Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Takatoshi Kondo
PPTX, PDF
1,615 views
Pub/Sub model, msm, and asio
Boost study group #20 presentation slides.
Software
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 42
2
/ 42
3
/ 42
4
/ 42
5
/ 42
6
/ 42
7
/ 42
8
/ 42
9
/ 42
10
/ 42
11
/ 42
12
/ 42
13
/ 42
14
/ 42
15
/ 42
16
/ 42
17
/ 42
18
/ 42
19
/ 42
20
/ 42
21
/ 42
22
/ 42
23
/ 42
24
/ 42
25
/ 42
26
/ 42
27
/ 42
28
/ 42
29
/ 42
30
/ 42
31
/ 42
32
/ 42
33
/ 42
34
/ 42
35
/ 42
36
/ 42
37
/ 42
38
/ 42
39
/ 42
40
/ 42
41
/ 42
42
/ 42
More Related Content
PDF
Boost sg msgpack
by
Takatoshi Kondo
PPTX
CppCon2016 report and Boost.SML
by
Takatoshi Kondo
PPT
いまさら聞けないRake入門
by
Tomoya Kawanishi
PDF
Reactive Extensionsで非同期処理を簡単に
by
Yoshifumi Kawai
PDF
H2O - making HTTP better
by
Kazuho Oku
PPTX
WebRTC multitrack / multistream
by
mganeko
PDF
Qt Creator を拡張する
by
Takumi Asaki
PDF
Rust-DPDK
by
Masaru Oki
Boost sg msgpack
by
Takatoshi Kondo
CppCon2016 report and Boost.SML
by
Takatoshi Kondo
いまさら聞けないRake入門
by
Tomoya Kawanishi
Reactive Extensionsで非同期処理を簡単に
by
Yoshifumi Kawai
H2O - making HTTP better
by
Kazuho Oku
WebRTC multitrack / multistream
by
mganeko
Qt Creator を拡張する
by
Takumi Asaki
Rust-DPDK
by
Masaru Oki
What's hot
PDF
C#次世代非同期処理概観 - Task vs Reactive Extensions
by
Yoshifumi Kawai
PDF
HTTP/2時代のウェブサイト設計
by
Kazuho Oku
PPTX
WebRTC getStats - WebRTC Meetup Tokyo 5 LT
by
mganeko
PDF
Rake
by
Tomoya Kawanishi
PDF
NanoStrand
by
Masashi Umezawa
PPTX
WebRTC meetup Tokyo 1
by
mganeko
PDF
Node.js with WebRTC DataChannel
by
mganeko
PDF
WebRTC UserMedia Catalog: いろんなユーザメディア(MediaStream)を使ってみよう
by
mganeko
PDF
qmake入門
by
hermit4 Ishida
PDF
Reactive Extensions v2.0
by
Yoshifumi Kawai
PDF
Observable Everywhere - Rxの原則とUniRxにみるデータソースの見つけ方
by
Yoshifumi Kawai
PDF
HTTP/2, QUIC入門
by
shigeki_ohtsu
PDF
JSONでメール送信 | HTTP API Server ``Haineko''/YAPC::Asia Tokyo 2013 LT Day2
by
azumakuniyuki 🐈
PDF
Node.jsv0.8からv4.xへのバージョンアップ ~大規模Push通知基盤の運用事例~
by
Recruit Technologies
PDF
Pd Kai#3 Startup Process
by
nagachika t
PPTX
Gocon2017:Goのロギング周りの考察
by
貴仁 大和屋
PDF
Rust-DPDK
by
Masaru Oki
PDF
LINQ in Unity
by
Yoshifumi Kawai
PDF
linq.js - Linq to Objects for JavaScript
by
Yoshifumi Kawai
C#次世代非同期処理概観 - Task vs Reactive Extensions
by
Yoshifumi Kawai
HTTP/2時代のウェブサイト設計
by
Kazuho Oku
WebRTC getStats - WebRTC Meetup Tokyo 5 LT
by
mganeko
Rake
by
Tomoya Kawanishi
NanoStrand
by
Masashi Umezawa
WebRTC meetup Tokyo 1
by
mganeko
Node.js with WebRTC DataChannel
by
mganeko
WebRTC UserMedia Catalog: いろんなユーザメディア(MediaStream)を使ってみよう
by
mganeko
qmake入門
by
hermit4 Ishida
Reactive Extensions v2.0
by
Yoshifumi Kawai
Observable Everywhere - Rxの原則とUniRxにみるデータソースの見つけ方
by
Yoshifumi Kawai
HTTP/2, QUIC入門
by
shigeki_ohtsu
JSONでメール送信 | HTTP API Server ``Haineko''/YAPC::Asia Tokyo 2013 LT Day2
by
azumakuniyuki 🐈
Node.jsv0.8からv4.xへのバージョンアップ ~大規模Push通知基盤の運用事例~
by
Recruit Technologies
Pd Kai#3 Startup Process
by
nagachika t
Gocon2017:Goのロギング周りの考察
by
貴仁 大和屋
Rust-DPDK
by
Masaru Oki
LINQ in Unity
by
Yoshifumi Kawai
linq.js - Linq to Objects for JavaScript
by
Yoshifumi Kawai
Viewers also liked
PDF
Glfw3,OpenGL,GUI
by
hira_kuni_45
PDF
C++14 solve explicit_default_constructor
by
Akira Takahashi
PDF
C++コミュニティーの中心でC++をDISる
by
Hideyuki Tanaka
PDF
Boost.Timer
by
melpon
PDF
C++14 enum hash
by
Akira Takahashi
PDF
Introduction to boost test
by
Kohsuke Yuasa
Glfw3,OpenGL,GUI
by
hira_kuni_45
C++14 solve explicit_default_constructor
by
Akira Takahashi
C++コミュニティーの中心でC++をDISる
by
Hideyuki Tanaka
Boost.Timer
by
melpon
C++14 enum hash
by
Akira Takahashi
Introduction to boost test
by
Kohsuke Yuasa
More from Takatoshi Kondo
PPTX
Effective Modern C++ study group Item39
by
Takatoshi Kondo
PDF
MessagePack(msgpack): Compact and Fast Serialization Library
by
Takatoshi Kondo
PPTX
Emcpp0506
by
Takatoshi Kondo
PDF
Boostsapporomsmpost 111106070819-phpapp02
by
Takatoshi Kondo
PDF
Boostsapporomsmpre 111030054504-phpapp02
by
Takatoshi Kondo
PPTX
Unpack mechanism of the msgpack-c
by
Takatoshi Kondo
PPTX
N3495 inplace realloc
by
Takatoshi Kondo
PPTX
N3701 concept lite
by
Takatoshi Kondo
PPTX
Aho-Corasick string matching algorithm
by
Takatoshi Kondo
Effective Modern C++ study group Item39
by
Takatoshi Kondo
MessagePack(msgpack): Compact and Fast Serialization Library
by
Takatoshi Kondo
Emcpp0506
by
Takatoshi Kondo
Boostsapporomsmpost 111106070819-phpapp02
by
Takatoshi Kondo
Boostsapporomsmpre 111030054504-phpapp02
by
Takatoshi Kondo
Unpack mechanism of the msgpack-c
by
Takatoshi Kondo
N3495 inplace realloc
by
Takatoshi Kondo
N3701 concept lite
by
Takatoshi Kondo
Aho-Corasick string matching algorithm
by
Takatoshi Kondo
Pub/Sub model, msm, and asio
1.
