Downloaded 18 times



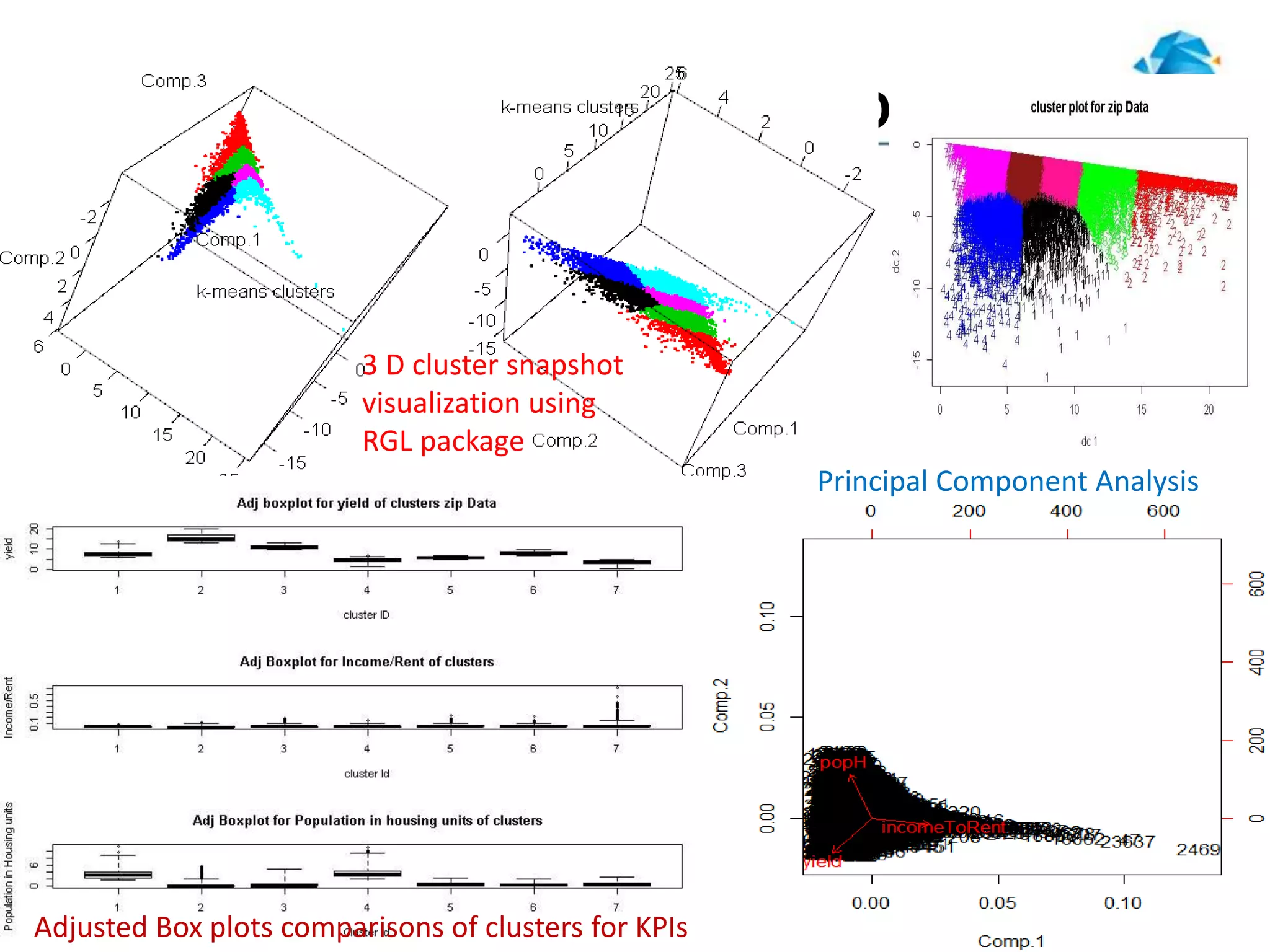








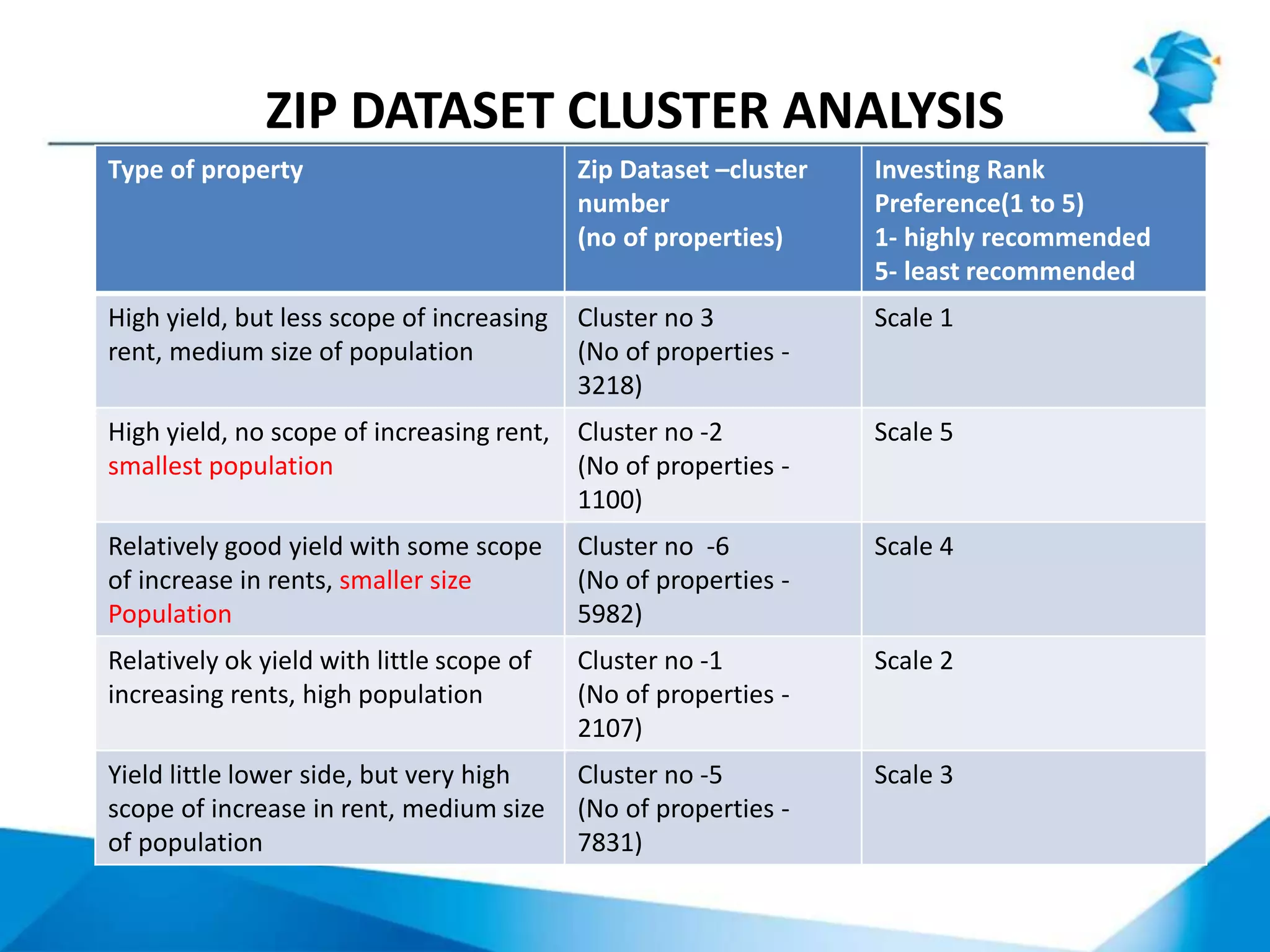
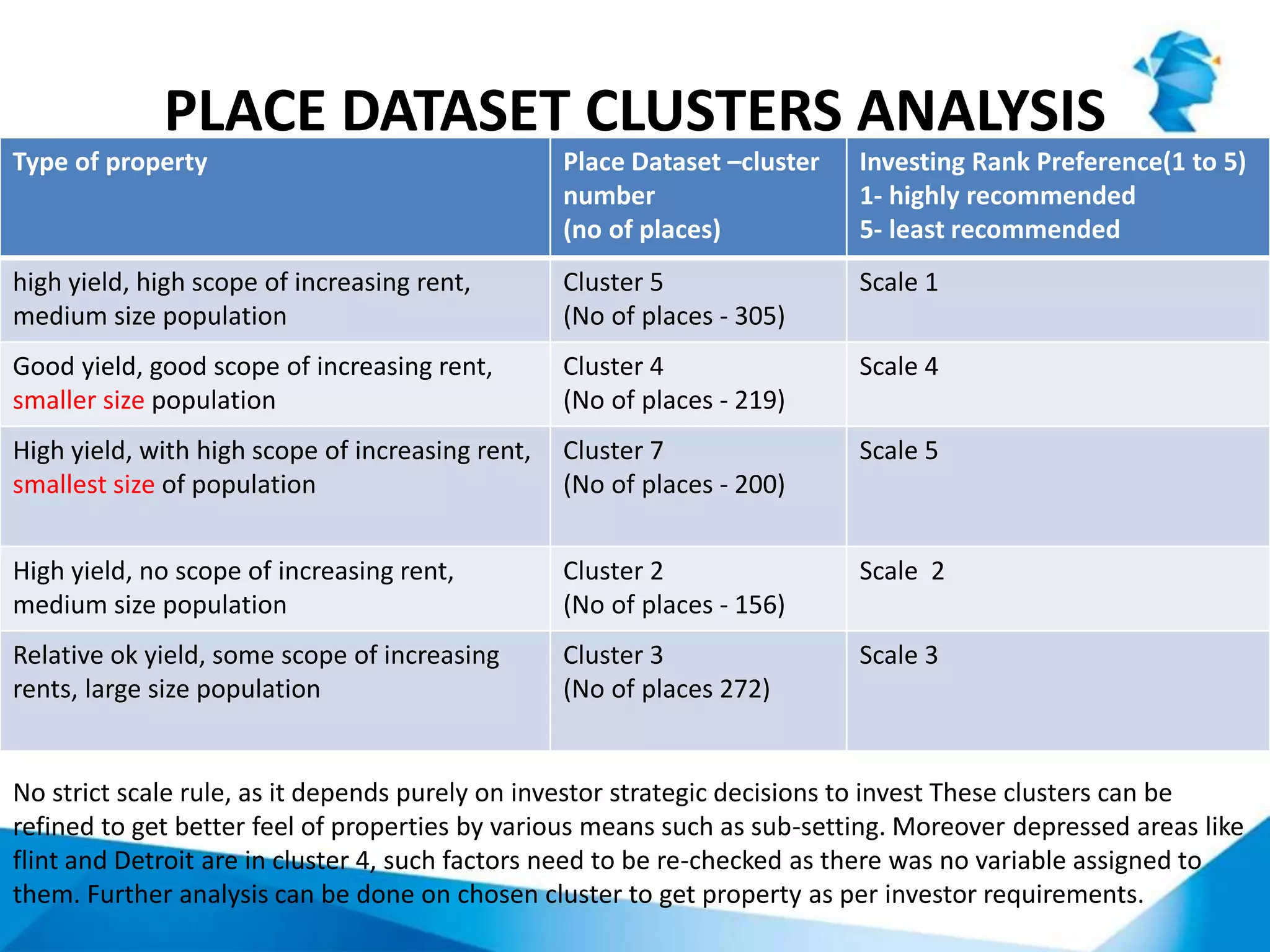



