Prague Data ManagementMeetup
Data Management
Získávaní dat
Ukládání dat
Zpracování dat
Interpretace dat
Použití dat
• Otevřená profesionální zájmová
skupina
• Každý je vítán (ať už v pasivní
nebo aktivní roli)
• Témat není nikdy dost
• Snaha o pravidelné měsíční
setkávání
• Setkávání od září 2015
4.
Historie
# Datum Téma
110. 9. 2015 Data Management
2 14. 10. 2015 Data Lake
3 23. 11. 2015 Dark Data (without Dark Energy and Dark Force)
4 12. 1. 2016 Data Lake (znova)
5 7. 3. 2016 Sad Stories About DW Modeling (sad stories only)
6 23. 3. 2016 Self-service BI Street Battle
7 27. 4. 2016 Let's explore the new Microsoft PowerBI!
8 22. 9. 2016 Data Management pro začátečníky
# Datum Téma
9 17. 10. 2016 Small Big Data
10 22. 11. 2016 Základy modelování DW
11 23.1.2017 Komponenty datových skladů
12 28.2.2017 Operational Data Store
13 28.3.2017 Metadata v DW/BI
14 25.4.2017 Jak se stát DW/BI konzultantem
15 16.5.2017 SQL
16 29.5.2017 From IoT to AI: Applications of time series data
with Rudradeb Mitra
SQL je mocné4GL
Jazyk pro práci
s množinami
Jazyk pro
dotazování
Jazyk pro
definici
struktur
Jazyk pro
manipulaci s
daty
Jazyk pro
řízení
zpracování
Jazyk pro
řízení přístupů
k datům
Jazyk relační
databázi
Jazyk query
enginů
Jazyk s
procedurální
nadstavbou
Jazyk
integrovatelný
do 3GL
8.
Relační algebra =Teoretický základ SQL
• Množinové operátory
• Rozdíl => minus
• Sjednocení => union
• Průnik => intersect
• Symetrická diference
• Projekce
• Výběr sloupců z tabulky
• Selekce
• Where
• Výběr řádků z tabulek
• Přejmenování => alias
• Agregace
• Dělení
• Spojení
• Cross join
• Kartézký produkt
• Natural Join
• Stejné názvy sloupců
• Thetajoin Equijoin
• Inner join
• Semijoin
• Antijoin
• Outer join
• Right Outer Join
• Full outer join
9.
Structured Query Language(SQL)
• Otevřený programovací jazyk 4. generace
(další jsou např. QBE, JQuery ….)
• Silný teoretický základ – relační algebra
• Množinová orientace
• Silný deklarativní vývoj
• Až na výjimky při práci s texy není nutné
rozlišovat malá a velká písmena
• Jazyk pro práci s daty v relačních
databázích
• Čtení dat
• Zapisování dat
• Procedurální úlohy
• Ostatní úlohy
• Původní název SEQUEL
• Hawker Siddley trademark -> vynucená
změna názvu
• Standard ISO/IEC 9075
• Řada standardů (ANSI/ISO/IEC) a
„lokálních“ dialektů
• IBM DB2, Oracle DB, MySQL, MS SQL,
PostgreSQL…
• Historické milníky
• 1974 - vznik v laboratořích IBM
• 1979 - 1. komerční implementace Oracle V2
• 1986 – 1. standardizace (SQL-86)
• 1999 – dokončení nejdůležitějších částí SQL
(SQL:1999)
• 2011 – poslední rozšíření a standardizace
(SQL:2011)
10.
SQL Dialects
SQL DialectCommon name Full name
ANSI/ISO Standard SQL/PSM SQL/Persistent Stored Modules
Interbase / Firebird PSQL Procedural SQL
IBM DB2 SQL PL SQL Procedural Language (implements SQL/PSM)
IBM Informix SPL Stored Procedural Language
IBM Netezza NZPLSQL [2] (based on Postgres PL/pgSQL)
Microsoft / Sybase T-SQL Transact-SQL
Mimer SQL SQL/PSM SQL/Persistent Stored Module (implements SQL/PSM)
MySQL SQL/PSM SQL/Persistent Stored Module (implements SQL/PSM)
MonetDB SQL/PSM SQL/Persistent Stored Module (implements SQL/PSM)
NuoDB SSP Starkey Stored Procedures
Oracle PL/SQL Procedural Language/SQL (based on Ada)
PostgreSQL PL/pgSQL Procedural Language/PostgreSQL Structured Query Language (implements SQL/PSM)
Sybase Watcom-SQL SQL Anywhere Watcom-SQL Dialect
Teradata SPL Stored Procedural Language
SAP SAP HANA SQL Script
11.
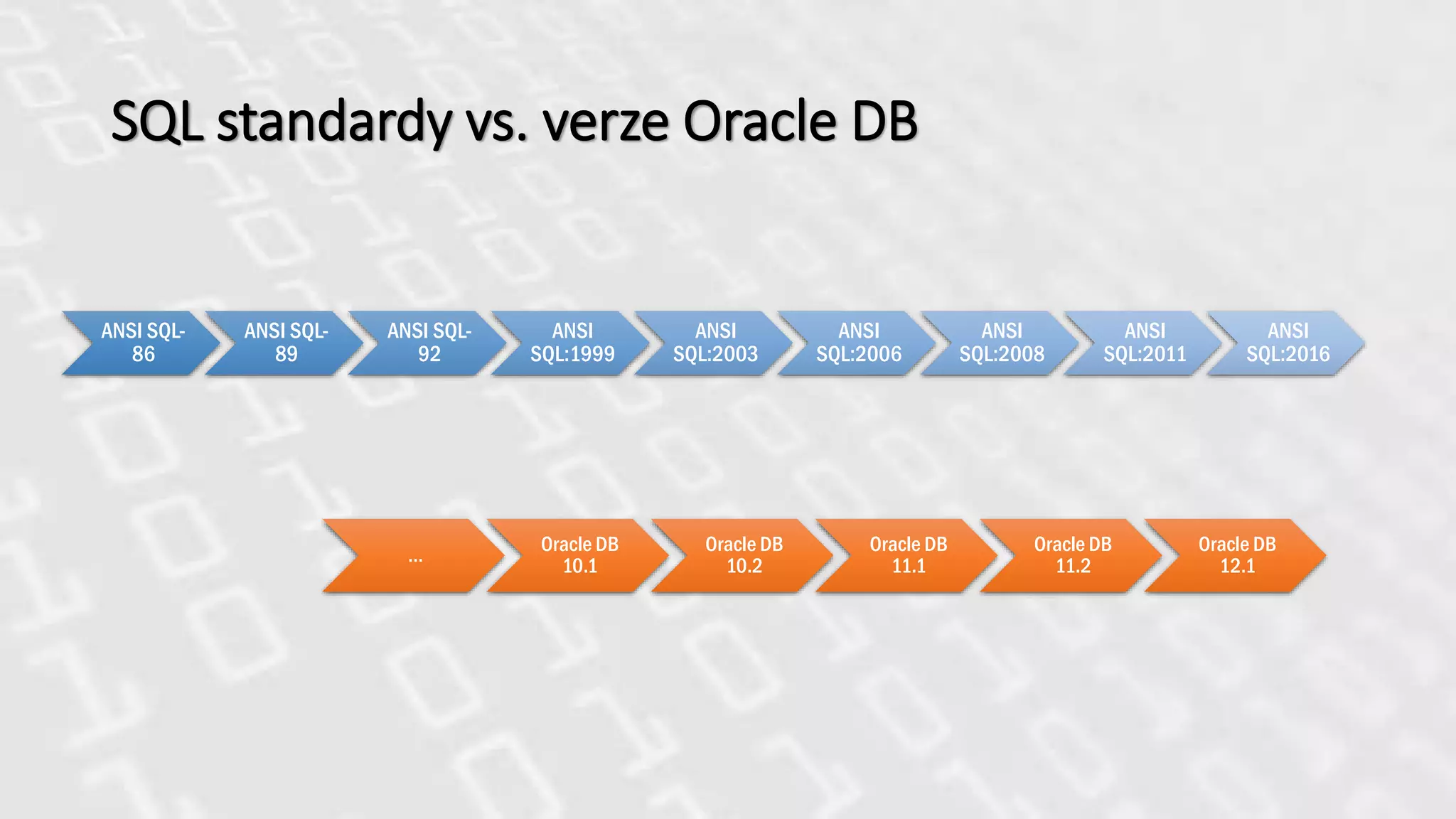
SQL standardy vs.verze Oracle DB
ANSI SQL-
86
ANSI SQL-
89
ANSI SQL-
92
ANSI
SQL:1999
ANSI
SQL:2003
ANSI
SQL:2006
ANSI
SQL:2008
ANSI
SQL:2011
ANSI
SQL:2016
…
Oracle DB
10.1
Oracle DB
10.2
Oracle DB
11.1
Oracle DB
11.2
Oracle DB
12.1
12.