Pub/Subモデルとmsmとasioと Takatoshi Kondo 2016/7/23 1
2.
発表内容 2016/7/23 2 • Pub/Subモデルとは? •
コネクションとスレッド • 2つのスケーラビリティ • brokerの状態管理とイベントの遅延処理 • msmの要求する排他制御 • io_serviceのpostと実行順序 • async_writeとstrand
3.
自己紹介 2016/7/23 3 • 近藤
貴俊 • ハンドルネーム redboltz • msgpack-cコミッタ – https://github.com/msgpack/msgpack-c • MQTTのC++クライアント mqtt_client_cpp 開発 – https://github.com/redboltz/mqtt_client_cpp • MQTTを拡張したスケーラブルな brokerを仕事で開発中 • CppCon 2016 参加予定
4.
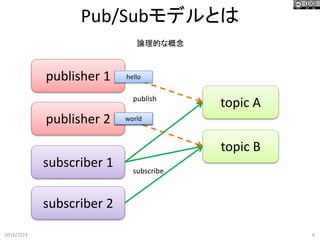
Pub/Subモデルとは 2016/7/23 4 topic A publisher
1 subscriber 1 topic B publisher 2 subscriber 2 hello world 論理的な概念 subscribe publish world
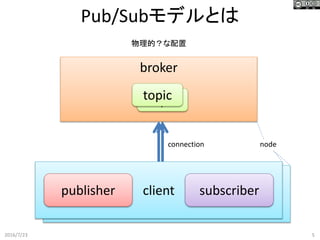
5.
client Pub/Subモデルとは 2016/7/23 5 broker clientpublisher subscriber topictopic connection 物理的?な配置 node
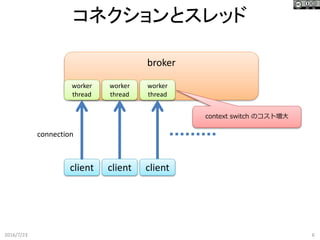
6.
コネクションとスレッド 2016/7/23 6 broker client connection worker thread worker thread worker thread client client context
switch のコスト増大
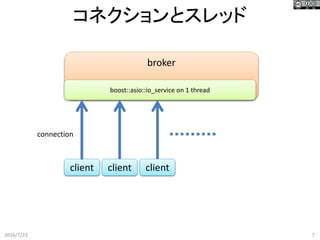
7.
コネクションとスレッド 2016/7/23 7 broker client connection boost::asio::io_service on
1 thread client client
8.
io_service 2016/7/23 8 #include <iostream> #include
<boost/asio.hpp> int main() { boost::asio::io_service ios; ios.post([]{ std::cout << __LINE__ << std::endl; }); ios.post([]{ std::cout << __LINE__ << std::endl; }); ios.post([]{ std::cout << __LINE__ << std::endl; }); ios.post([]{ std::cout << __LINE__ << std::endl; }); ios.post([]{ std::cout << __LINE__ << std::endl; }); ios.run(); } http://melpon.org/wandbox/permlink/MzfsrLNdJjfAeV15 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10 11 12 様々な処理(ネットワーク、タイマ、シリアルポート、 シグナルハンドル、etc)をio_serviceにpost。 イベントが無くなるまで処理を実行 http://www.boost.org/doc/html/boost_asio/reference.html
9.
io_service 2016/7/23 9 #include <iostream> #include
<boost/asio.hpp> int main() { boost::asio::io_service ios; ios.post([&ios]{ std::cout << __LINE__ << std::endl; ios.post([&ios]{ std::cout << __LINE__ << std::endl; ios.post([&ios]{ std::cout << __LINE__ << std::endl; }); }); }); ios.run(); } http://melpon.org/wandbox/permlink/lXbFTVurVNUXM8BZ 7 9 11 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 処理の中で次のリクエストをpost
10.
2つのスケーラビリティ 2016/7/23 10 • マルチスレッド •
マルチノード(マルチサーバ)
11.
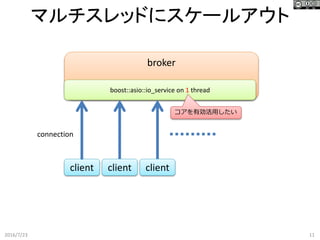
マルチスレッドにスケールアウト 2016/7/23 11 broker client connection boost::asio::io_service on
1 thread client client コアを有効活用したい
12.
