Download to read offline




























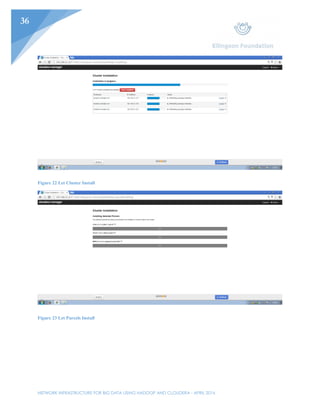

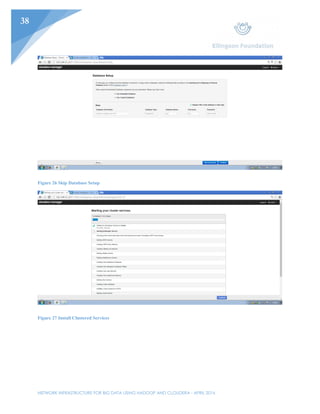

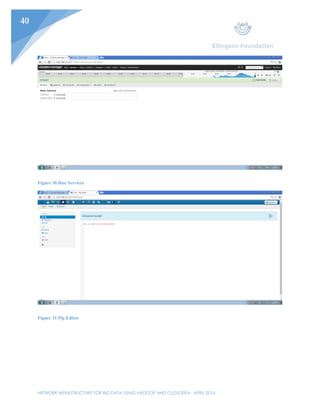

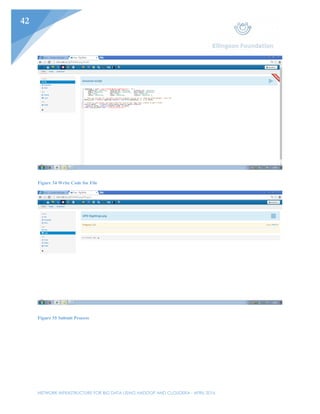



This document outlines the planning and implementation of a Hadoop cluster using Cloudera to process big data. Key points: - Three CentOS Linux machines will be configured into a Hadoop cluster managed by Cloudera to process large datasets. - Cloudera offers a GUI for managing Hadoop jobs, making it easier for users to process data than alternative options like Condor. - The cluster will allow for cost-effective scaling by adding additional nodes as data volumes increase, rather than requiring new hardware. - Implementation was done in VMware Workstation, with the first node used to install Cloudera and configure the other two cloned nodes and Windows client.

























