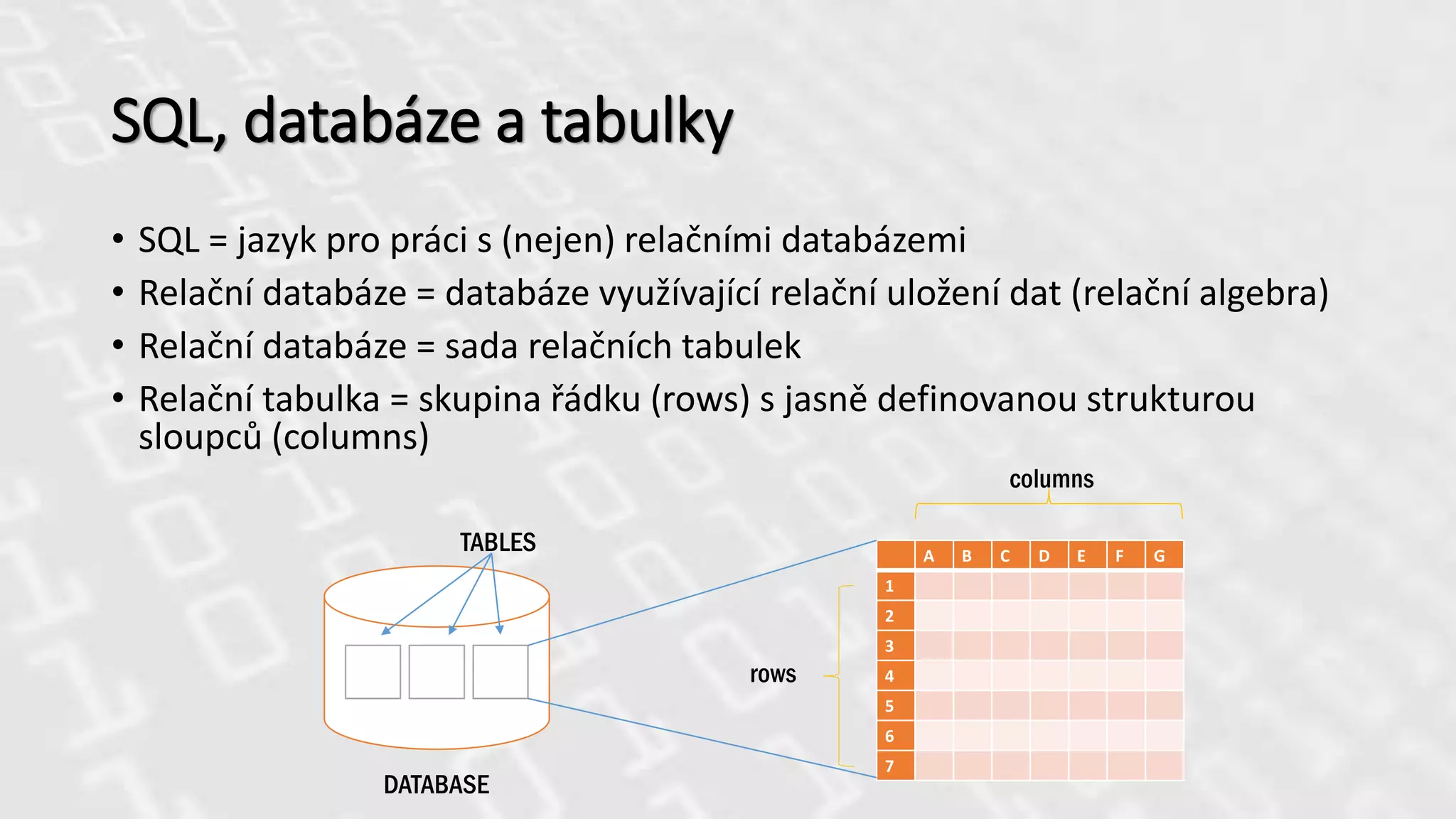
SQL, databáze atabulky
• SQL = jazyk pro práci s (nejen) relačními databázemi
• Relační databáze = databáze využívající relační uložení dat (relační algebra)
• Relační databáze = sada relačních tabulek
• Relační tabulka = skupina řádku (rows) s jasně definovanou strukturou
sloupců (columns)
A B C D E F G
1
2
3
4
5
6
7
DATABASE
TABLES
columns
rows
13.
Instance Party
INST_PT
Unified Party
UNI_PT
InstanceAddress
INST_ADDR
Product Instance
PROD_INST
Product Instance Party Role
PROD_INST_PT_ROLE
Product Instance Fact
PROD_INST_FACT
Business Product Type
BUS_PROD_TP
Big Table
BIG_TABLE
Business Product Class
BUS_PROD_CLASS
Party Type
PT_TP
Instance Party History
INST_PT_H
Party Role Type
PT_ROLE_TP
Demo model
Product Instance History
PROD_INST_H
UNI_PT_KEY
PT_TP_KEY
BUS_PROD_CLASS_KEYPROD_INST_KEY
INST_PT_KEY
INST_PT_KEY
PROD_INST_KEY
PROD_INST_KEY
PT_ROLE_TP_KEY
BUS_PROD_TP_KEY
INST_PT_KEY
14.
Instance Party
INST_PT
Product Instance
PROD_INST
ProductInstance Party Role
PROD_INST_PT_ROLE
Party Type
PT_TP
Relational Data Model vs. SQL
Select *
from
INST_PT
inner join PT_TP on PT_TP.PT_TP_KEY =
INST_PT.PT_TP_KEY
inner join PROD_INST_PT_ROLE on
PROD_INST_PT_ROLE.INST_PT_KEY = INST_PT.INST_PT_KEY
inner join PROD_INST on
PROD_INST_PT_ROLE.PROD_INST_KEY =
PROD_INST.PROD_INST_KEY
PT_TP_KEY
PROD_INST_KEY
INST_PT_KEY
SQL Structure
Data DefinitionLanguage (DDL). DDL statements create, modify, and remove database objects such as tables,
indexes, and users. Common DDL statements are:
• CREATE
• ALTER
• DROP
Data Manipulation Language (DML). DML is used to manipulate data within a table. Common DML statements
are:
• SELECT
• INSERT
• UPDATE
• DELETE
• MERGE
Data Control Language (DCL). DCL is used to control access to data stored in a database.
• GRANT
• REVOKE
17.
SQL Structure
Transaction ControlStatements (TCL)
• COMMIT
• ROLLBACK
• SAVEPOINT
• SET TRANSACTION
Session Control Statements (SCS)
• ALTER SESSION
• ALTER SYSTEM KILL SESSION ‘12’
Embedded SQL Statements
• DECLARE CURSOR
• OPEN
• CLOSE
• FETCH
• EXECUTE IMMEDIATE…
18.
DDL - DataDefinition Language
• to create objects in the databaseCREATE
• alters the structure of the databaseALTER
• delete objects from the databaseDROP
• remove all records from a table, including all spaces allocated for
the records are removed
TRUNCATE
• add comments to the data dictionaryCOMMENT
• rename an objectRENAME
Autocommit!
19.
DML – DataManipulation Language
• retrieve data from the a databaseSELECT
• insert data into a tableINSERT
• updates existing data within a tableUPDATE
• deletes all records from a table, the space for the records remainDELETE
• UPSERT operation (insert or update)MERGE
• call a PL/SQL or Java subprogramCALL/EXEC
• explain access path to the dataEXPLAIN PLAN
• controls concurrencyLOCK TABLE
No autocommit!
20.
DCL - DataControl Language
• gives user's access privileges to databaseGRANT
• withdraw access privileges given with the
GRANT commandREVOKE
21.
TCL - TransactionControl
• save work doneCOMMIT
• identify a point in a transaction to which you can later roll
backSAVEPOINT
• undo the modification made since the last COMMITROLLBACK
• Change transaction options like isolation level and what
rollback segment to useSET TRANSACTION
• set the current active rolesSET ROLE
22.
Transaction Control prakticky
SET
TRANSACTION
NAME'Update
INST_PT';
UPDATE
INST_PT SET
RC_NUM =
‘XIN’ WHERE
RC_NUM =
‘XER’ ;
SAVEPOINT
before_update;
UPDATE
INST_PT
SET RC_NUM =
‘XER’
WHERE
RC_NUM =
‘XIN’
ROLLBACK TO
SAVEPOINT
before_update;
UPDATE
INST_PT
SET RC_NUM =
‘XNA’
WHERE
RC_NUM =
‘XER’ ;
COMMIT
COMMENT
'Updated
INST_PT';
23.