マルチスレッドにスケールアウト 2016/7/23 12 #include <iostream> #include
<thread> #include <boost/asio.hpp> int main() { boost::asio::io_service ios; ios.post([]{ std::cout << __LINE__ << std::endl; }); ios.post([]{ std::cout << __LINE__ << std::endl; }); ios.post([]{ std::cout << __LINE__ << std::endl; }); ios.post([]{ std::cout << __LINE__ << std::endl; }); ios.post([]{ std::cout << __LINE__ << std::endl; }); std::vector<std::thread> ths; ths.emplace_back([&ios]{ ios.run(); }); ths.emplace_back([&ios]{ ios.run(); }); ths.emplace_back([&ios]{ ios.run(); }); ths.emplace_back([&ios]{ ios.run(); }); ths.emplace_back([&ios]{ ios.run(); }); for (auto& t : ths) t.join(); std::cout << "finished" << std::endl; } http://melpon.org/wandbox/permlink/z5bQJYgO23tvM9XF 8 9 10 11 7 finished 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 実行順序はpostの順序とは異なる
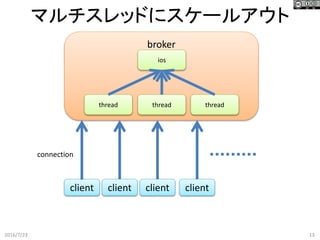
13.
マルチスレッドにスケールアウト 2016/7/23 13 broker client connection client client ios client thread
threadthread
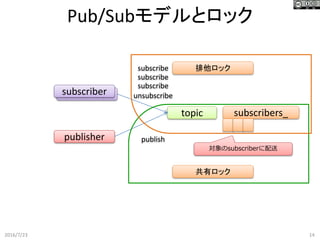
14.
subscriber Pub/Subモデルとロック 2016/7/23 14 subscriber topic publisher subscribers_ subscribe subscribe subscribe unsubscribe 排他ロック publish 対象のsubscriberに配送 共有ロック
15.
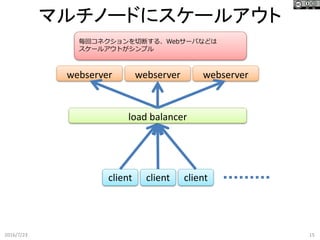
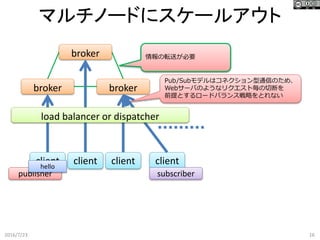
webserver マルチノードにスケールアウト 2016/7/23 15 client client
client load balancer webserver webserver 毎回コネクションを切断する、Webサーバなどは スケールアウトがシンプル
16.
broker brokerbroker マルチノードにスケールアウト 2016/7/23 16 client client
client client Pub/Subモデルはコネクション型通信のため、 Webサーバのようなリクエスト毎の切断を 前提とするロードバランス戦略をとれない 情報の転送が必要 publisher subscriber load balancer or dispatcher hello
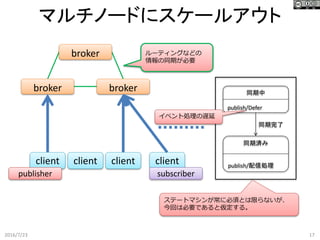
17.
broker brokerbroker マルチノードにスケールアウト 2016/7/23 17 client client
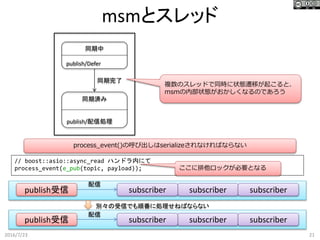
client client ルーティングなどの 情報の同期が必要 publisher subscriber 同期中 publish/Defer 同期済み publish/配信処理 同期完了 イベント処理の遅延 ステートマシンが常に必須とは限らないが、 今回は必要であると仮定する。
18.
msmとasioの組み合わせ 2016/7/23 18 boost::asio::async_read( socket_, boost::asio::buffer(payload_), [this]( boost::system::error_code const&
ec, std::size_t bytes_transferred){ // error checking ... // 受信時の処理 } ); boost::shared_lock<mutex> guard(mtx_subscribers_); auto& idx = subscribers_.get<tag_topic>(); auto r = idx.equal_range(topic); for (; r.first != r.second; ++r.first) { auto& socket = r.first->socket; boost::asio::write(socket, boost::asio::buffer(payload_)); } 全てのsubscriberに対して publish内容を配信 msm導入前
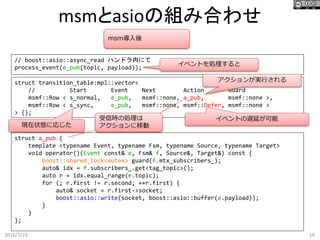
19.
msmとasioの組み合わせ 2016/7/23 19 struct transition_table:mpl::vector< //
Start Event Next Action Guard msmf::Row < s_normal, e_pub, msmf::none, a_pub, msmf::none >, msmf::Row < s_sync, e_pub, msmf::none, msmf::Defer, msmf::none > > {}; struct a_pub { template <typename Event, typename Fsm, typename Source, typename Target> void operator()(Event const& e, Fsm& f, Source&, Target&) const { boost::shared_lock<mutex> guard(f.mtx_subscribers_); auto& idx = f.subscribers_.get<tag_topic>(); auto r = idx.equal_range(e.topic); for (; r.first != r.second; ++r.first) { auto& socket = r.first->socket; boost::asio::write(socket, boost::asio::buffer(e.payload)); } } }; // boost::asio::async_read ハンドラ内にて process_event(e_pub(topic, payload)); msm導入後 受信時の処理は アクションに移動 イベントの遅延が可能 イベントを処理すると 現在状態に応じた アクションが実行される
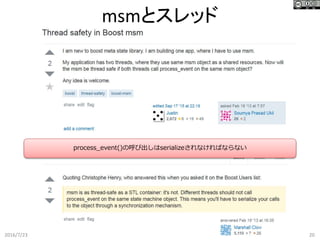
20.
msmとスレッド 2016/7/23 20 process_event()の呼び出しはserializeされなければならない
21.
msmとスレッド 2016/7/23 21 同期中 publish/Defer 同期済み publish/配信処理 同期完了 process_event()の呼び出しはserializeされなければならない 複数のスレッドで同時に状態遷移が起こると、 msmの内部状態がおかしくなるのであろう // boost::asio::async_read
ハンドラ内にて process_event(e_pub(topic, payload)); ここに排他ロックが必要となる subscribersubscriberpublish受信 subscriber subscribersubscriberpublish受信 subscriber 配信 配信 別々の受信でも順番に処理せねばならない
22.
