










![LOS Weather Service
Input: [a wgs84:Point; wgs84:lat ?lat; wgs84:long ?long]
Output:[met:weatherObservation [
weather:hasStationID ?icao
geonames:inCountry ?country;
...
weather:hasWindEvent
[weather:windDirection ?windDirection],
[weather:windSpeed ?windSpeed]](https://image.slidesharecdn.com/planetdatasimpda-110812041222-phpapp02/85/PlanetData-Consuming-Structured-Data-at-Web-Scale-15-320.jpg)







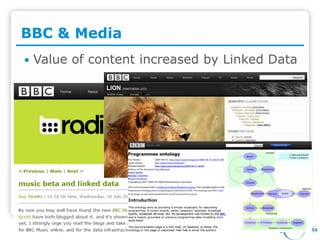
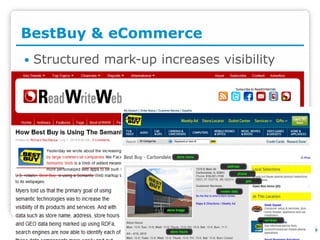
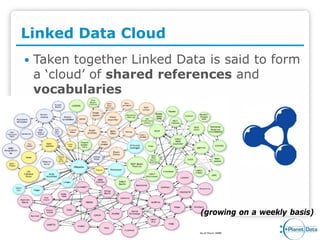
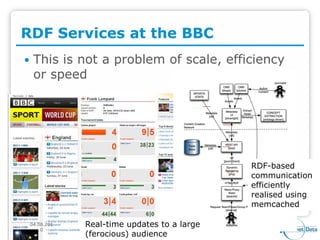
PlanetData aims to establish a sustainable European community focused on large-scale data management, emphasizing data exposure, web mining, and technological integration. The document outlines objectives such as quality assessment, data provenance, and the promotion of linked data principles, including the use of URIs and RDF. It also highlights frameworks for publishing and managing data and describes the development of services and applications over linked data within an interdisciplinary context.









![Who is doing what, and how do we know? [PEPRS]](https://cdn.slidesharecdn.com/ss_thumbnails/who-is-doing-what-100623032001-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































































































