Downloaded 35 times



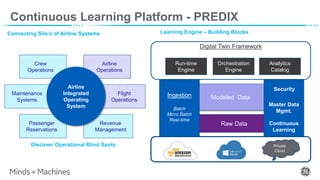
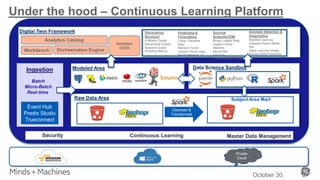



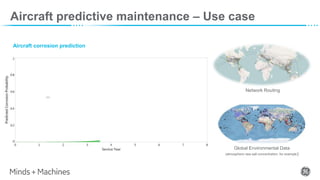
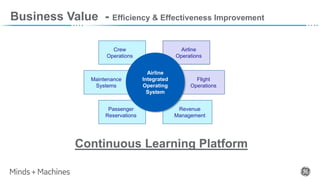


The document discusses Predix Data Fabric, which is the foundation for GE Aviation's continuous learning platform. It connects silos of airline systems data and enables ingestion from various sources in real-time, batch, and micro-batch formats. The continuous learning platform uses a digital twin framework and analytics catalog to perform functions like discovery, prediction, forecasting, and anomaly detection using techniques such as machine learning and deep learning. Two use cases are described: aircraft delay prediction to help airline disruption management, and aircraft corrosion prediction to enable predictive maintenance. The goal is to generate business value through efficiency and effectiveness improvements across airline operations.



































































