Download as PDF, PPTX






![Target of computation
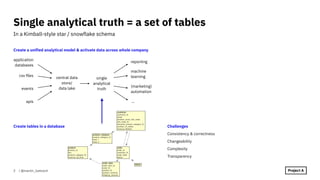
CREATE TABLE m_dim_next.region (
region_id SMALLINT PRIMARY KEY,
region_name TEXT NOT NULL UNIQUE,
country_id SMALLINT NOT NULL,
country_name TEXT NOT NULL,
_region_name TEXT NOT NULL
);
Do computation and store result in table
WITH raw_region
AS (SELECT DISTINCT
country,
region
FROM m_data.ga_session
ORDER BY country, region)
INSERT INTO m_dim_next.region
SELECT
row_number()
OVER (ORDER BY country, region ) AS region_id,
CASE WHEN (SELECT count(DISTINCT country)
FROM raw_region r2
WHERE r2.region = r1.region) > 1
THEN region || ' / ' || country
ELSE region END AS region_name,
dense_rank() OVER (ORDER BY country) AS country_id,
country AS country_name,
region AS _region_name
FROM raw_region r1;
INSERT INTO m_dim_next.region
VALUES (-1, 'Unknown', -1, 'Unknown', 'Unknown');
Speedup subsequent transformations
SELECT util.add_index(
'm_dim_next', 'region',
column_names := ARRAY ['_region_name', ‘country_name',
'region_id']);
SELECT util.add_index(
'm_dim_next', 'region',
column_names := ARRAY ['country_id', 'region_id']);
ANALYZE m_dim_next.region;
| @martin_loetzsch
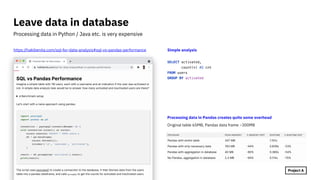
Tables as (intermediate) results of processing steps
Use SQL as a data processing language
8](https://image.slidesharecdn.com/2021-05-27howtobuildadatawarehouse-220221070828/85/Project-A-Data-Modelling-Best-Practices-Part-II-How-to-Build-a-Data-Warehouse-8-320.jpg)


![(Re)-creating data sets (schemas)
def re_create_data_set(next_bq_dataset_id=next_bq_dataset_id):
from mara_db.bigquery import bigquery_client
client = bigquery_client(bq_db_alias)
print(f'deleting dataset {next_bq_dataset_id}')
client.delete_dataset(dataset=next_bq_dataset_id,
delete_contents=True, not_found_ok=True)
print(f'creating dataset {next_bq_dataset_id}')
client.create_dataset(dataset=next_bq_dataset_id, exists_ok=True)
return True
Replacing data sets
def replace_dataset(db_alias, dataset_id, next_dataset_id):
from mara_db.bigquery import bigquery_client
client = bigquery_client(db_alias)
client.create_dataset(dataset=dataset_id, exists_ok=True)
next_tables = set([table.table_id for table
in client.list_tables(next_dataset_id)])
ddl = 'n'
for table in client.list_tables(dataset_id):
if table.table_id not in next_tables:
ddl += f'DROP TABLE `{dataset_id}`.`{table.table_id}`;'
# hopefully atomic operation
for table_id in next_tables:
ddl += f'CREATE OR REPLACE TABLE `{dataset_id}`.`{table_id}`
AS SELECT * FROM `{next_dataset_id}`.`{table_id}`;n'
ddl += f'DROP TABLE `{next_dataset_id}`.`{table_id}`;n'
client.query(ddl)
retries = 1
while True:
try:
client.delete_dataset(next_dataset_id)
return
except BadRequest as e:
if retries <= 10:
print(e, file=sys.stderr)
seconds_to_sleep = retries * 4
print(f'Waiting {seconds_to_sleep} seconds')
time.sleep(seconds_to_sleep)
retries += 1
else:
raise e
| @martin_loetzsch
https://github.com/mara/mara-db/blob/master/mara_db/bigquery.py#L124
Schema switches are a bit less nice in BigQuery
11](https://image.slidesharecdn.com/2021-05-27howtobuildadatawarehouse-220221070828/85/Project-A-Data-Modelling-Best-Practices-Part-II-How-to-Build-a-Data-Warehouse-11-320.jpg)

![It’s easy to make mistakes during ETL
DROP SCHEMA IF EXISTS s CASCADE; CREATE SCHEMA s;
CREATE TABLE s.city (
city_id SMALLINT,
city_name TEXT,
country_name TEXT
);
INSERT INTO s.city VALUES
(1, 'Berlin', 'Germany'),
(2, 'Budapest', 'Hungary');
CREATE TABLE s.customer (
customer_id BIGINT,
city_fk SMALLINT
);
INSERT INTO s.customer VALUES
(1, 1),
(1, 2),
(2, 3);
Customers per country?
SELECT
country_name,
count(*) AS number_of_customers
FROM s.customer JOIN s.city
ON customer.city_fk = s.city.city_id
GROUP BY country_name;
Back up all assumptions about data by constraints
ALTER TABLE s.city ADD PRIMARY KEY (city_id);
ALTER TABLE s.city ADD UNIQUE (city_name);
ALTER TABLE s.city ADD UNIQUE (city_name, country_name);
ALTER TABLE s.customer ADD PRIMARY KEY (customer_id);
[23505] ERROR: could not create unique index "customer_pkey"
Detail: Key (customer_id)=(1) is duplicated.
ALTER TABLE s.customer ADD FOREIGN KEY (city_fk)
REFERENCES s.city (city_id);
[23503] ERROR: insert or update on table "customer" violates foreign
key constraint "customer_city_fk_fkey"
Detail: Key (city_fk)=(3) is not present in table "city"
| @martin_loetzsch
Only very little overhead, will save your ass
Avoid happy path programming
13](https://image.slidesharecdn.com/2021-05-27howtobuildadatawarehouse-220221070828/85/Project-A-Data-Modelling-Best-Practices-Part-II-How-to-Build-a-Data-Warehouse-13-320.jpg)





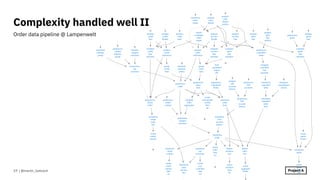










The document outlines best practices for data modeling and building data warehouses, emphasizing a unified analytical model and the importance of consistency and correctness. It discusses the use of SQL and data engineering techniques to maintain reproducibility, immutability, and to facilitate incremental data loading. The document also highlights the significance of employing standard software engineering practices to improve data pipeline efficiency and promote robust transformations.
































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

