Download to read offline


![7
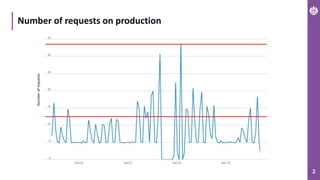
Time of processing requests (smaller is better)
436
684
775 792
172
1768
282
353
581
677 720
160
1463
207
0
200
400
600
800
1000
1200
1400
1600
1800
2000
Time[ms]
ASP.NET Core 2.2 ASP .NET Core 3.0](https://image.slidesharecdn.com/performance-netcore-3final-191126071900/85/Performance-NET-Core-M-Terech-P-Janowski-7-320.jpg)






![14
Naïve approach 1
app.Run(context => ProcessRequestAsync(context.Request.Body));
// NAIVE APPROACH
private async Task ProcessRequestAsync(Stream stream)
{
var buffer = new byte[1024];
while(true)
{
var bytesRead = await stream.ReadAsync(buffer, 0, buffer.Length);
if (bytesRead == 0)
{
return; // EOF
}
ProcessRowData(buffer, bytesRead);
}
}](https://image.slidesharecdn.com/performance-netcore-3final-191126071900/85/Performance-NET-Core-M-Terech-P-Janowski-14-320.jpg)
![15
Naïve approach 2
// BETTER APPROACH
private async Task ProcessRequestAsync(Stream stream)
{
var buffer = new byte[1024];
while (true)
{
var bytesRead = await stream.ReadAsync(buffer, 0, buffer.Length);
if (bytesRead == 0)
{
return; // EOF
}
var newLinePos = -1;
var bytesChecked = 0;
do
{
newLinePos = Array.IndexOf(buffer, (byte)'n', bytesChecked, bytesRead - bytesChecked);
if (newLinePos >= 0)
{
var lineLength = newLinePos - bytesChecked;
ProcessRowData(buffer, bytesChecked, lineLength);
}
bytesChecked += newLinePos + 1;
}
while (newLinePos > 0);
}
}](https://image.slidesharecdn.com/performance-netcore-3final-191126071900/85/Performance-NET-Core-M-Terech-P-Janowski-15-320.jpg)




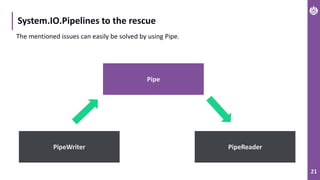




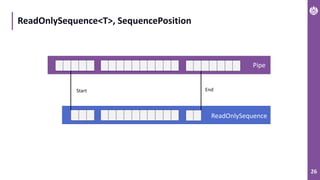




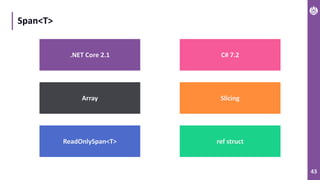




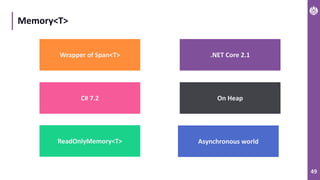
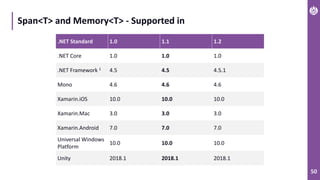

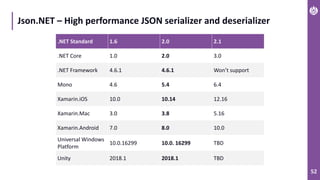


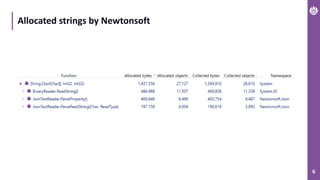
The document discusses performance metrics and optimizations for processing large CSV files in ASP.NET Core, comparing versions 2.2 and 3.0. It highlights the advantages of using System.IO.Pipelines for efficient data handling, detailing the implementation of reading and processing data using PipeReader and PipeWriter. Additionally, it touches on the importance of memory management, including concepts like Span<T> and Memory<T> for better performance in .NET applications.



































