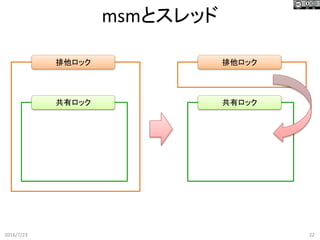
msmとスレッド 2016/7/23 22 排他ロック 共有ロック 排他ロック 共有ロック
23.
msmとasioの組み合わせ 2016/7/23 23 struct a_pub
{ template <typename Event, typename Fsm, typename Source, typename Target> void operator()(Event const& e, Fsm& f, Source&, Target&) const { ios.post([&f, e]{ boost::shared_lock<mutex> guard(f.mtx_subscribers_); auto& idx = f.subscribers_.get<tag_topic>(); auto r = idx.equal_range(e.topic); for (; r.first != r.second; ++r.first) { auto& socket = r.first->socket; boost::asio::write(socket, boost::asio::buffer(e.payload)); } }); } }; 排他ロックの必要な範囲では、ios.post()のみ行い、 ios.post()に渡した処理が呼び出されるところで、 共有ロックを行う subscribersubscriberpublish受信 subscriber subscribersubscriberpublish受信 subscriber post post postのみserialize 並行処理が可能
24.
msmとasioの組み合わせ 2016/7/23 24 struct a_pub
{ template <typename Event, typename Fsm, typename Source, typename Target> void operator()(Event const& e, Fsm& f, Source&, Target&) const { ios.post([&f, e]{ boost::shared_lock<mutex> guard(f.mtx_subscribers_); auto& idx = f.subscribers_.get<tag_topic>(); auto r = idx.equal_range(e.topic); for (; r.first != r.second; ++r.first) { auto& socket = r.first->socket; boost::asio::write(socket, boost::asio::buffer(e.payload)); } }); } }; 排他ロックの必要な範囲では、ios.post()のみ行い、 ios.post()に渡した処理が呼び出されるところで、 共有ロックを行う 注意点 ・処理の遅延に問題は無いか? ・ios.post()に渡した処理が参照するオブジェクトは生存しているか?
25.
forループの処理もpostすれば。。。 2016/7/23 25 struct a_pub
{ template <typename Event, typename Fsm, typename Source, typename Target> void operator()(Event const& e, Fsm& f, Source&, Target&) const { ios.post([&f, e]{ boost::shared_lock<mutex> guard(f.mtx_subscribers_); auto& idx = f.subscribers_.get<tag_topic>(); auto r = idx.equal_range(e.topic); for (; r.first != r.second; ++r.first) { auto& socket = r.first->socket; ios.post([&socket, e]{ boost::asio::write(socket, boost::asio::buffer(e.payload)); }); } }); } }; ループの中で行われるwrite()が並列化され、パフォーマンスの向上が見込める
26.
struct a_pub { template
<typename Event, typename Fsm, typename Source, typename Target> void operator()(Event const& e, Fsm& f, Source&, Target&) const { ios.post([&f, e]{ boost::shared_lock<mutex> guard(f.mtx_subscribers_); auto& idx = f.subscribers_.get<tag_topic>(); auto r = idx.equal_range(e.topic); for (; r.first != r.second; ++r.first) { auto& socket = r.first->socket; ios.post([&socket, e]{ boost::asio::write(socket, boost::asio::buffer(e.payload)); }); } }); } }; forループの処理もpostすれば。。。 2016/7/23 26 publish受信 subscriber post postのみserialize 並行処理が可能 post subscriber subscriber publish受信 subscriber post 並行処理が可能 post subscriber subscriber 並行処理が可能 排他ロック 共有ロック
27.
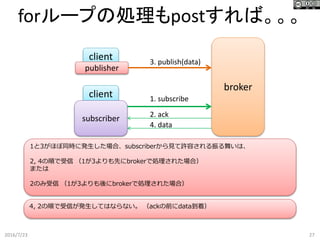
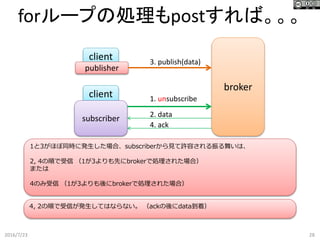
broker forループの処理もpostすれば。。。 2016/7/23 27 client client publisher subscriber 1. subscribe 2.
ack 3. publish(data) 4. data 1と3がほぼ同時に発生した場合、subscriberから見て許容される振る舞いは、 2, 4の順で受信 (1が3よりも先にbrokerで処理された場合) または 2のみ受信 (1が3よりも後にbrokerで処理された場合) 4, 2の順で受信が発生してはならない。 (ackの前にdata到着)
28.
broker forループの処理もpostすれば。。。 2016/7/23 28 client client publisher subscriber 1. unsubscribe 2.
data 3. publish(data) 4. ack 1と3がほぼ同時に発生した場合、subscriberから見て許容される振る舞いは、 2, 4の順で受信 (1が3よりも先にbrokerで処理された場合) または 4のみ受信 (1が3よりも後にbrokerで処理された場合) 4, 2の順で受信が発生してはならない。 (ackの後にdata到着)
29.