Oracle SQL Vision
•The Language of Relational Databases
• Productive
• Simple syntax: SELECT, INSERT, UPDATE, DELETE, DROP, ALTER, GRANT
• Set based language – don’t write code to iterate
• Easy to relate sets of data using joins
• Separation of logical and physical
• Data independence – don’t code physical references
• Optimizers – don’t specify access methods because we can do it better
• Capabilities
• Transaction isolation and control
• Row level locking and concurrency
• Multi version read consistency
• Referential integrity
• Stored procedures (PL/SQL) and triggers
Vybrané zjednodušené syntaxeselectu
• Všechny sloupce z tabulky / view
• Select *
from
<tabulka>
• Vybrané sloupce z tabulky / view
• Select <seznam sloupců/výrazů>
from
<tabulka>
• Všechny sloupce ze skupiny tabulek / view
• Select *
from
<tabulka 1 propojení tabulka 2 propojení …>
• Vybrané sloupce ze skupiny tabulek / view
• Select <seznam sloupců/výrazů z tabulky 1, sloupců z tabulky 2>
from
<tabulka 1 propojení tabulka 2 propojení …>
• Všechny sloupce z tabulky / view pouze s řádky splňující
podmínky
• Select *
from
<tabulka>
where
<podmínky>
• Vybrané agregované sloupce z tabulky / view
• Select
<seznam sloupců/výrazů a agregačních funkcí>
from
<tabulka>
group by <seznam sloupců/výrazů>
• Všechny sloupce z tabulky / view v pořadí dle seznamu
sloupců
• select *
from
<tabulka/view>
order by
<seznam sloupců/výrazů>
• Select všech sloupců ze selectu s podmínkou
• Select *
from
(
select … from …
)
where
<podmínky>
26.
Tabulka DUAL
• Speciálníjednořádková a jednosloupcová tabulka
• Sloupec DUMMY varchar2(1) s hodnotou X
• Vždy existuje
• Příklady využití dualu:
Select * from dual;
Select sysdate from dual;
Select systimestamp from dual;
Select user from dual;
Select rownum from dual
connect by level < 4;
Select rownum from dual connect by
level < 4;
Select 1 from dual
union
select 2 dual
union
select 3 from dual;
select * from
(Select 1 from dual
Group by cube (1,1))
where rownum <= 3;
Alternativně
Select 1
27.
Komentáře
• Řádkový komentář„-- komentář“
• Select *
-- komentář
from dual -- tabulka dual
• Blokový komentář „/* komentář */“
• Select * /* komentář
komentář
komentář */ from
dual
• Hinty se píší podobně „/*+ */“, funkce zcela jiná!
• Select /*+ FIRST_ROWS(5) */ *
from dual
28.
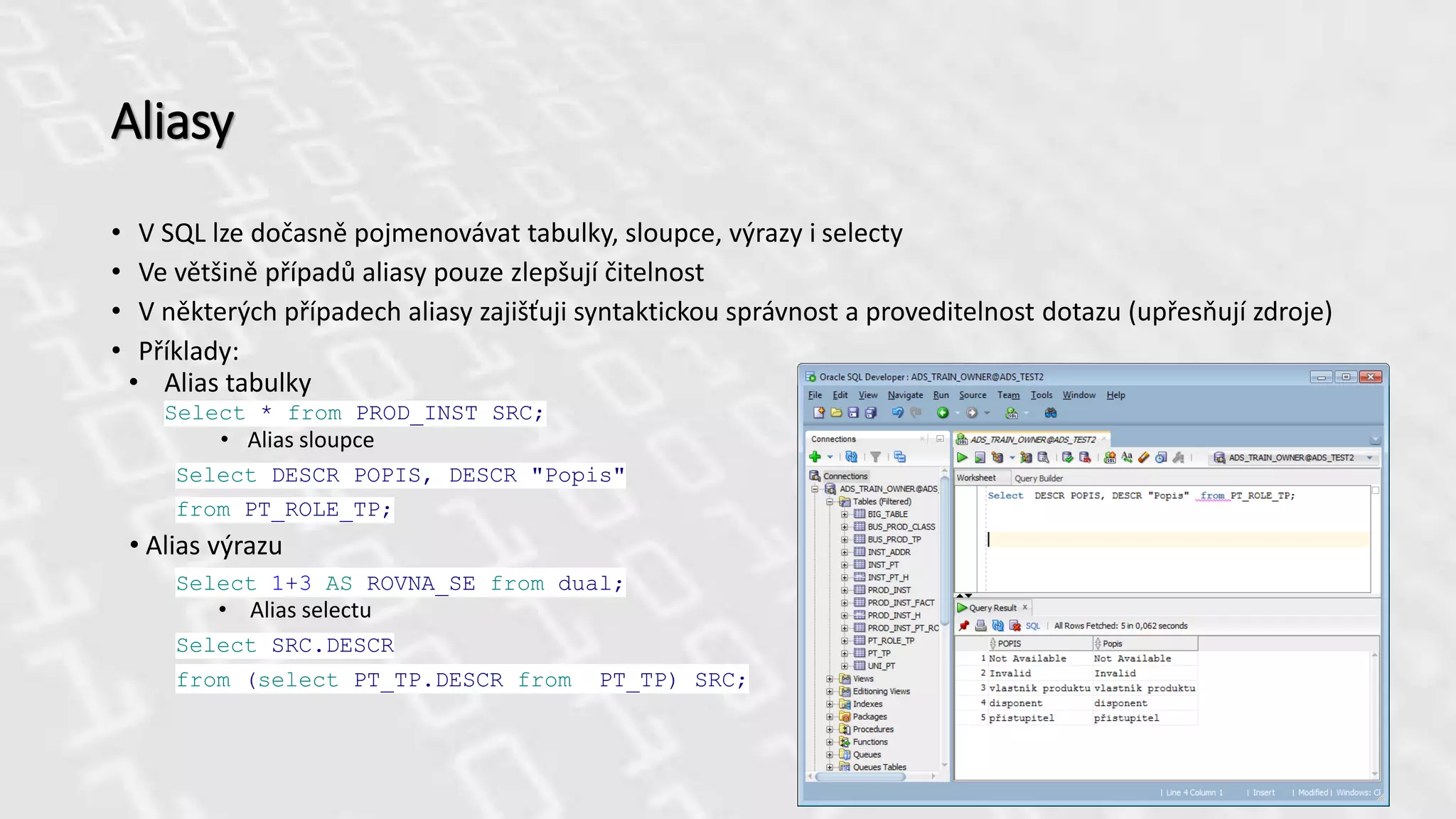
Aliasy
• V SQLlze dočasně pojmenovávat tabulky, sloupce, výrazy i selecty
• Ve většině případů aliasy pouze zlepšují čitelnost
• V některých případech aliasy zajišťuji syntaktickou správnost a proveditelnost dotazu (upřesňují zdroje)
• Příklady:
• Alias tabulky
Select * from PROD_INST SRC;
• Alias sloupce
Select DESCR POPIS, DESCR "Popis"
from PT_ROLE_TP;
• Alias výrazu
Select 1+3 AS ROVNA_SE from dual;
• Alias selectu
Select SRC.DESCR
from (select PT_TP.DESCR from PT_TP) SRC;
29.
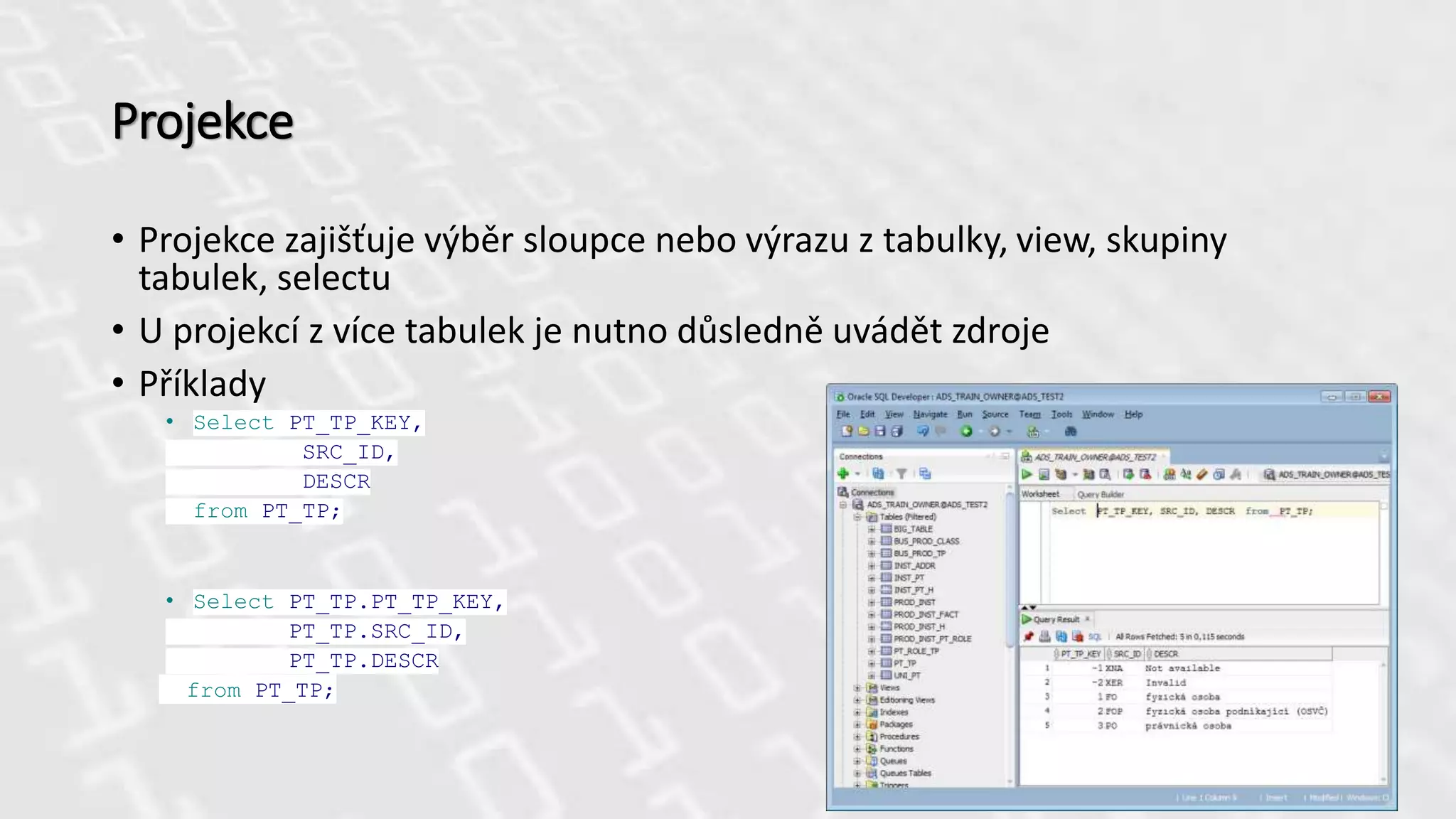
Projekce
• Projekce zajišťujevýběr sloupce nebo výrazu z tabulky, view, skupiny
tabulek, selectu
• U projekcí z více tabulek je nutno důsledně uvádět zdroje
• Příklady
• Select PT_TP_KEY,
SRC_ID,
DESCR
from PT_TP;
• Select PT_TP.PT_TP_KEY,
PT_TP.SRC_ID,
PT_TP.DESCR
from PT_TP;
30.
