Download as PDF, PPTX













![Past with multiset abstraction
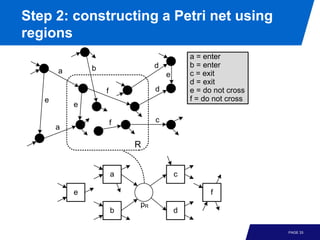
[a,e]
d
[a,d,e]
e [a,b]
a b
[] [a]
c c
b d
[a,c] [a,b,c] [a,b,c,d]
PAGE 31](https://image.slidesharecdn.com/processminingchapter06advancedprocessdiscoverytechniques-121219213521-phpapp01/85/Process-mining-chapter_06_advanced_process_discovery_techniques-32-320.jpg)
![Example
d
e
[a,e] [a,d,e]
[ a,b]
a b
[] [a] c
c
b d
[a,c] [a,b,c] [a,b,c,d]
b
a p1 e p3 d
start end
p2 c p4
PAGE 34](https://image.slidesharecdn.com/processminingchapter06advancedprocessdiscoverytechniques-121219213521-phpapp01/85/Process-mining-chapter_06_advanced_process_discovery_techniques-35-320.jpg)
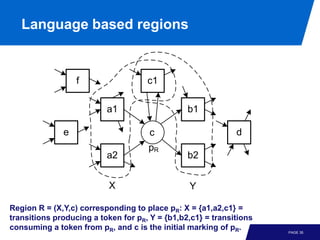
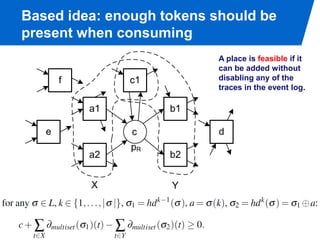


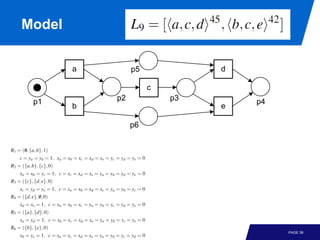



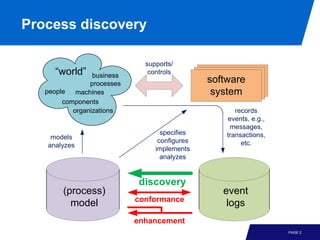
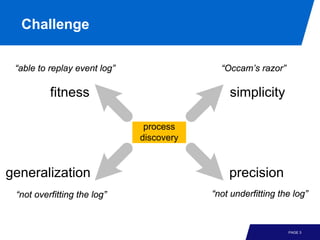
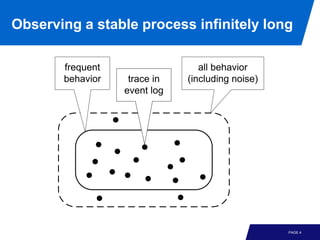
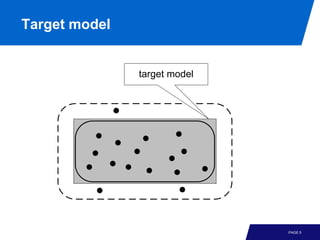
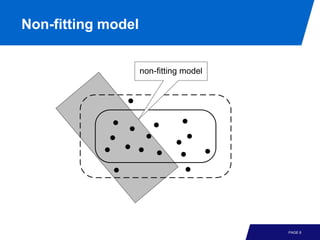
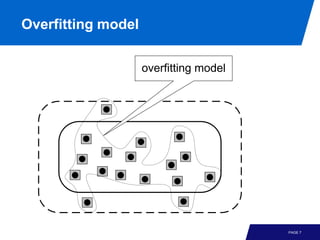
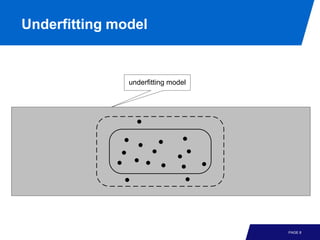
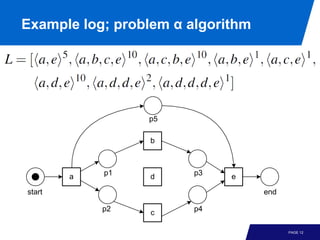
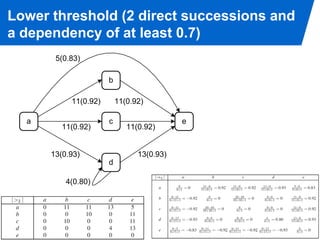
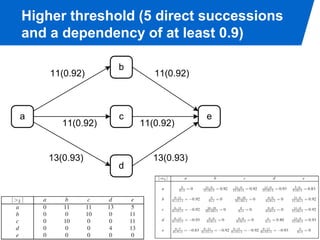
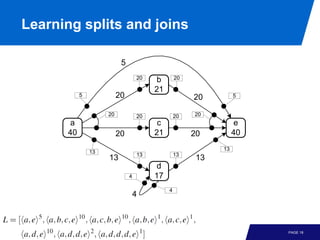
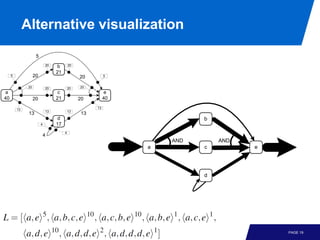
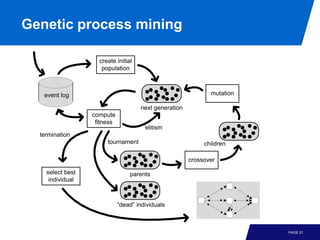
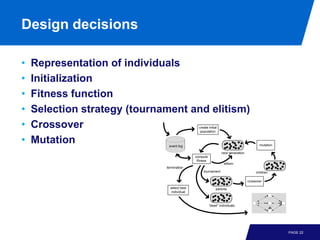
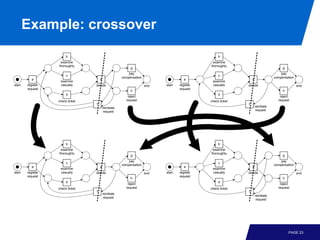
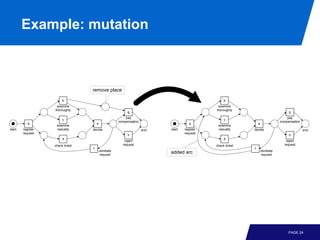
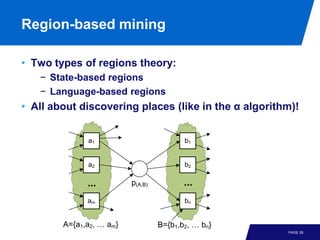
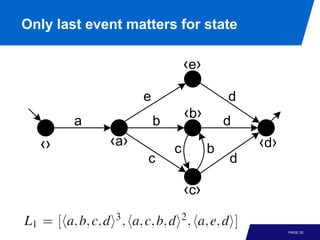
The document discusses advanced process discovery techniques. It begins by describing the challenges of process discovery, including the need for models to be able to replay event logs while avoiding overfitting or underfitting the logs. It then provides examples of algorithmic techniques like the heuristic miner and genetic process mining. Region-based process mining is also introduced. The document discusses characteristics of different process discovery algorithms and provides examples to illustrate concepts like heuristic mining, genetic operations, and region-based mining.


































