Download to read offline















![Program readability
1 to: array size do: [ :i | (array at: i) yourself ].
array do: [ :elem | elem yourself ].
array do: #yourself.](https://image.slidesharecdn.com/4-vmperformance-170607110952/85/Pharo-VM-Performance-17-320.jpg)
![Program readability
1 to: array size do: [ :i | (array at: i) yourself ].
array do: [ :elem | elem yourself ].
array do: #yourself.
0 2 5 20
87M/
sec
28M/
sec
13M/
sec
3.7M
/sec
15M/
sec
21M/
sec
10M/
sec
3.9M
/sec
94M/
sec
40M/
sec
22M/
sec
6.5M
/sec](https://image.slidesharecdn.com/4-vmperformance-170607110952/85/Pharo-VM-Performance-18-320.jpg)
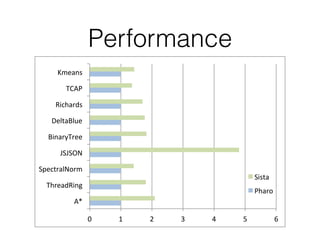

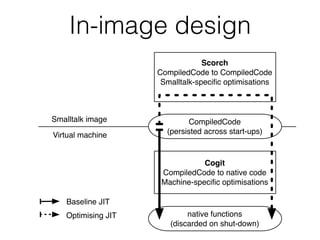





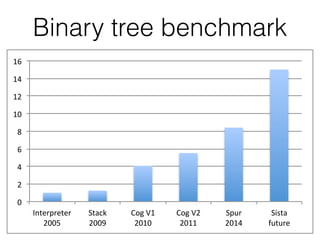
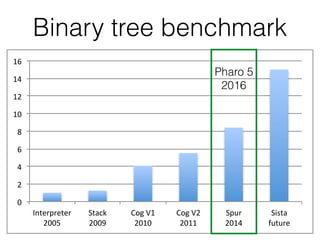
This document summarizes the history and future plans for optimizations to the Pharo virtual machine (VM). It discusses past improvements like Spur in Pharo 5 that provided 1.8x faster performance. Pharo 6 focused on compaction and minor optimizations. Future work in Pharo 7 could include an incremental garbage collector and optimizations from the Sista just-in-time compiler that aim to provide 1.5-5x faster performance. The goals are to balance program readability and performance.























































