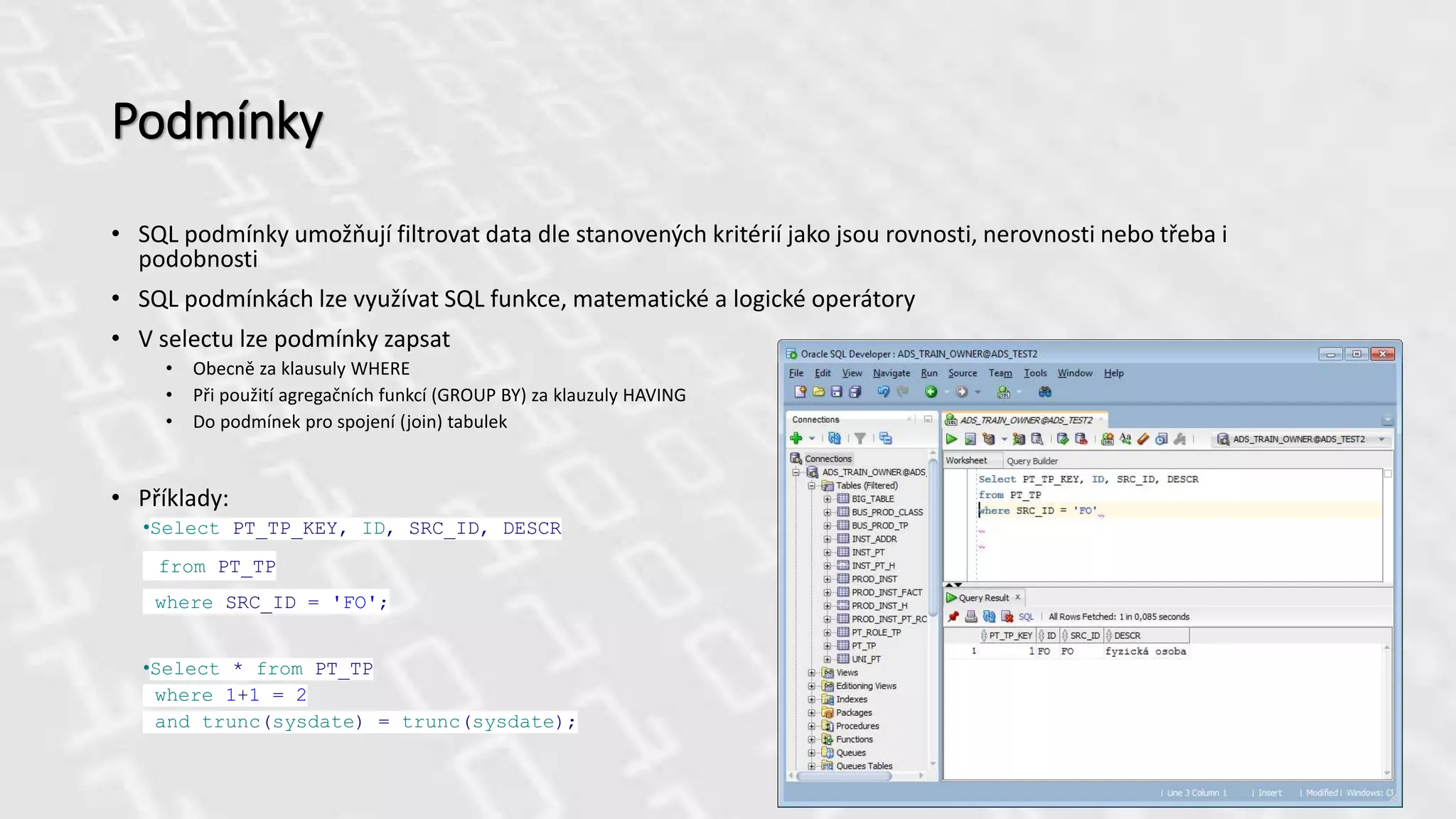
Podmínky
• SQL podmínkyumožňují filtrovat data dle stanovených kritérií jako jsou rovnosti, nerovnosti nebo třeba i
podobnosti
• SQL podmínkách lze využívat SQL funkce, matematické a logické operátory
• V selectu lze podmínky zapsat
• Obecně za klausuly WHERE
• Při použití agregačních funkcí (GROUP BY) za klauzuly HAVING
• Do podmínek pro spojení (join) tabulek
• Příklady:
•Select PT_TP_KEY, ID, SRC_ID, DESCR
from PT_TP
where SRC_ID = 'FO';
•Select * from PT_TP
where 1+1 = 2
and trunc(sysdate) = trunc(sysdate);
31.
Pokročilé řízení podmínek
•Někdy nutno zajistit řízení postupného vyhodnocování celé hierarchie podmínek v jednom výrazu
• Obdoba konstrukce „If then else “
•CASE
WHEN výraz1 THEN výsledek1
WHEN výraz2THEN výsledek2
…
ELSE výsledek3
END
Case
•CASE výraz
WHEN hodnota1 THEN výsledek1
WHEN hodnota 2 THEN výsledek2
…
ELSE výsledek3
END
Case
• DECODE(výraz,hodnota1,výsledek1,hodnota2, výsledek2,…,
výsledek3)Decode
32.
NULL v SQL
NULL• je nic, ale není to nula
NULL v Oraclu
• není roven ničemu
• ani sám sobě
Vždy FALSE: • NULL = NULL
Pokud se zjišťuje
rovnost nullů
• NULL IS NULL
• column IS NULL (negace IS NOT NULL)
Lze ho dělit nulou! • select null / 0 from dual vrací null
Výjimka je SQL
funkce DECODE
• null s rovná se funguje
• DECODE(A,NULL,’PRAVDA’,’NEPRAVDA’)
Platí primárně pro Oracle DB, v jiných DB může být popsané chování jiné
Příklady:
Select * from INST_PT where RC_NUM is null;
Select * from INST_PT where RC_NUM is not null;
33.
NVL
• Základní SQLfunkce k eliminaci null (existují i další složitější)
• Syntaxe
• NVL(<sloupec nebo výraz>, <náhradní hodnota>);
• Příklady:
Select RC_NUM, ICO_NUM,
NVL( RC_NUM,ICO_NUM)
AS ID,
NVL(RC_NUM,'NONE ' ‚)
AS RC_NUM2
from INST_PT;
41
34.
• Zástupné znakyumožňují jednoduché podobnostní prohledávání
textových řetězců pomocí operátoru LIKE
Zástupné znaky (wildcards)
• SELECT *
FROM inst_pt
WHERE family_name LIKE 'Nov_k';
Jeden znak
• SELECT *
FROM inst_pt
WHERE family_name LIKE 'N%k';
Více znaků
• SELECT *
FROM inst_pt
WHERE family_name LIKE '_o%k';
Kombinace jednoho
a více znaků
• SELECT *
FROM inst_pt
WHERE family_name LIKE '%o%';
Komplexní
prohledávání
• SELECT *
FROM inst_pt
WHERE family_name LIKE '%o_v%' escape '' ;
Escapování
zástupných znaků
35.
Operátory pro tvorbypodmínek a výrazů
Aritmetické operace +
-
/
*
Spojování textových
řetězců
||
Příklady:
Select 158/6 from dual;
Select 3*8 from dual;
Select 'A' || 'B' from dual;
36.