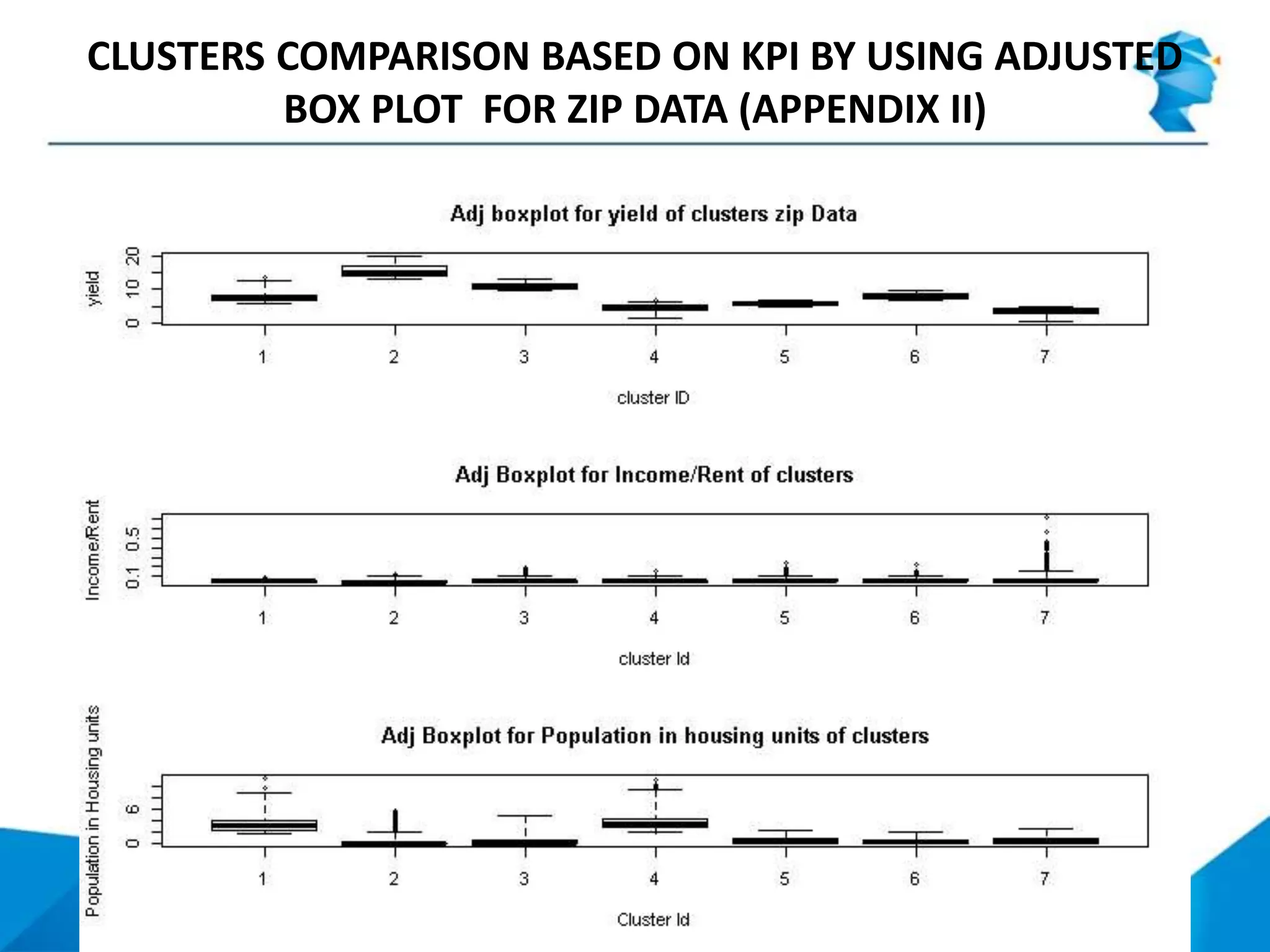
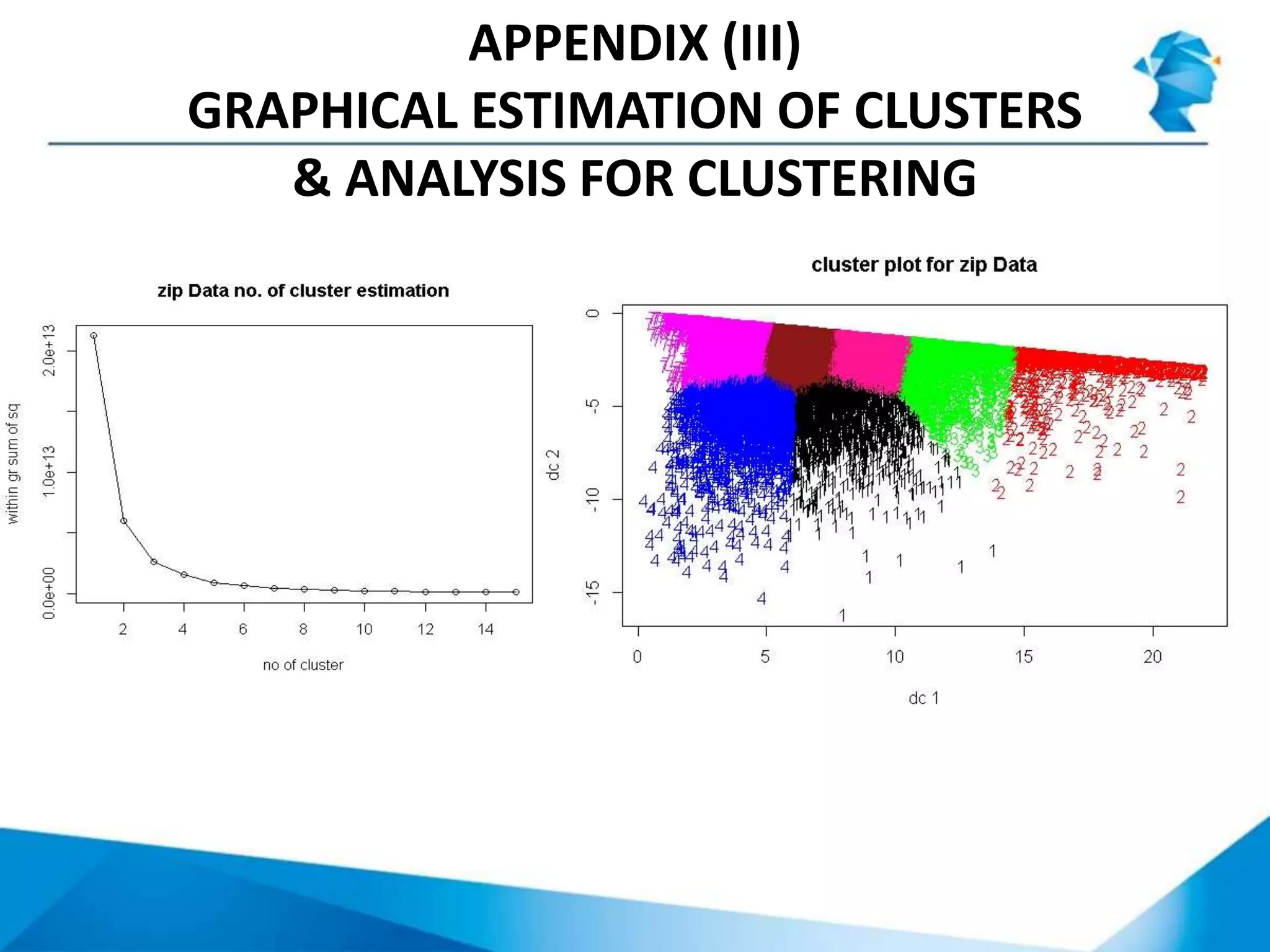
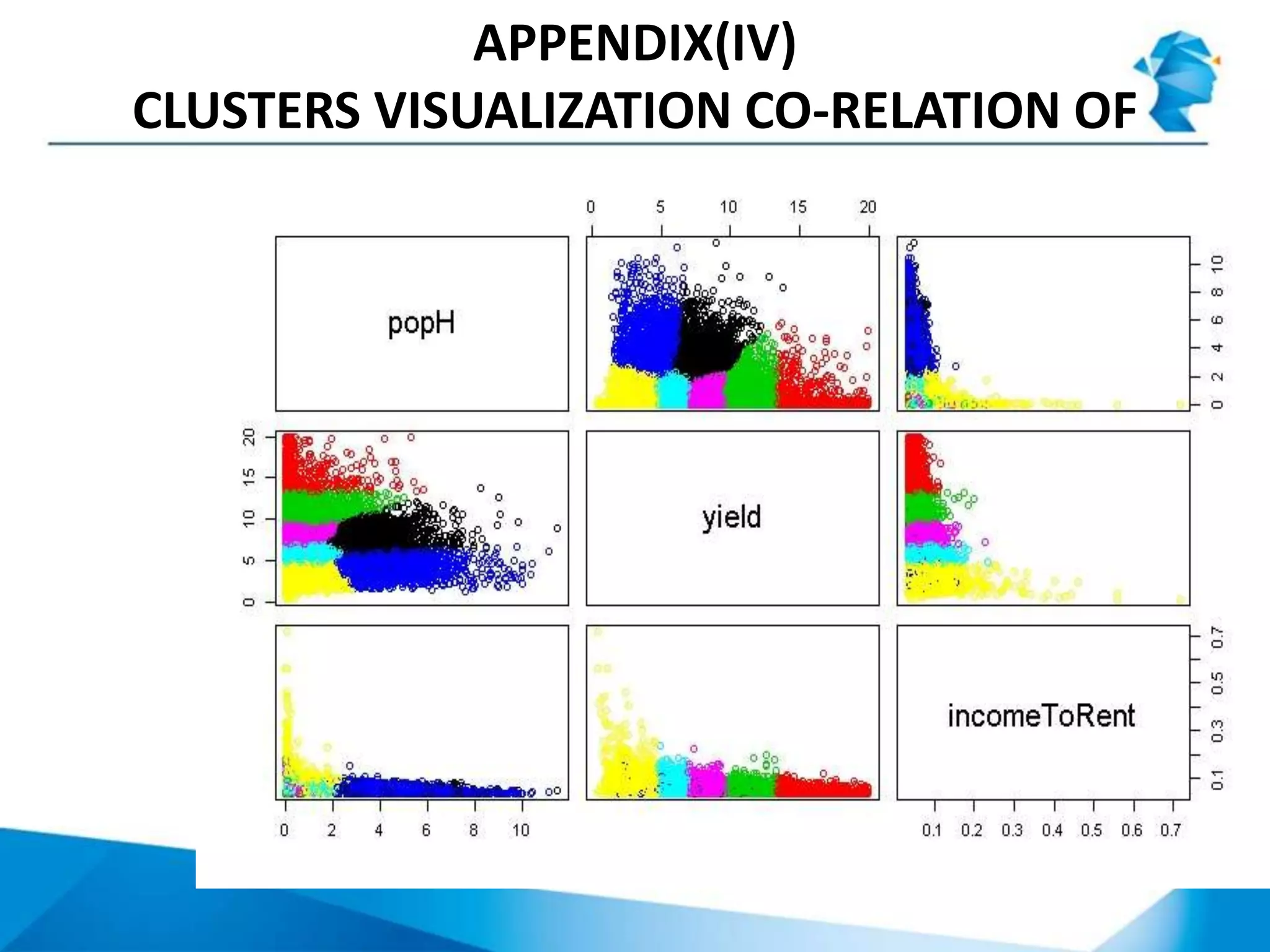

The document describes a project that uses unsupervised machine learning to analyze property data and recommend properties for investment. Key steps include: 1. Preprocessing data and selecting key performance indicators of rent yield, income-to-rent ratio, and population. 2. Using k-means clustering to group properties into 7 clusters based on the selected indicators. 3. Analyzing the clusters to profile them and rank their investment potential from 1 to 5, with 1 being the most attractive, based on characteristics like population size and potential for rent increases.




































































