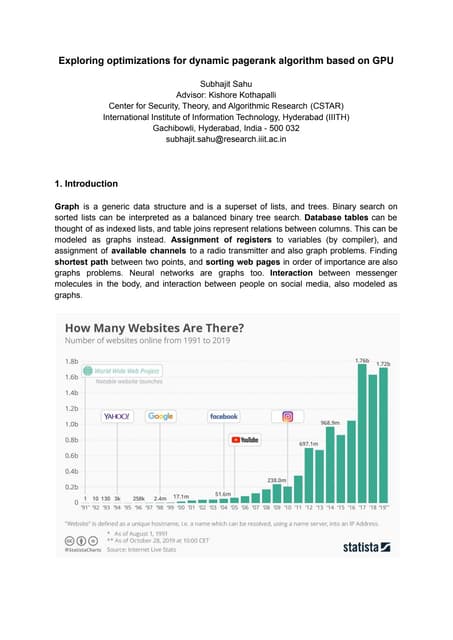
Download as PDF, PPTX

![2013/2/12
2
Evolving Graph(Web Graph)
g p ( p )
2
The directed links between web pages
The directed links between web pages
Used for computing the PageRank of the WWW
pages [4]
pages [4]](https://image.slidesharecdn.com/pagerankonevolvinggraph-yanzhaoyang6-compressed-210724130849/85/PageRank-on-an-evolving-graph-Yanzhao-Yang-NOTES-2-320.jpg)
![2013/2/12
3
Page Rank
g
3
Classic link analysis algorithm based on the web
Classic link analysis algorithm based on the web
graph
A page that is linked to by many pages receives a
A page that is linked to by many pages receives a
high rank itself. Otherwise, it receives a low rank.
The rank value indicates an importance of a
The rank value indicates an importance of a
particular page. [5]
Very effective measure of reputation for both web
Very effective measure of reputation for both web
graphs and social networks.](https://image.slidesharecdn.com/pagerankonevolvinggraph-yanzhaoyang6-compressed-210724130849/85/PageRank-on-an-evolving-graph-Yanzhao-Yang-NOTES-3-320.jpg)






![2013/2/12
10
Page Rank algorithm categories
g g g
10
Linear algebraic methods[3]
Linear algebraic methods[3]
-Power iteration speed up.
E.g, web graph.
E.g, web graph.
Monte carlo methods[6]
-efficient and highly scalable
efficient and highly scalable
E.g, data streaming anfd map reduce.](https://image.slidesharecdn.com/pagerankonevolvinggraph-yanzhaoyang6-compressed-210724130849/85/PageRank-on-an-evolving-graph-Yanzhao-Yang-NOTES-10-320.jpg)























The document discusses the challenges of computing PageRank on an evolving graph, highlighting the inadequacies of traditional algorithms for dynamic data. It presents a new approach that involves continuously probing the graph to ensure accurate PageRank values while minimizing error. The findings demonstrate that proportional and priority probing methods significantly outperform existing techniques.