Operátory pro tvorbypodmínek a výrazů
Porovnání
> , >=
=<. <
=
ANY/SOME „ve výčtu – ANSI“
IN/NOT IN „ve výčtu - Oracle“
BETWEEN/NOT BETWEEN „mezi“
LIKE/NOT LIKE
EXISTS „ve výčtu“
IS (NOT) NULL
Logické
operátory
NOT „negace“
AND
OR
Příklady:
Select * from INST_PT where INST_PT_KEY >= 3 or INST_PT_KEY in (-1,-2);
Select * from INST_PT where INST_PT_KEY between 1 and 5;
Distinct
• Tento sloupcovýoperátor zajistí deduplikaci řádků pro uvedenou kombinaci sloupců
• Dvě možná klíčová slova:
• DISTINCT – Oracle
• UNIQUE - ANSI
• Syntaxe
• SELECT DISTINCT <seznam sloupců>
FROM <tabulka>;
• SELECT UNIQUE <seznam sloupců>
FROM <tabulka>;
• Příklad
• Select distinct RC_NUM, FAMILY_NAME, FIRST_NAME from INST_PT;
• Poznámka
• K deduplikaci musí DB udělat třídění – potenciálně velmi náročná operace
39.
Subdotazy
• Pro selectlze použít i jiný select jako podmínku
• Základní klíčová slova
• IN / NOT IN
• EXISTS / NOT EXISTS
• SOME / NOT SOME
• ANY / NOT ANY
• Ekvivalentní příklady:
• Select * from INST_PT where INST_PT_KEY in
(select INST_PT_KEY from PROD_INST_PT_ROLE);
• SELECT inst_pt_key FROM inst_pt
• WHERE EXISTS
• (SELECT 1 FROM PROD_INST_PT_ROLE
• WHERE inst_pt.inst_pt_key =prod_inst_pt_role.inst_pt_key);
50
40.
Subdotazy
• In /Exists / Any / Some jsou zaměnitelné
• IN je z Oracle SQL
• EXISTS z ANSI
• NOT IN a NOT EXISTS se liší => NOT IN je null sensitive
• Data vrátí:
• SELECT inst_pt_key
• FROM inst_pt
• WHERE inst_pt_key NOT IN (1, 2);
• Data nevrátí
• SELECT inst_pt_key
• FROM inst_pt
• WHERE inst_pt_key NOT IN (1, 2, NULL);
• Srovnání NOT IN a NOT EXISTS:
• SELECT inst_pt_key FROM inst_pt WHERE NOT EXISTS (select 1 from INST_PT FILTER where FILTER.RC_NUM =
INST_PT.ICO_NUM);
• Vrátí nějaké řádky
• select inst_pt_key from inst_pt WHERE ICO_NUM not in (select RC_NUM from INST_PT where RC_NUM is not null);
• Nic nevrátí
41.
Funkce
• Funkce jsouvestavěné předpisy pro transformaci vstupních dat
• Typy funkcí:
• Skalární - pro jeden řádek vrací jednu hodnotu
• substr - vyberte část řetězce z celého řetězce
• to_date - převede řetězec na datum
• round - zaokrouhlí číslo
• Skupinové – pro více řádků vrací jednu hodnotu
• max - vybere maximální hodnotu ze skupiny
• avg - vybere průměrnou hodnotu ze skupiny
• Funkce lze používat pro
• Definování výrazů sloužící jako výstupní sloupce ze selectu
• Definování filtrovacích podmínek ve where
• Definovaní joinů mezi tabulkami
42.
Vybrané skalární funkce
•sysdate - vypíše aktuální datum a čas
• Select sysdate from dual;
• to_date – převede řetězec na datum
• Select to_date ('10.2.2015', 'DD.MM.YYYY') from dual;
• to_char – převede hodnotu na řetězec
• Select to_char(sysdate, 'YYYYMM') from dual;
• to_number – převede řetězec na číslo (pozor na vliv NLS)
• Select to_number('0001,1') from dual;
• round - zaokrouhlí číslo
• Select round(2.2548494,1) from dual;
• cast – převede vstupní hodnotu na zvolený datový typ
• Select cast (sysdate as timestamp) from dual;
• trunc - ořízne vstupní hodnotu
• Select trunc (sysdate, 'YYYY') from dual;
• Select trunc(10/3) from dual;
43.
Vybrané skalární funkce
•substr - vybere část řetězce
• Select substr('abcdef',3,2) from dual;
• Instr - prohledá řetězec a najde počátek subřetězce
• Select instr('abcdef', 'c') from dual;
• trim - ořízne vstupní řetězec o mezery na konci a začátku
• Select trim(' 458A ') from dual;
• lpad - doplní řetězec o úvodní znaky
• Select lpad('abcdef',10,'x') from dual;
• replace - nahradí textový řetězec jiným řetězcem
• Select replace('abcdef', 'de', 'yz') from dual;
• months_between – vypočítá rozdíl mezi dvěma datumy
• Select months_between(sysdate, date '2010-5-15') from dual;
• last_day - datum převede na poslední datum v měsíci
• Select last_day(sysdate) from dual;
44.
Vybrané skupinové funkce
•Avg - vypočítá ze skupiny průměr
• Min - vypočítá ze skupiny minimum
• Max - vypočítá ze skupiny maximum
• Median - vypočítá ze skupiny medián
• Count - vypočítá ze skupiny počet řádků
• Sum - vypočítá ze skupiny sumu
SELECT avg(num_val) avg ,
median(num_val) med,
min(date_val) min,
max(date_val) max,
count(*) cnt,
sum(num _val) sum
FROM big_table;
45.
Množinové operátory
• Spojenídvou množin řádků
• Defaultně deduplikace zdvojených řádků
• ALL => vypnutí deduplikace
UNION [ALL]
Průnik dvou množin řádků
Defaultně deduplikace zdvojených řádkůINTERSECT
• Výběr řádků, které jsou pouze v první množině, ale nejsou ve
druhéMINUS
Poznámka: ORDER BY lze použít za posledním
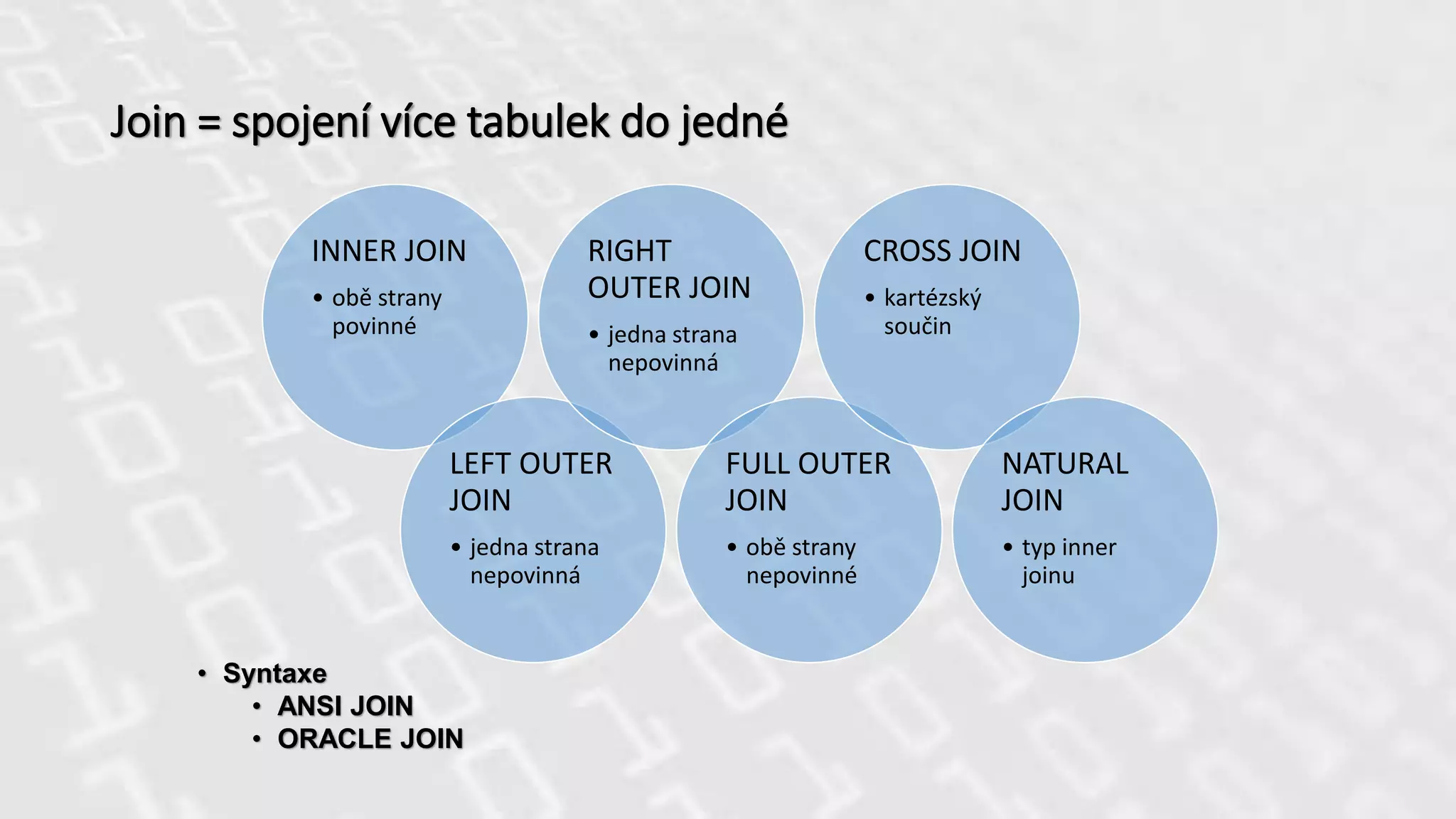
Join = spojenívíce tabulek do jedné
INNER JOIN
• obě strany
povinné
LEFT OUTER
JOIN
• jedna strana
nepovinná
RIGHT
OUTER JOIN
• jedna strana
nepovinná
FULL OUTER
JOIN
• obě strany
nepovinné
CROSS JOIN
• kartézský
součin
NATURAL
JOIN
• typ inner
joinu
• Syntaxe
• ANSI JOIN
• ORACLE JOIN
48.
