Downloaded 19 times







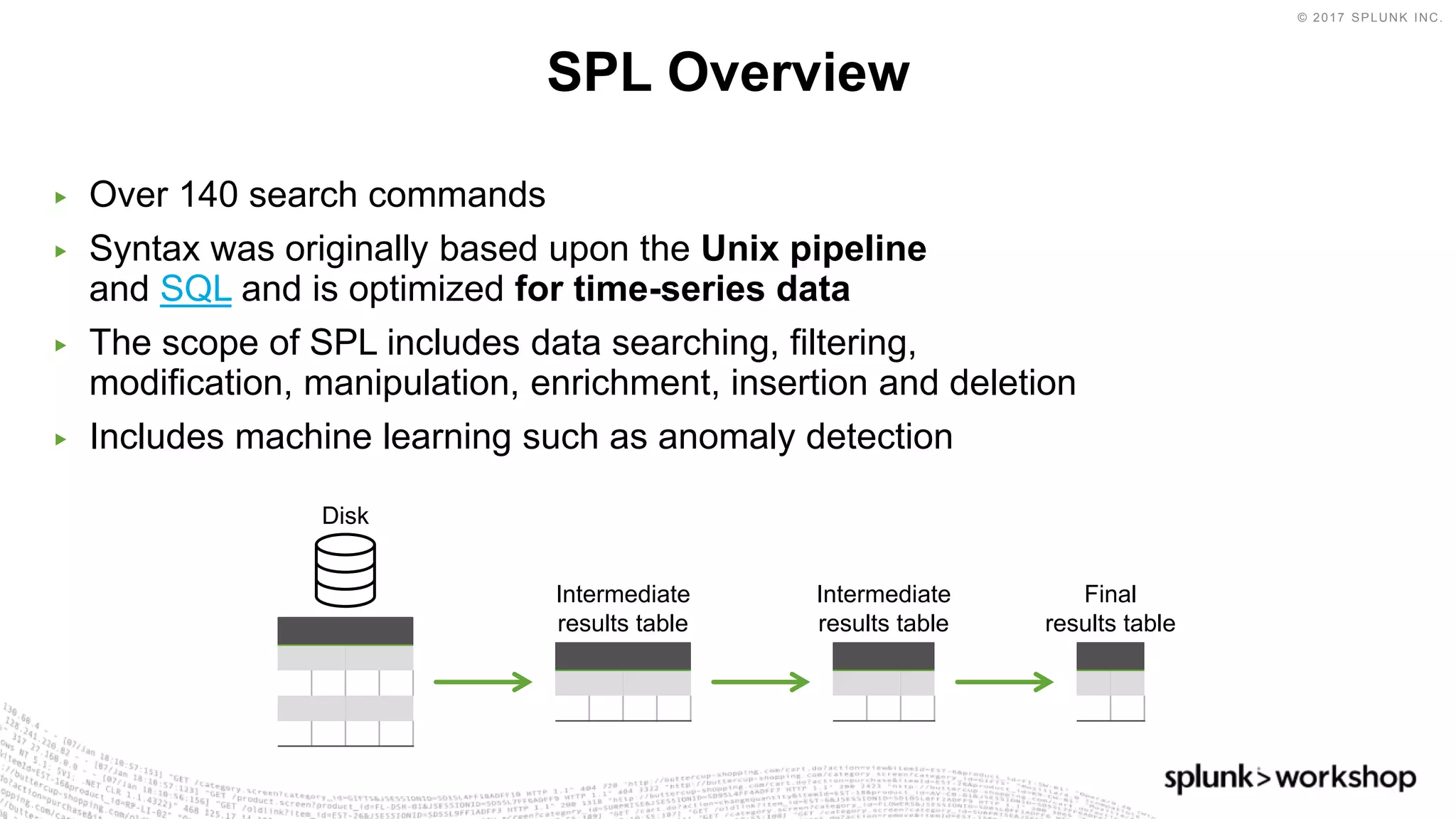









































The document discusses Splunk's Search Processing Language (SPL) and provides examples of how to use SPL commands. It covers SPL's over 140 search commands for data searching, filtering, manipulation and more. The presentation agenda includes an overview of SPL, examples of SPL commands for searching, charting, converging data sources, identifying anomalies, and custom visualizations. It also discusses using SPL with Splunk's Machine Learning Toolkit.























































































