




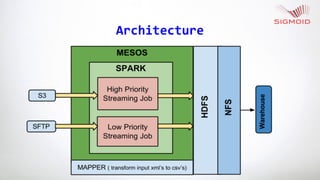










This document discusses using Mesos and Spark together to build a fault tolerant data pipeline. It outlines the architecture of connecting data sources to the pipeline, implementing multiple pipelines, ensuring high availability through Mesos, and performance monitoring. Learnings and a conclusion are also presented.





















































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)