Inner join /join
Table_1 Table_2
select *
from Table_1 inner join Table_2 on Table_1.Column_1 =
Table_2.Column_2;
select *
from Table_1 join Table_2 on Table_1.Column_1 =
Table_2.Column_2;
select *
from Table_1, Table_2 where Table_1.Column_1 = Table_2.Column_2;
49.
Left outer join/ left join
Table_1 Table_2
select *
from Table_1 left outer join Table_2 on Table_1.Column_1 =
Table_2.Column_2;
select *
from Table_1 left join Table_2 on Table_1.Column_1 =
Table_2.Column_2;
select *
from Table_1, Table_2 where Table_1.Column_1 = Table_2.Column_2
(+);
50.
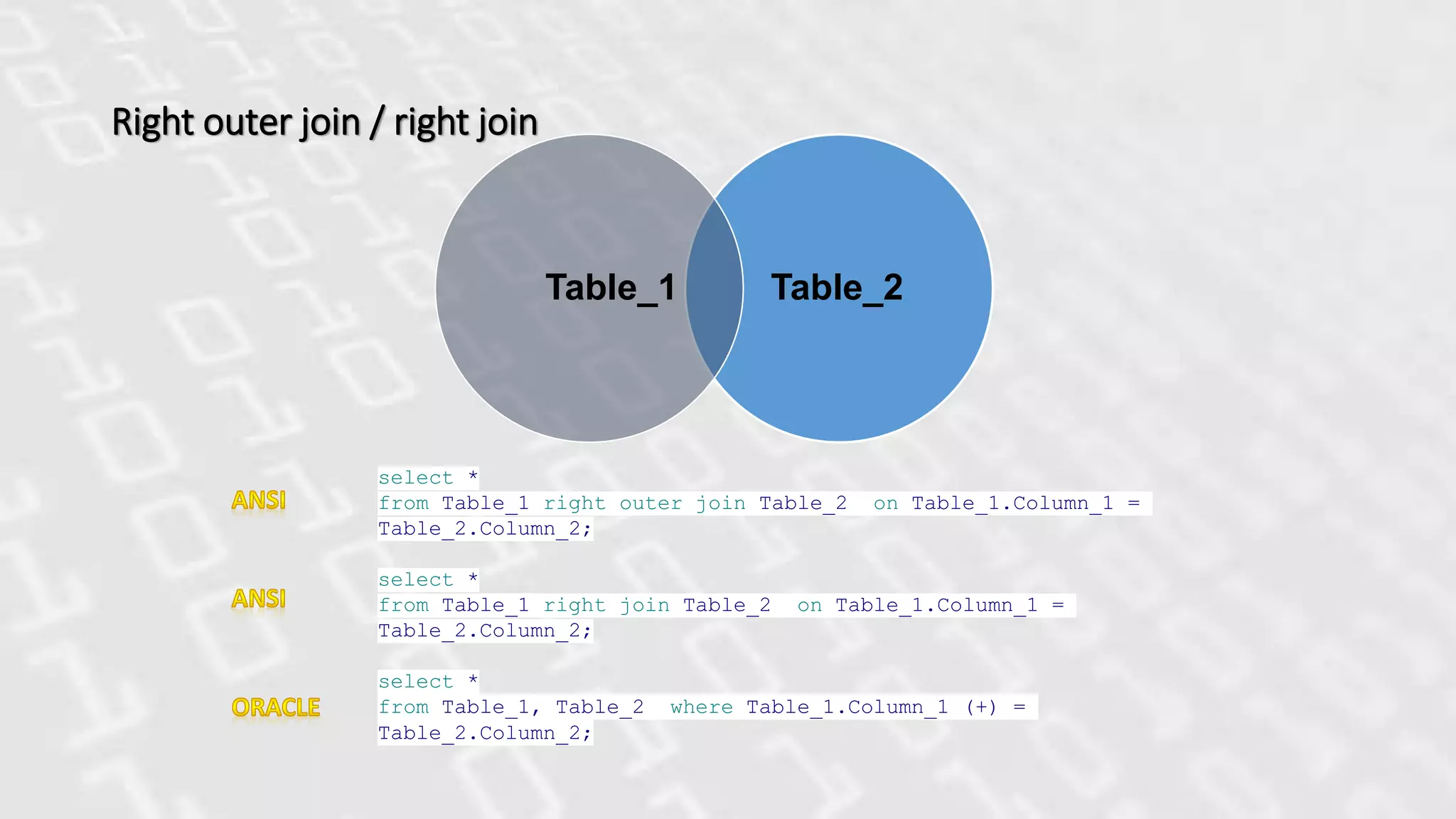
Right outer join/ right join
Table_2Table_1
select *
from Table_1 right outer join Table_2 on Table_1.Column_1 =
Table_2.Column_2;
select *
from Table_1 right join Table_2 on Table_1.Column_1 =
Table_2.Column_2;
select *
from Table_1, Table_2 where Table_1.Column_1 (+) =
Table_2.Column_2;
51.
Full outer join/ full join
Table_1 Table_2
select *
from Table_1 full outer join Table_2 on Table_1.Column_1 =
Table_2.Column_2;
select *
from Table_1 full join Table_2 on Table_1.Column_1 =
Table_2.Column_2;
Nelze přímo, nutno řešit jako union mezi left a right joinem
Self inner join
Table_1Table_1
select *
from Table_1 Alias_1inner join Table_1 Alias_2 on
Alias_1.Column_1 = Alias_2.Column_2;
select *
from Table_1 Alias_1, Table_1 Alias_2where
Alias_1.Column_1 = Alias_2.Column_2;
54.
Natural join
Table_1 Table_2
select*
from Table_1
natural join Table_2;
Specifický inner join
Spojení dle všech stejně
pojmenovaných sloupců
bez ohledu na obsah
55.
Použítí using vjoinech
• Zjednodušení joinování při stejných názvech sloupců v tabulkách
• Omezení v použití sloupce
• Nelze použít univerzálně *
• Sloupec z usingu je ve výstupu pouze jednou
• Syntaxe
SELECT <joinovací sloupce>, <ostatní sloupce>
FROM <table_1> <zvolený typ joinu> <table_2> USING
(<joinovací sloupce oddělené čárkou>);
56.
Semijoin
• Souvztažné selecty= výsledek jednoho joinu řídí výsledek druhého
• Lze použít:
• EXISTS
• IN
• Běžný JOIN v kombinaci s řízenou deduplikací
Select *
from INST_PT
where (INST_PT_KEY,SRC_SYS_ID) in
(select INST_PT_KEY, SRC_SYS_ID
from PROD_INST_PT_ROLE)
Select *
from INST_PT
where EXISTS (
Select 1
from PROD_INST_PT_ROLE
where
PROD_INST_PT_ROLE.INST_PT_KEY =
INST_PT.INST_PT_KEY
and PROD_INST_PT_ROLE.SRC_SYS_ID =
INST_PT.SRC_SYS_ID
)
57.
Antijoin
SELECT inst_pt.inst_pt_key FROM
inst_pt, prod_inst_pt_role WHERE
inst_pt.inst_pt_key =
prod_inst_pt_role.inst_pt_key (+)
AND prod_inst_pt_role.prod_inst_key
IS NULL;
SELECT inst_pt_key FROM inst_pt
WHERE inst_pt_key NOT IN (SELECT
inst_pt_key FROM prod_inst_pt_role);
SELECT inst_pt_key
FROM inst_pt
WHERE NOT EXISTS ( SELECT 1 FROM
prod_inst_pt_role
WHERE
prod_inst_pt_role.inst_pt_key =
inst_pt.inst_pt_key);
SELECT inst_pt.inst_pt_key
FROM inst_pt
LEFT OUTER JOIN prod_inst_pt_role
ON
inst_pt.inst_pt_key =
prod_inst_pt_role.inst_pt_key WHERE
prod_inst_pt_role.prod_inst_key IS
NULL;
Pozor na null v NOT IN!!!! (nevrátí se pak nic)
58.
