efficient similarity search and clustering of
dense vectors (CPU/GPU).
10.
Generation
10
Retrieval-Augmented Generation (RAG)
Contextassembly: make it easy to be correct
Prompt patterns that work
• Put retrieved chunks in a consistent
“Context:” section
• Ask for grounded answers + citations
• If context is insufficient, say so (don't guess)
• Use short chunk IDs for quoting
Example (structure)
SYSTEM: You answer using ONLY the provided context.
CONTEXT:
[1] …chunk text… (source, date)
[2] …chunk text… (source, date)
USER: <question>
ASSISTANT:
- Answer in 3–6 bullets
- Cite like [1][2]
- If missing info, say what's missing
11.
Evaluation
11
Retrieval-Augmented Generation (RAG)
Evaluation:measure retrieval AND generation
Retrieval quality
• Recall@k (did we retrieve the needed chunk?)
• MRR (how early is the first correct chunk?)
• nDCG (ranking quality with graded relevance)
Generation quality
• Faithfulness (supported by context)
• Answer relevance (addresses the question)
• Citation precision/recall (if you require citations)
Ragas (RAGAS) framework
A reference-free evaluation approach designed for
RAG pipelines (retrieval + generation metrics).
12.
Security
12
Retrieval-Augmented Generation (RAG)
Security:RAG helps, but doesn't “solve” prompt injection
Common RAG-specific risks
• Prompt injection inside retrieved docs
• Data exfiltration via overly-broad retrieval
• Cross-tenant leakage without strong ACL
filtering
• Malicious documents poisoning the index
Mitigations to layer
• Treat retrieved text as untrusted input
• Strict system instructions + output constraints
• Document allowlists + signed ingestion
• Permission filters at query time (ACL-aware
retrieval)
• Red-team tests for injection patterns
13.
Production
13
Retrieval-Augmented Generation (RAG)
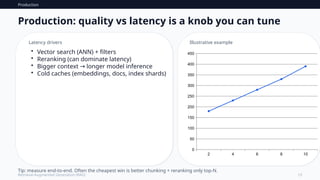
Production:quality vs latency is a knob you can tune
Latency drivers
• Vector search (ANN) + filters
• Reranking (can dominate latency)
• Bigger context longer model inference
→
• Cold caches (embeddings, docs, index shards)
Illustrative example
2 4 6 8 10
0
50
100
150
200
250
300
350
400
450
Tip: measure end-to-end. Often the cheapest win is better chunking + reranking only top‑N.
14.
Decision
14
Retrieval-Augmented Generation (RAG)
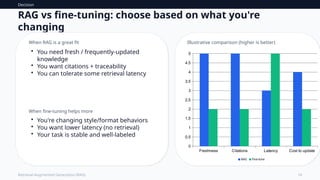
RAGvs fine-tuning: choose based on what you're
changing
When RAG is a great fit
• You need fresh / frequently-updated
knowledge
• You want citations + traceability
• You can tolerate some retrieval latency
When fine-tuning helps more
• You're changing style/format behaviors
• You want lower latency (no retrieval)
• Your task is stable and well-labeled
Illustrative comparison (higher is better)
Freshness Citations Latency Cost to update
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
RAG Fine-tune
15.
Next steps
15
Retrieval-Augmented Generation(RAG)
RAG implementation checklist
Build
• Pick a corpus + owners
• Chunk + embed + index
• Add metadata + ACLs
• Add hybrid + rerank only if needed
Operate
• Offline eval set + dashboards
• Monitor retrieval drift
• Cache hot queries + embeddings
• Security reviews + red-team
Good RAG is an engineering discipline: data quality + retrieval quality + evaluation
loops.
#9
[Sources]
- https://github.com/facebookresearch/faiss (Faiss project description)
- https://docs.langchain.com/oss/python/langchain/retrieval (vector store concept in a minimal RAG workflow)
[/Sources]
#10
[Sources]
- https://help.openai.com/en/articles/8868588-retrieval-augmented-generation-rag-and-semantic-search-for-gpts (RAG described as injecting context into prompts)
[/Sources]
#12
[Sources]
- https://owasp.org/www-project-top-10-for-large-language-model-applications/assets/PDF/OWASP-Top-10-for-LLMs-v2025.pdf (notes that RAG/fine-tuning do not fully mitigate prompt injection)
[/Sources]
#13
[Sources]
- (Chart values are illustrative / synthetic.)
[/Sources]
#14
[Sources]
- https://help.openai.com/en/articles/8868588-retrieval-augmented-generation-rag-and-semantic-search-for-gpts (RAG as runtime context injection; motivates “freshness”)
- (Chart values are illustrative / synthetic.)
[/Sources]






![Generation
10
Retrieval-Augmented Generation (RAG)
Context assembly: make it easy to be correct
Prompt patterns that work
• Put retrieved chunks in a consistent
“Context:” section
• Ask for grounded answers + citations
• If context is insufficient, say so (don't guess)
• Use short chunk IDs for quoting
Example (structure)
SYSTEM: You answer using ONLY the provided context.
CONTEXT:
[1] …chunk text… (source, date)
[2] …chunk text… (source, date)
USER: <question>
ASSISTANT:
- Answer in 3–6 bullets
- Cite like [1][2]
- If missing info, say what's missing](https://image.slidesharecdn.com/ragpresentation-260121221643-3631275f/85/Retrieval_Augmented_Generation_Presentation-pptx-10-320.jpg)