





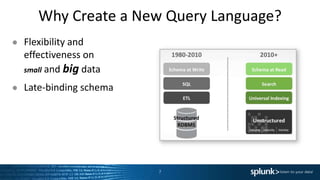

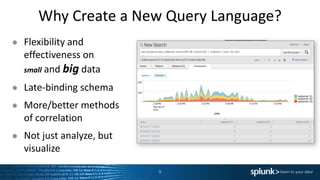






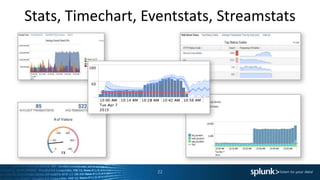


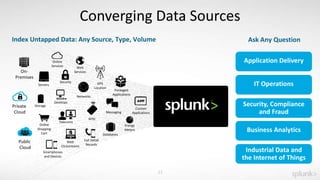





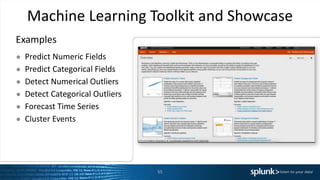


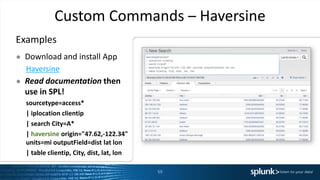




The presentation discusses the capabilities of Splunk's Search Processing Language (SPL), including its structure, commands, and applications for data analysis and visualization. It highlights the flexibility of SPL in handling small and large data and includes examples of specific use cases for searching, charting, and anomaly detection. Additionally, there are discussions about creating and using custom commands to extend SPL functionality.











































































































