ⓒSaebyeol Yu. Saebyeol’sPowerPoint
RefineNet
:Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
CVPR 2017
Guosheng Lin1;2, Anton Milan1, Chunhua Shen1;2, Ian Reid1;2
1The University of Adelaide, 2Australian Centre for Robotic Vision,
발표자 오혜린
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
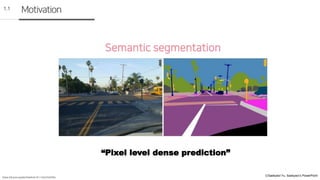
Motivation
1.2
• Row-level visual information
• High-resolution feature maps
• finer image
ex )224 x 224
• High-level visual information
• low-resolution feature maps
• coarse image
Ex ) 14x 14
모든 단계에서의 features는
semantic segmentation을 하는데 도움이 됨
https://miro.medium.com/max/2920/1*A86wUjL-Z0SWDDI3slKqtg@2x.png
Motivation: Resnet
5.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
Motivation: Resnet
1.2
• Subsampling : Pooling + convolutional stride을 반복하게 되면
• 좀 더 큰 정보를 볼 수 있음
• 채널의 수는 증가, feature map의 해상도는 감소
• 저해상도의 feature map이 만들어짐
• low-level-filter에 의해 만들어진 디테일한 정보들(finer information)이 손실됨
• 거친 (coarse)한 segmentation map만 남음
6.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
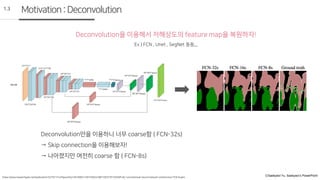
Motivation:Deconvolution
1.3
Deconvolution을 이용해서 저해상도의 feature map을 복원하자!
Ex ) FCN , Unet , SegNet 등등,,,
https://www.researchgate.net/publication/327521314/figure/fig1/AS:668413361930241@1536373572028/Fully-convolutional-neural-network-architecture-FCN-8.ppm
Deconvolution만을 이용하니 너무 coarse함 ( FCN-32s)
→ Skip connection을 이용해보자!
→ 나아졌지만 여전히 coarse 함 ( FCN-8s)
7.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
1.3
Motivation:Deconvolution
“ up sampling을 통해 high-resolution 이미지를 만들 수는 있어도,
down sampling을 통해 이미 low-level features를 잃어버렸기 때문에
up sampling을 하더라도 완전하게 복원하기는 힘들다.”
https://ichi.pro/ko/transposed-convolutions-seolmyeong-ms-excel-91058410145768
8.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
1.4
Motivation:Dilatedconvolution
“pooling을 하면 feature map 축소, 위치 정보 손실
Down sampling이 문제네! 하지 말자! “
“ Sub sampling 없애고
dilated (atrous)convolution으로 진행해 ! “
9.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
1.4
Motivation:Dilatedconvolution
https://m.blog.naver.com/laonple/220991967450
https://cdn-images-1.medium.com/max/1200/1*SVkgHoFoiMZkjy54zM_SUw.gif
• Dilation rate : 커널에 의해 계산되는 pixel간 거리
• Dilation rate에 따라 receptive filed가 달라짐
• 빨간 색 부분만 가중치 존재 그 사이 pixel은 zero-padding
진한 부분만 가중치 존재
나머지 부분은 0으로 padding
R = 2
R = 4
10.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
1.4
Motivation:Dilatedconvolution
파라미터의 개수는 유지하면서 receptive filed를 늘릴 수 있음
Receptive field가 커진다 → 더 많은 global한 정보를 수용
해상도 손실 없이 receptive field를 확장 가능
Dilated conv with r = 2
3x3 kernel
3x3
filter 3x3
filter 3x3
filter
7x7
5x5
3x3 1x1
7x7
filter
1x1
7x7
vs
Parameter : 9
Parameter : 49
Parameter :27
11.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
Motivation:Dilatedconvolution
1.4
• Sub sampling 역할을 하는 stride 1로 변경
• 첫 번째 block 이후 모든 conv를 dilated convolution으로 대체
• Pooling layer를 앞 단의 3개만 남겨놓고 제거
“Computationally expensive to train and
quickly reach memory limits even on modern GPUs”
12.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
Motivation
1.4
이전 Relate Work의 문제점
• Up-sampling을 하더라도 Down-sampling 자체가 정보를 손실!
• Dilated Conv를 사용하면 정보 손실이 덜하지만 메모리가 감당 불가!
“Refine Block을 사용해서
다양한 해상도의 feature를 합쳐서
효율적으로 고해상도 이미지 만들자!”
13.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
RefineNet:overview
2.1
block1
block2
block3
block4
RCU 2
+
Multi-resolution Fusion
+
Chained Residual Pooling
+
Output RCU 1
각 level 마다 취합 됨 : Multi-Path Refinement
서로 다른 사이즈의 2가지 input (Resblock + RefineBlock)
14.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
RefineNet:overview
2.1
• Encoder-Decoder 구조
• level 별 down-sampling 기 전 features 취합
→ Multi-level features를 통한 high resolution prediction이 가능해짐
• Unet, FCN과 다르게 RefineNet을 통해 resblock과 refine block 사이의 skip connection
→ 초반 layer에게도 backpropagation 효율적으로 가능
→ end-to-end training 가능
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
RefineNet:ResidualConvUnit
2.2
• Input path 별로 Residual Convolution Unit 을 2번 거침
• Pretrained Resnet을 Semantic Segmentation task에 맞춰 fine-tune 하는 역할
K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. arXiv preprint arXiv:1603.05027,2016.