forループの処理もpostすれば。。。 2016/7/23 29 #include <iostream> #include
<thread> #include <boost/asio.hpp> int main() { boost::asio::io_service ios; ios.post([]{ std::cout << __LINE__ << std::endl; }); ios.post([]{ std::cout << __LINE__ << std::endl; }); ios.post([]{ std::cout << __LINE__ << std::endl; }); ios.post([]{ std::cout << __LINE__ << std::endl; }); ios.post([]{ std::cout << __LINE__ << std::endl; }); std::vector<std::thread> ths; ths.emplace_back([&ios]{ ios.run(); }); ths.emplace_back([&ios]{ ios.run(); }); ths.emplace_back([&ios]{ ios.run(); }); ths.emplace_back([&ios]{ ios.run(); }); ths.emplace_back([&ios]{ ios.run(); }); for (auto& t : ths) t.join(); std::cout << "finished" << std::endl; } http://melpon.org/wandbox/permlink/z5bQJYgO23tvM9XF 8 9 10 11 7 finished 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 実行順序はpostの順序とは異なる
30.
forループの処理もpostすれば。。。 2016/7/23 30 struct a_pub
{ template <typename Event, typename Fsm, typename Source, typename Target> void operator()(Event const& e, Fsm& f, Source&, Target&) const { ios.post([&f, e]{ boost::shared_lock<mutex> guard(f.mtx_subscribers_); auto& idx = f.subscribers_.get<tag_topic>(); auto r = idx.equal_range(e.topic); for (; r.first != r.second; ++r.first) { auto& socket = r.first->socket; ios.post([&socket, e]{ boost::asio::write(socket, boost::asio::buffer(e.payload)); }); } }); } }; unsubscribe処理を行い、ackを返送した後に、この処理が実行されることがある
31.
問題はどこにあるのか? 2016/7/23 31 • 同一コネクションに対する送信の順序を 保証したいが、 •
io_service::post()を使うことで、順序の保証が できなくなっている • しかし、ループ処理の並列化は行いたい • コネクションとの対応付けを考慮した、 処理のpostが行えれば良い
32.
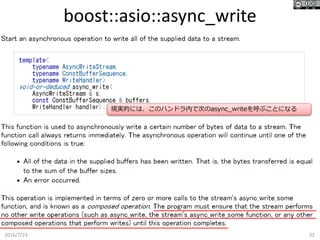
boost::asio::async_write 2016/7/23 32 現実的には、このハンドラ内で次のasync_writeを呼ぶことになる
33.
boost::asio::async_write 2016/7/23 33 template <typename
F> void my_async_write( std::shared_ptr<std::string> const& buf, F const& func) { strand_.post( [this, buf, func] () { queue_.emplace_back(buf, func); if (queue_.size() > 1) return; my_async_write_imp(); } ); } まずenque データは、バッファと完了ハンドラ 未完了のasync_writeがあるなら 何もせず終了 async_writeの呼び出し処理 制約無く、いつでも呼べる、async_writeを作るには、 自前でキューイングなどの処理を実装する必要がある。
34.
boost::asio::async_write 2016/7/23 34 void my_async_write_imp()
{ auto& elem = queue_.front(); auto const& func = elem.handler(); as::async_write( socket_, as::buffer(elem.ptr(), elem.size()), strand_.wrap( [this, func] (boost::system::error_code const& ec, std::size_t bytes_transferred) { func(ec); queue_.pop_front(); if (!queue_.empty()) { my_async_write_imp(); } } ) ); } queueからデータを取り出して、 async_write まだqueueにデータがあれば、 再びasync_write queueからデータを消去し strand_.post() および strand_.wrap() を用いて、 排他制御を行っている queue_ だけ mutex でロックするのと何が違うのか?
35.
async_readもstrand wrapする 2016/7/23 35 boost::asio::async_read( socket_, boost::asio::buffer(payload_), strand_.wrap( [this]( boost::system::error_code
const& ec, std::size_t bytes_transferred){ // error checking ... // 受信時の処理 } ) ); async_readもstrand経由で処理する
36.
strandは本当に必要か? 2016/7/23 36 strandしなくても、暗黙的にstrandになるケース
37.
publish処理 2016/7/23 37 struct a_pub
{ template <typename Event, typename Fsm, typename Source, typename Target> void operator()(Event const& e, Fsm& f, Source&, Target&) const { ios.post([&f, e]{ boost::shared_lock<mutex> guard(f.mtx_subscribers_); auto& idx = f.subscribers_.get<tag_topic>(); auto r = idx.equal_range(e.topic); for (; r.first != r.second; ++r.first) { auto& socket = r.first->socket; socket.my_async_write(boost::asio::buffer(e.payload), 完了ハンドラ); } }); } }; 自前の非同期writeを呼び出す subscribe / unsubscribe の ack送信処理も、同様に、 自前の非同期writeを経由させることで、順序の入れ替わりを 防ぎ、かつ、処理の並列化を実現することができる
38.
publish処理 2016/7/23 38 struct a_pub
{ template <typename Event, typename Fsm, typename Source, typename Target> void operator()(Event const& e, Fsm& f, Source&, Target&) const { ios.post([&f, e]{ boost::shared_lock<mutex> guard(f.mtx_subscribers_); auto& idx = f.subscribers_.get<tag_topic>(); auto r = idx.equal_range(e.topic); for (; r.first != r.second; ++r.first) { auto& socket = r.first->socket; socket.my_async_write(boost::asio::buffer(e.payload), 完了ハンドラ); } }); } }; 自前の非同期writeを呼び出す publish受信 subscriber post postのみserialize 並行処理が可能 かつ 同一接続に対しては シリアライズ my_async_write subscriber subscriber publish受信 subscriber post subscriber subscriber 並行処理が可能 排他ロック 共有ロック my_async_write 並行処理が可能 かつ 同一接続に対しては シリアライズ
39.
