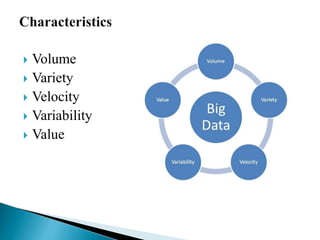
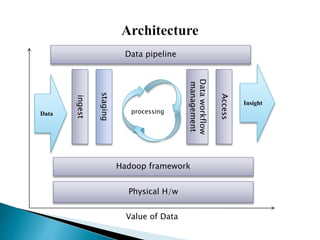
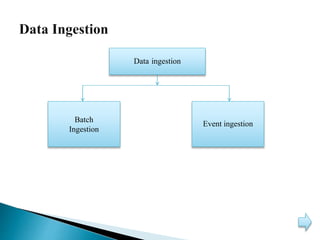
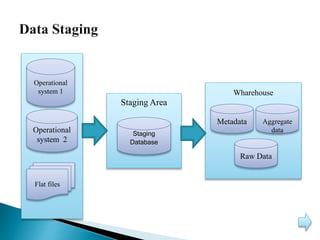
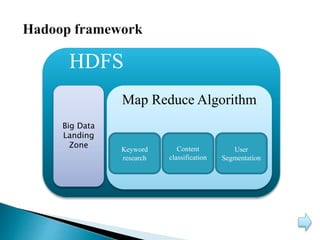
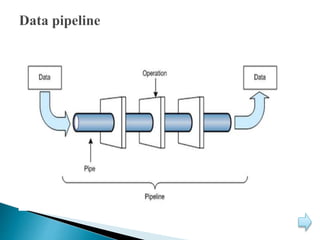
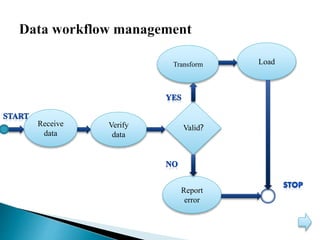
This document discusses big data, including its characteristics, architecture, challenges, types, applications, and benefits. Big data is defined as data that exceeds storage and processing capabilities due to its large volume, variety, and velocity. The architecture of big data involves data ingestion, staging, processing using Hadoop frameworks, data pipelines, and workflow management on physical hardware. Big data brings benefits like improved customer engagement and personalization through analysis of structured, semi-structured, and unstructured data from various sources in industries like healthcare, education, and banking.










![[1].S. Madden From Databases to Big Data IEEE
Internet Computing, 16 (2012 June), pp.4-6
[2].Apache Software Foundation. Official Website
www.Apache.hadoop.org.
[3].Jeffrey Dean and Sanjay Chemawat,“MapReduce:
Simplified Data Processing On Large Clusters”,
CACM Jan. 2008 (PDF).](https://image.slidesharecdn.com/pptbigdata4-170403052944/85/Pptbig-data4-17-320.jpg)


























![Big_Data_ppt[1] (1).pptx](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatappt11-230720100552-10b674be-thumbnail.jpg?width=640&height=640&fit=bounds)




