17.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
RefineNet:Multi-resolutionFusion
2.3
1. 서로 다른 input size를 맞춰 주기 위해 작은 size에 맞춰서 3x3x conv
: 다른 path에서 온 feature들을 re-scale 해주는 역할
2. 큰 size에 맞춰 주기 위해 up-sample
3. summation
18.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
RefineNet:ChainedResidualPooling
2.4
• 5x5 max pooling + 3x3 conv (with stride 1 )
• 다양한 window size로 feature들을 pooling하는 역할
• 이미지를 더 넓게 봐서 배경이나 전체적인 맥락을 확인함
Residualconnections
:backpropagation을쉽게해줌
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
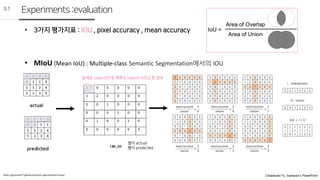
3.1
Experiments:evaluation
https://gaussian37.github.io/vision-segmentation-miou/.
• 3가지 평가지표 : IOU , pixel accuracy , mean accuracy
• MIoU (Mean IoU) : Multiple-class Semantic Segmentation에서의 IOU
열이 actual
행이 predicted
실제로 class 0인데, 예측도 class0 이라고 한 경우
21.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
3.1
Experiments:evaluation
https://gaussian37.github.io/vision-segmentation-miou/.
• 3가지 평가지표 : IOU , pixel accuracy , mean accuracy
J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015.
Class
예측한 것 중
맞춘 pixel 개수
예측한 pixel 개수
0 5 6
1 1 2
2 1 1
3 2 2
4 2 2
5 3 3
• Pixel accuracy :
5+1+1+2+2+3
6+2+1+2+2+3
=
14
16
= 0.875
• Mean accuracy : 1
6
×
5
6
+
1
2
+
1
1
+
2
2
+
2
2
+
3
3
= 0.88
22.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
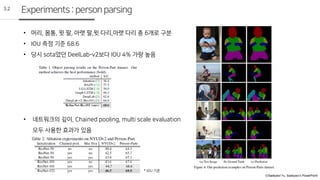
• 머리, 몸통, 윗 팔, 아랫 팔,윗 다리,아랫 다리 총 6개로 구분
• IOU 측정 기준 68.6
• 당시 sota였던 DeelLab-v2보다 IOU 4% 가량 높음
• 네트워크의 깊이, Chained pooling, multi scale evaluation
모두 사용한 효과가 있음
3.2
Experiments:personparsing
* IOU 기준
23.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
Experiments:NYUDv2
3.3
https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
• 40개의 class를 가지고 있는 실내장면 RGB-D image dataset
• 1449개 중 795개는 train , 654개 test
• Depth는 사용하지 않음
• Pixel acc : 74.6 , mean acc : 58.9 , IoU : 46.5
24.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
Experiments:PASCALVOC2012
3.4
• 20개의 class + background로 총 21개의 category
• Train : val : test = 1464 : 1449 : 1456
• Dense CRF 사용 시 , dev에서 0.1%증가
• 모든 class에 대한 평균 IOU 83.4
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
Experiments:Cityscapes
3.5
https://www.cityscapes-dataset.com/
• 19개의 class를 가진 50가지의 유럽 도시 장면 dataset
• 상당히 정교한 pixel-level annotation
• 2975개의 training set + 500 images
• IOU 73.6 달성
27.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
Experiments:PASCAL-Context
3.6
https://cs.stanford.edu/~roozbeh/pascal-context/
• PASCAL VOC 2010의 추가 데이터
• 59개의 class + background 총 60개
• 4998개 training set + 5105 test set
• 추가 데이터 없이 당시 sota인 DeepLav-v2 압도
PASCAL-Context
28.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
Experiments:SUN-RGBD
3.7
https://rgbd.cs.princeton.edu/
• 10000장 가량의 RGB-D 실내 이미지
• 37개의 class
• Pixel acc : 80.6 , Mean acc : 58.5 , IOU : 45.9
SUN-RGBD
29.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
Experiments:ADE20KMIT
3.8
https://groups.csail.mit.edu/vision/datasets/ADE20K/
• 150개의 class를 가지는 20000장 이상의 이미지 데이터 셋
• 사람, 차 같은 큰 물체부터 stuff 까지 다양
• IOU : 40.7 달성
ADE20K MIT
30.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
Experiments:VariantsofcascadedRefineNet
3.9
https://groups.csail.mit.edu/vision/datasets/ADE20K/
• RefineNet은 자유롭게 구성 가능
• Single , 2-cascaded , 4-cascaded 2-scale 비교
• Cascaded가 2개일때보다는 4개일 때,
single 일 때보다는 multi일 때가 IOU가 더 높음
• 4-cascade가 efficiency와 accuracy의 trade-off
31.
ⓒSaebyeol Yu. Saebyeol’sPowerPoint
Conclusion
4
• Cascaded architecture를 통해 효과적으로 high-level feature와 low-level feature를 합쳐
high-resolution segmentation map을 생성함.
• Identity mapping을 통해 backpropagation & end-to-end 학습이 가능하게 했다.
• “chained residual pooling”을 통해 더 큰 시야에서의 배경을 이해함
• 7개의 dataset(PASCAL VOC2012 , PASCAL-Context , NYUDv2 , SUN-RGBD , Cityscapes, AED20K,
Person-Parts dataset)에서 sota르 달성








































![[부스트캠프 Tech Talk] 배지연_Structure of Model and Task](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkbaejiyeon-211210113740-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Paper Review] Visualizing and understanding convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/visualizingandunderstandingconvolutionalnetworks-171116075511-thumbnail.jpg?width=640&height=640&fit=bounds)