publish処理 2016/7/23 39 struct a_pub
{ template <typename Event, typename Fsm, typename Source, typename Target> void operator()(Event const& e, Fsm& f, Source&, Target&) const { ios.post([&f, e]{ boost::shared_lock<mutex> guard(f.mtx_subscribers_); auto& idx = f.subscribers_.get<tag_topic>(); auto r = idx.equal_range(e.topic); for (; r.first != r.second; ++r.first) { auto& socket = r.first->socket; socket.my_async_write(boost::asio::buffer(e.payload), 完了ハンドラ); } }); } }; 自前の非同期writeを呼び出す 非同期writeは十分に軽量であるため、forループの所要時間は短かった。 排他ロックの中で処理を行ってもパフォーマンスは落ちなかった。 よってシンプルな実装を採用した。(グレーの部分のコードを削除した)
40.
publish処理 2016/7/23 40 struct a_pub
{ template <typename Event, typename Fsm, typename Source, typename Target> void operator()(Event const& e, Fsm& f, Source&, Target&) const { ios.post([&f, e]{ boost::shared_lock<mutex> guard(f.mtx_subscribers_); auto& idx = f.subscribers_.get<tag_topic>(); auto r = idx.equal_range(e.topic); for (; r.first != r.second; ++r.first) { auto& socket = r.first->socket; socket.my_async_write(boost::asio::buffer(e.payload), 完了ハンドラ); } }); } }; 自前の非同期writeを呼び出す publish受信 subscriber post postのみserialize 並行処理が可能 かつ 同一接続に対しては シリアライズ my_async_write subscriber subscriber publish受信 subscriber post subscriber subscriber 並行処理が可能 排他ロック 共有ロック my_async_write 並行処理が可能 かつ 同一接続に対しては シリアライズ
41.
publish処理 2016/7/23 41 struct a_pub
{ template <typename Event, typename Fsm, typename Source, typename Target> void operator()(Event const& e, Fsm& f, Source&, Target&) const { ios.post([&f, e]{ boost::shared_lock<mutex> guard(f.mtx_subscribers_); auto& idx = f.subscribers_.get<tag_topic>(); auto r = idx.equal_range(e.topic); for (; r.first != r.second; ++r.first) { auto& socket = r.first->socket; socket.my_async_write(boost::asio::buffer(e.payload), 完了ハンドラ); } }); } }; 自前の非同期writeを呼び出す publish受信 subscriber my_async_writeのみserialize 並行処理が可能 かつ 同一接続に対しては シリアライズ my_async_write subscriber subscriber publish受信 subscriber subscriber subscriber 排他ロック my_async_write 並行処理が可能 かつ 同一接続に対しては シリアライズ
42.
まとめ 2016/7/23 42 • io_serviceを複数スレッドでrun()することで、 コアを有効利用できる •
msmのDeferはイベント処理を遅延できて便利 • その一方、msmの状態遷移は排他制御を要求する • post()を利用することで任意の処理を、 遅延でき、ロックの最適化が可能となる • post()はコネクションを意識しないので、 マルチスレッドの場合、実行順序が保証されない • 通信では同一コネクションに対して、 順序を保証したいことがよくある • そんなときは、async_write()が使える • 好きなタイミングで呼べるasync_write()は 自分で実装する必要がある • キューイング処理とasync_writeハンドラに加え、 async_read()も合わせてstrandする必要がある
Download





![io_service
2016/7/23 8
#include <iostream>
#include <boost/asio.hpp>
int main() {
boost::asio::io_service ios;
ios.post([]{ std::cout << __LINE__ << std::endl; });
ios.post([]{ std::cout << __LINE__ << std::endl; });
ios.post([]{ std::cout << __LINE__ << std::endl; });
ios.post([]{ std::cout << __LINE__ << std::endl; });
ios.post([]{ std::cout << __LINE__ << std::endl; });
ios.run();
}
http://melpon.org/wandbox/permlink/MzfsrLNdJjfAeV15
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
11
12
様々な処理(ネットワーク、タイマ、シリアルポート、
シグナルハンドル、etc)をio_serviceにpost。
イベントが無くなるまで処理を実行
http://www.boost.org/doc/html/boost_asio/reference.html](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-8-320.jpg)
![io_service
2016/7/23 9
#include <iostream>
#include <boost/asio.hpp>
int main() {
boost::asio::io_service ios;
ios.post([&ios]{
std::cout << __LINE__ << std::endl;
ios.post([&ios]{
std::cout << __LINE__ << std::endl;
ios.post([&ios]{
std::cout << __LINE__ << std::endl;
});
});
});
ios.run();
}
http://melpon.org/wandbox/permlink/lXbFTVurVNUXM8BZ
7
9
11
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
処理の中で次のリクエストをpost](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-9-320.jpg)

![マルチスレッドにスケールアウト
2016/7/23 12
#include <iostream>
#include <thread>
#include <boost/asio.hpp>
int main() {
boost::asio::io_service ios;
ios.post([]{ std::cout << __LINE__ << std::endl; });
ios.post([]{ std::cout << __LINE__ << std::endl; });
ios.post([]{ std::cout << __LINE__ << std::endl; });
ios.post([]{ std::cout << __LINE__ << std::endl; });
ios.post([]{ std::cout << __LINE__ << std::endl; });
std::vector<std::thread> ths;
ths.emplace_back([&ios]{ ios.run(); });
ths.emplace_back([&ios]{ ios.run(); });
ths.emplace_back([&ios]{ ios.run(); });
ths.emplace_back([&ios]{ ios.run(); });
ths.emplace_back([&ios]{ ios.run(); });
for (auto& t : ths) t.join();
std::cout << "finished" << std::endl;
}
http://melpon.org/wandbox/permlink/z5bQJYgO23tvM9XF
8
9
10
11
7
finished
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
実行順序はpostの順序とは異なる](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-12-320.jpg)
{
// error checking ...