Full outer joinvs. minus
• Select INST_PT_KEY
from INST_PT
minus
Select INST_PT_KEY
from PROD_INST_PT_ROLE;
• Select INST_PT.INST_PT_KEY, PROD_INST_PT_ROLE.PROD_INST_KEY
from INST_PT
full outer join PROD_INST_PT_ROLE
on INST_PT.INST_PT_KEY = PROD_INST_PT_ROLE.INST_PT_KEY
where PROD_INST_PT_ROLE.INST_PT_KEY is null ;
• Výkon většinou srovnatelný
• Dostupnost všech klíčů u full outer joinu narozdíl od minusu
• Minus lze vnitřně provést jako minus nebo jako většinou rychlejší antijoin
• 11g defaultně vypnutý v důsledku chyby v hashovaní
59.
Group by
GROUP BY
GROUPBY
CUBE
GROUP BY
HAVING
GROUP BY
ROLLUP
GROUP BY
GROUPING
SET
Funkce pro „zlepšení popis“ výstupu
GROUPING GROUPING_ID GROUP_ID
SELECT <column_name>, <aggregating_operation>
FROM <table_name>
GROUP BY <column_name>
HAVING <aggregating_op_result> <condition> <value>;
• Group by a jeho varianty umožňují agregovat
skupiny řádků do jednoho výsledného
• S group by lze použít agregační funkce
• Having funguje velmi podobně jako where
60.
Agregační funkce
• PrůměrAVG()
•Počet unikátních prvkůCOUNT(DISTINCT)
• PočetCOUNT()
• MaximumMAX()
• MinimumMIN()
• SumaSUM()
• Standardní odchylkaSTD()
• RozptylVARIANCE()
61.
Příklad agregace pomocígroup by
77
ID GRP AMT
1 A 2
2 A 4
3 A 4
4 B 8
DUMMY_TAB
GRP Max(AMT) Min(AMT) Avg(AMT) Sum(AMT) Count(*)
A 4 2 3,33333 10 3
B 8 8 8 8 1
Select
GRP,
max(AMT),
min(AMT),
avg(AMT),
sum(AMT),
count(*)
From
DUMMY_TAB
Group by GRP
62.
Příklad agregace pomocígroup by having
78
ID GRP AMT
1 A 2
2 A 4
3 A 4
4 B 8
DUMMY_TAB
GRP Max(AMT) Min(AMT) Avg(AMT) Sum(AMT) Count(*)
A 4 2 3,33333 10 3
Select
GRP,
max(AMT),
min(AMT),
avg(AMT),
sum(AMT),
count(*)
From
DUMMY_TAB
Group by GRP
Having count(*) > 1
63.
Order by
Order umožňujeurčit pořadí v jakém jsou záznamy na
výstupu ze selectu
ASC
Vzestupné třídění
ASC je default.
DESC
Sestupné třídění.
NULLS FIRST
Nully jsou uvedené
jako první až poté
následují setříděná
data
NULLS LAST
Nully jsou uvedené
jako poslední po
setříděných datech
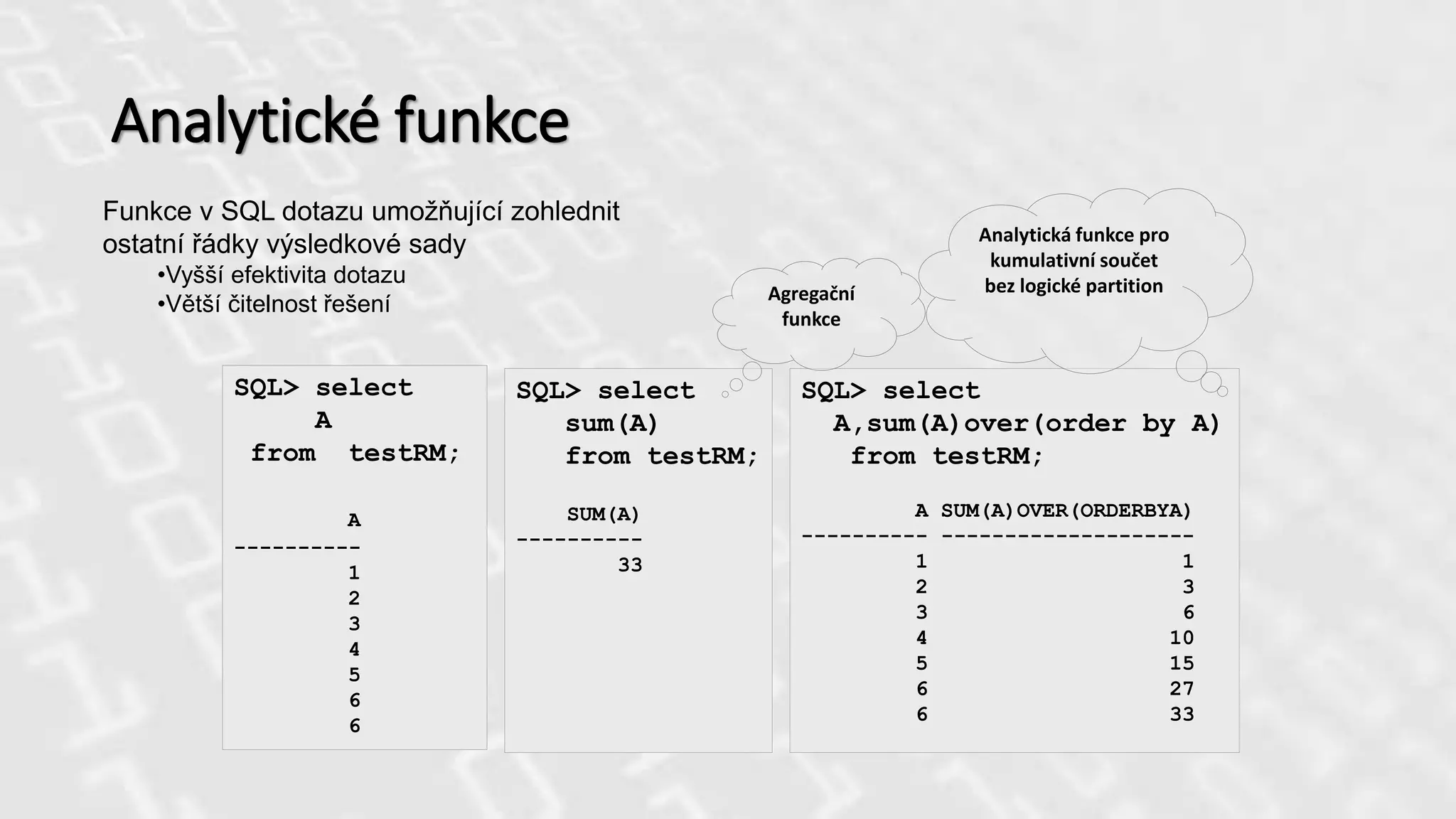
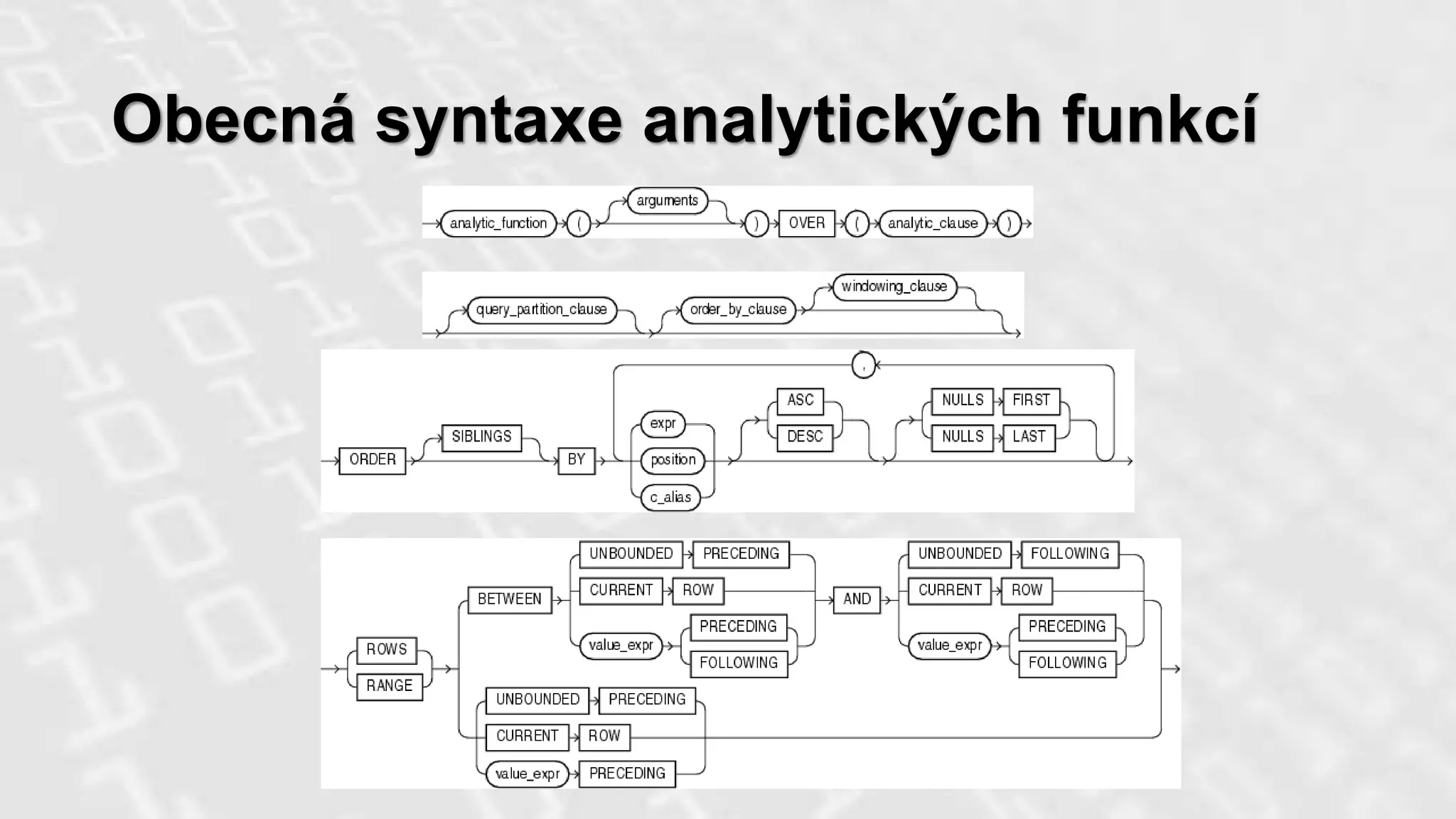
Analytické funkce
Funkce vSQL dotazu umožňující zohlednit
ostatní řádky výsledkové sady
•Vyšší efektivita dotazu
•Větší čitelnost řešení
SQL> select
A
from testRM;
A
----------
1
2
3
4
5
6
6
SQL> select
sum(A)
from testRM;
SUM(A)
----------
33
SQL> select
A,sum(A)over(order by A)
from testRM;
A SUM(A)OVER(ORDERBYA)
---------- --------------------
1 1
2 3
3 6
4 10
5 15
6 27
6 33
Agregační
funkce
Analytická funkce pro
kumulativní součet
bez logické partition
Row Limiting
• Od12c lze omezovat výstup z selectu pouze na první řadky bez nutnosti aplikaci analytických
funkcí nebo rownum
• Prvních pět řádků:
• SELECT employee_id, last_name FROM employees ORDER BY employee_id FETCH FIRST 5 ROWS ONLY;
• Šestý až desátý řádek:
• SELECT employee_id, last_name FROM employees ORDER BY employee_id OFFSET 5 ROWS FETCH NEXT 5 ROWS
ONLY;
• Prvních 5% řádků:
• SELECT employee_id, last_name, salary FROM employees ORDER BY salary FETCH FIRST 5 PERCENT ROWS ONLY;
• Prvních 5% řádků plus všechny ty, které mají stejnou hodnotu salary jako poslední řádek z původní
množiny
• SELECT employee_id, last_name, salary FROM employees ORDER BY salary FETCH FIRST 5 PERCENT ROWS WITH
TIES;
89
70.
Regulární výrazy
• POSIX
•REGEXP_LIKE
• REGEXP_SUBSTR
• REGEXP_REPLACE
• REGEXP_COUNT
• SELECT REGEXP_SUBSTR('One|Two|Three|Four|Five','[^|]+', 1,3) FROM dual;
• select REGEXP_SUBSTR('One|Two|Three|Four|Five','[^|]{1,}',1,level) from (select 'One|Two|Three|Four|Five'
text, regexp_count ('One|Two|Three|Four|Five','[^|]{1,}') cnt from dual) connect by level <= cnt
71.
Příklady
• SELECT REGEXP_REPLACE('500Oracle Parkway, Redwood Shores, CA', '( ){2,}', ' ') RESULT
FROM DUAL;
• 500 Oracle Parkway, Redwood Shores, CA
