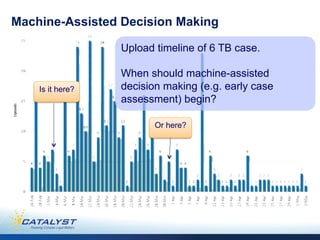
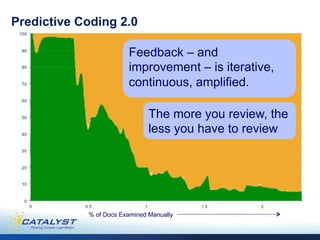
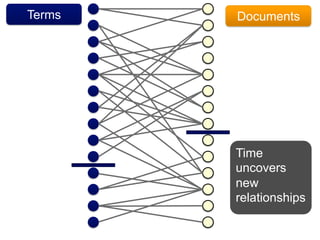
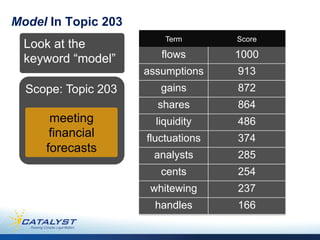
This document discusses predictive coding 2.0 as an improved method for e-discovery. Predictive coding 1.0 had limitations in dealing with incomplete document collections that are continuously updated and changing coding decisions. Predictive coding 2.0 uses a flexible analytics framework based on bipartite graphs that can adapt to changes in the document corpus and coding to enable continuous assessment of cases. This dynamic approach avoids early decisions based on incomplete information and allows for improved document review and concept suggestion over time. The authors provide examples of how predictive coding 2.0 could enhance e-discovery in complex litigation matters.