// 受信時の処理
}
);
boost::shared_lock<mutex> guard(mtx_subscribers_);
auto& idx = subscribers_.get<tag_topic>();
auto r = idx.equal_range(topic);
for (; r.first != r.second; ++r.first) {
auto& socket = r.first->socket;
boost::asio::write(socket, boost::asio::buffer(payload_));
}
全てのsubscriberに対して
publish内容を配信
msm導入前](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-18-320.jpg)
![msmとasioの組み合わせ
2016/7/23 23
struct a_pub {
template <typename Event, typename Fsm, typename Source, typename Target>
void operator()(Event const& e, Fsm& f, Source&, Target&) const {
ios.post([&f, e]{
boost::shared_lock<mutex> guard(f.mtx_subscribers_);
auto& idx = f.subscribers_.get<tag_topic>();
auto r = idx.equal_range(e.topic);
for (; r.first != r.second; ++r.first) {
auto& socket = r.first->socket;
boost::asio::write(socket, boost::asio::buffer(e.payload));
}
});
}
};
排他ロックの必要な範囲では、ios.post()のみ行い、
ios.post()に渡した処理が呼び出されるところで、
共有ロックを行う
subscribersubscriberpublish受信 subscriber
subscribersubscriberpublish受信 subscriber
post
post
postのみserialize 並行処理が可能](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-23-320.jpg)
![msmとasioの組み合わせ
2016/7/23 24
struct a_pub {
template <typename Event, typename Fsm, typename Source, typename Target>
void operator()(Event const& e, Fsm& f, Source&, Target&) const {
ios.post([&f, e]{
boost::shared_lock<mutex> guard(f.mtx_subscribers_);
auto& idx = f.subscribers_.get<tag_topic>();
auto r = idx.equal_range(e.topic);
for (; r.first != r.second; ++r.first) {
auto& socket = r.first->socket;
boost::asio::write(socket, boost::asio::buffer(e.payload));
}
});
}
};
排他ロックの必要な範囲では、ios.post()のみ行い、
ios.post()に渡した処理が呼び出されるところで、
共有ロックを行う
注意点
・処理の遅延に問題は無いか?
・ios.post()に渡した処理が参照するオブジェクトは生存しているか?](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-24-320.jpg)
![forループの処理もpostすれば。。。
2016/7/23 25
struct a_pub {
template <typename Event, typename Fsm, typename Source, typename Target>
void operator()(Event const& e, Fsm& f, Source&, Target&) const {
ios.post([&f, e]{
boost::shared_lock<mutex> guard(f.mtx_subscribers_);
auto& idx = f.subscribers_.get<tag_topic>();
auto r = idx.equal_range(e.topic);
for (; r.first != r.second; ++r.first) {
auto& socket = r.first->socket;
ios.post([&socket, e]{
boost::asio::write(socket, boost::asio::buffer(e.payload));
});
}
});
}
};
ループの中で行われるwrite()が並列化され、パフォーマンスの向上が見込める](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-25-320.jpg)
![struct a_pub {
template <typename Event, typename Fsm, typename Source, typename Target>
void operator()(Event const& e, Fsm& f, Source&, Target&) const {
ios.post([&f, e]{
boost::shared_lock<mutex> guard(f.mtx_subscribers_);
auto& idx = f.subscribers_.get<tag_topic>();
auto r = idx.equal_range(e.topic);
for (; r.first != r.second; ++r.first) {
auto& socket = r.first->socket;
ios.post([&socket, e]{
boost::asio::write(socket, boost::asio::buffer(e.payload));
});
}
});
}
};
forループの処理もpostすれば。。。
2016/7/23 26
publish受信 subscriber
post
postのみserialize
並行処理が可能
post
subscriber
subscriber
publish受信 subscriber
post
並行処理が可能
post
subscriber
subscriber
並行処理が可能
排他ロック 共有ロック](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-26-320.jpg)
![forループの処理もpostすれば。。。
2016/7/23 29
#include <iostream>
#include <thread>
#include <boost/asio.hpp>
int main() {
boost::asio::io_service ios;
ios.post([]{ std::cout << __LINE__ << std::endl; });
ios.post([]{ std::cout << __LINE__ << std::endl; });
ios.post([]{ std::cout << __LINE__ << std::endl; });
ios.post([]{ std::cout << __LINE__ << std::endl; });
ios.post([]{ std::cout << __LINE__ << std::endl; });
std::vector<std::thread> ths;
ths.emplace_back([&ios]{ ios.run(); });
ths.emplace_back([&ios]{ ios.run(); });
ths.emplace_back([&ios]{ ios.run(); });
ths.emplace_back([&ios]{ ios.run(); });
ths.emplace_back([&ios]{ ios.run(); });
for (auto& t : ths) t.join();
std::cout << "finished" << std::endl;
}
http://melpon.org/wandbox/permlink/z5bQJYgO23tvM9XF
8
9
10
11
7
finished
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
実行順序はpostの順序とは異なる](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-29-320.jpg)
![forループの処理もpostすれば。。。
2016/7/23 30
struct a_pub {
template <typename Event, typename Fsm, typename Source, typename Target>
void operator()(Event const& e, Fsm& f, Source&, Target&) const {
ios.post([&f, e]{
boost::shared_lock<mutex> guard(f.mtx_subscribers_);
auto& idx = f.subscribers_.get<tag_topic>();
auto r = idx.equal_range(e.topic);
for (; r.first != r.second; ++r.first) {
auto& socket = r.first->socket;
ios.post([&socket, e]{
boost::asio::write(socket, boost::asio::buffer(e.payload));
});
}
});
}
};
unsubscribe処理を行い、ackを返送した後に、この処理が実行されることがある](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-30-320.jpg)

![boost::asio::async_write
2016/7/23 33
template <typename F>
void my_async_write(
std::shared_ptr<std::string> const& buf,
F const& func) {
strand_.post(
[this, buf, func]
() {
queue_.emplace_back(buf, func);
if (queue_.size() > 1) return;
my_async_write_imp();
}
);
}
まずenque
データは、バッファと完了ハンドラ
未完了のasync_writeがあるなら
何もせず終了
async_writeの呼び出し処理
制約無く、いつでも呼べる、async_writeを作るには、
自前でキューイングなどの処理を実装する必要がある。](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-33-320.jpg)
![boost::asio::async_write
2016/7/23 34
void my_async_write_imp() {
auto& elem = queue_.front();
auto const& func = elem.handler();
as::async_write(
socket_,
as::buffer(elem.ptr(), elem.size()),
strand_.wrap(
[this, func]
(boost::system::error_code const& ec,
std::size_t bytes_transferred) {
func(ec);
queue_.pop_front();
if (!queue_.empty()) {
my_async_write_imp();
}
}
)
);
}
queueからデータを取り出して、
async_write
まだqueueにデータがあれば、
再びasync_write
queueからデータを消去し
strand_.post() および strand_.wrap() を用いて、
排他制御を行っている
queue_ だけ mutex でロックするのと何が違うのか?](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-34-320.jpg)
{
// error checking ...