• SELECT REGEXP_REPLACE('George McGovern', '([[:lower:]])([[:upper:]])', '1 2') CITY
FROM DUAL;
• George Mc Govern
• SELECT REGEXP_REPLACE('We are trying to make the subject easier.','.',' for you.') REGEXT_SAMPLE
FROM DUAL;
• We are trying to make the subject easier for you.
• SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA', ',[^,]+,') RESULT
FROM DUAL;
• , Redwood Shores,
• SELECT REGEXP_SUBSTR('Go to http://www.oracle.com/products and click on database',
'http://([[:alnum:]]+.?){3,4}/?') RESULT
FROM DUAL;
• http://www.oracle.com/










![SQL Dialects
SQL Dialect Common name Full name
ANSI/ISO Standard SQL/PSM SQL/Persistent Stored Modules
Interbase / Firebird PSQL Procedural SQL
IBM DB2 SQL PL SQL Procedural Language (implements SQL/PSM)
IBM Informix SPL Stored Procedural Language
IBM Netezza NZPLSQL [2] (based on Postgres PL/pgSQL)
Microsoft / Sybase T-SQL Transact-SQL
Mimer SQL SQL/PSM SQL/Persistent Stored Module (implements SQL/PSM)
MySQL SQL/PSM SQL/Persistent Stored Module (implements SQL/PSM)
MonetDB SQL/PSM SQL/Persistent Stored Module (implements SQL/PSM)
NuoDB SSP Starkey Stored Procedures
Oracle PL/SQL Procedural Language/SQL (based on Ada)
PostgreSQL PL/pgSQL Procedural Language/PostgreSQL Structured Query Language (implements SQL/PSM)
Sybase Watcom-SQL SQL Anywhere Watcom-SQL Dialect
Teradata SPL Stored Procedural Language
SAP SAP HANA SQL Script](https://image.slidesharecdn.com/praguedatamanagementmeetup2017-05-16-170529205123/75/Prague-data-management-meetup-2017-05-16-10-2048.jpg)





















![Pořadí vyhodnocování operátorů
Unární operátory + -
PRIOR operator
* / [aritmetické operátory]
Binární operátory + - , || [spojení textů]
Porovnání
NOT](https://image.slidesharecdn.com/praguedatamanagementmeetup2017-05-16-170529205123/75/Prague-data-management-meetup-2017-05-16-37-2048.jpg)







![Množinové operátory
• Spojení dvou množin řádků
• Defaultně deduplikace zdvojených řádků
• ALL => vypnutí deduplikace
UNION [ALL]
Průnik dvou množin řádků
Defaultně deduplikace zdvojených řádkůINTERSECT
• Výběr řádků, které jsou pouze v první množině, ale nejsou ve
druhéMINUS
Poznámka: ORDER BY lze použít za posledním](https://image.slidesharecdn.com/praguedatamanagementmeetup2017-05-16-170529205123/75/Prague-data-management-meetup-2017-05-16-45-2048.jpg)



















![Regulární výrazy
• POSIX
• REGEXP_LIKE
• REGEXP_SUBSTR
• REGEXP_REPLACE
• REGEXP_COUNT
• SELECT REGEXP_SUBSTR('One|Two|Three|Four|Five','[^|]+', 1,3) FROM dual;
• select REGEXP_SUBSTR('One|Two|Three|Four|Five','[^|]{1,}',1,level) from (select 'One|Two|Three|Four|Five'
text, regexp_count ('One|Two|Three|Four|Five','[^|]{1,}') cnt from dual) connect by level <= cnt](https://image.slidesharecdn.com/praguedatamanagementmeetup2017-05-16-170529205123/75/Prague-data-management-meetup-2017-05-16-70-2048.jpg)
![Příklady
• SELECT REGEXP_REPLACE('500 Oracle Parkway, Redwood Shores, CA', '( ){2,}', ' ') RESULT
FROM DUAL;
• 500 Oracle Parkway, Redwood Shores, CA
• SELECT REGEXP_REPLACE('George McGovern', '([[:lower:]])([[:upper:]])', '1 2') CITY
FROM DUAL;
• George Mc Govern
• SELECT REGEXP_REPLACE('We are trying to make the subject easier.','.',' for you.') REGEXT_SAMPLE
FROM DUAL;
• We are trying to make the subject easier for you.
• SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA', ',[^,]+,') RESULT
FROM DUAL;
• , Redwood Shores,
• SELECT REGEXP_SUBSTR('Go to http://www.oracle.com/products and click on database',
'http://([[:alnum:]]+.?){3,4}/?') RESULT
FROM DUAL;
• http://www.oracle.com/](https://image.slidesharecdn.com/praguedatamanagementmeetup2017-05-16-170529205123/75/Prague-data-management-meetup-2017-05-16-71-2048.jpg)
















