// 受信時の処理
}
)
);
async_readもstrand経由で処理する](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-35-320.jpg)

![publish処理
2016/7/23 37
struct a_pub {
template <typename Event, typename Fsm, typename Source, typename Target>
void operator()(Event const& e, Fsm& f, Source&, Target&) const {
ios.post([&f, e]{
boost::shared_lock<mutex> guard(f.mtx_subscribers_);
auto& idx = f.subscribers_.get<tag_topic>();
auto r = idx.equal_range(e.topic);
for (; r.first != r.second; ++r.first) {
auto& socket = r.first->socket;
socket.my_async_write(boost::asio::buffer(e.payload), 完了ハンドラ);
}
});
}
};
自前の非同期writeを呼び出す
subscribe / unsubscribe の ack送信処理も、同様に、
自前の非同期writeを経由させることで、順序の入れ替わりを
防ぎ、かつ、処理の並列化を実現することができる](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-37-320.jpg)
![publish処理
2016/7/23 38
struct a_pub {
template <typename Event, typename Fsm, typename Source, typename Target>
void operator()(Event const& e, Fsm& f, Source&, Target&) const {
ios.post([&f, e]{
boost::shared_lock<mutex> guard(f.mtx_subscribers_);
auto& idx = f.subscribers_.get<tag_topic>();
auto r = idx.equal_range(e.topic);
for (; r.first != r.second; ++r.first) {
auto& socket = r.first->socket;
socket.my_async_write(boost::asio::buffer(e.payload), 完了ハンドラ);
}
});
}
};
自前の非同期writeを呼び出す
publish受信 subscriber
post
postのみserialize
並行処理が可能
かつ
同一接続に対しては
シリアライズ
my_async_write
subscriber
subscriber
publish受信 subscriber
post
subscriber
subscriber
並行処理が可能
排他ロック 共有ロック
my_async_write
並行処理が可能
かつ
同一接続に対しては
シリアライズ](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-38-320.jpg)
![publish処理
2016/7/23 39
struct a_pub {
template <typename Event, typename Fsm, typename Source, typename Target>
void operator()(Event const& e, Fsm& f, Source&, Target&) const {
ios.post([&f, e]{
boost::shared_lock<mutex> guard(f.mtx_subscribers_);
auto& idx = f.subscribers_.get<tag_topic>();
auto r = idx.equal_range(e.topic);
for (; r.first != r.second; ++r.first) {
auto& socket = r.first->socket;
socket.my_async_write(boost::asio::buffer(e.payload), 完了ハンドラ);
}
});
}
};
自前の非同期writeを呼び出す
非同期writeは十分に軽量であるため、forループの所要時間は短かった。
排他ロックの中で処理を行ってもパフォーマンスは落ちなかった。
よってシンプルな実装を採用した。(グレーの部分のコードを削除した)](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-39-320.jpg)
![publish処理
2016/7/23 40
struct a_pub {
template <typename Event, typename Fsm, typename Source, typename Target>
void operator()(Event const& e, Fsm& f, Source&, Target&) const {
ios.post([&f, e]{
boost::shared_lock<mutex> guard(f.mtx_subscribers_);
auto& idx = f.subscribers_.get<tag_topic>();
auto r = idx.equal_range(e.topic);
for (; r.first != r.second; ++r.first) {
auto& socket = r.first->socket;
socket.my_async_write(boost::asio::buffer(e.payload), 完了ハンドラ);
}
});
}
};
自前の非同期writeを呼び出す
publish受信 subscriber
post
postのみserialize
並行処理が可能
かつ
同一接続に対しては
シリアライズ
my_async_write
subscriber
subscriber
publish受信 subscriber
post
subscriber
subscriber
並行処理が可能
排他ロック 共有ロック
my_async_write
並行処理が可能
かつ
同一接続に対しては
シリアライズ](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-40-320.jpg)
![publish処理
2016/7/23 41
struct a_pub {
template <typename Event, typename Fsm, typename Source, typename Target>
void operator()(Event const& e, Fsm& f, Source&, Target&) const {
ios.post([&f, e]{
boost::shared_lock<mutex> guard(f.mtx_subscribers_);
auto& idx = f.subscribers_.get<tag_topic>();
auto r = idx.equal_range(e.topic);
for (; r.first != r.second; ++r.first) {
auto& socket = r.first->socket;
socket.my_async_write(boost::asio::buffer(e.payload), 完了ハンドラ);
}
});
}
};
自前の非同期writeを呼び出す
publish受信 subscriber
my_async_writeのみserialize
並行処理が可能
かつ
同一接続に対しては
シリアライズ
my_async_write
subscriber
subscriber
publish受信 subscriber
subscriber
subscriber
排他ロック
my_async_write
並行処理が可能
かつ
同一接続に対しては
シリアライズ](https://image.slidesharecdn.com/asiomsm-160723051113/85/Pub-Sub-model-msm-and-asio-41-320.jpg)










































