Download as PDF, PPTX




![from pulsar import Function
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
import json
class Chat(Function):
def __init__(self):
pass
def process(self, input, context):
fields = json.loads(input)
sid = SentimentIntensityAnalyzer()
ss = sid.polarity_scores(fields["comment"])
row = { }
row['id'] = str(msg_id)
if ss['compound'] < 0.00:
row['sentiment'] = 'Negative'
else:
row['sentiment'] = 'Positive'
row['comment'] = str(fields["comment"])
json_string = json.dumps(row)
return json_string
Entire Function
Pulsar Python
NLP Function
https://github.com/tspannhw/pulsar-pychat-function](https://image.slidesharecdn.com/conf42-kubenativebuildingreal-timepulsarappsonk8-221020170511-4aa526ec/75/Conf42-KubeNative-Building-Real-time-Pulsar-Apps-on-K8-11-2048.jpg)


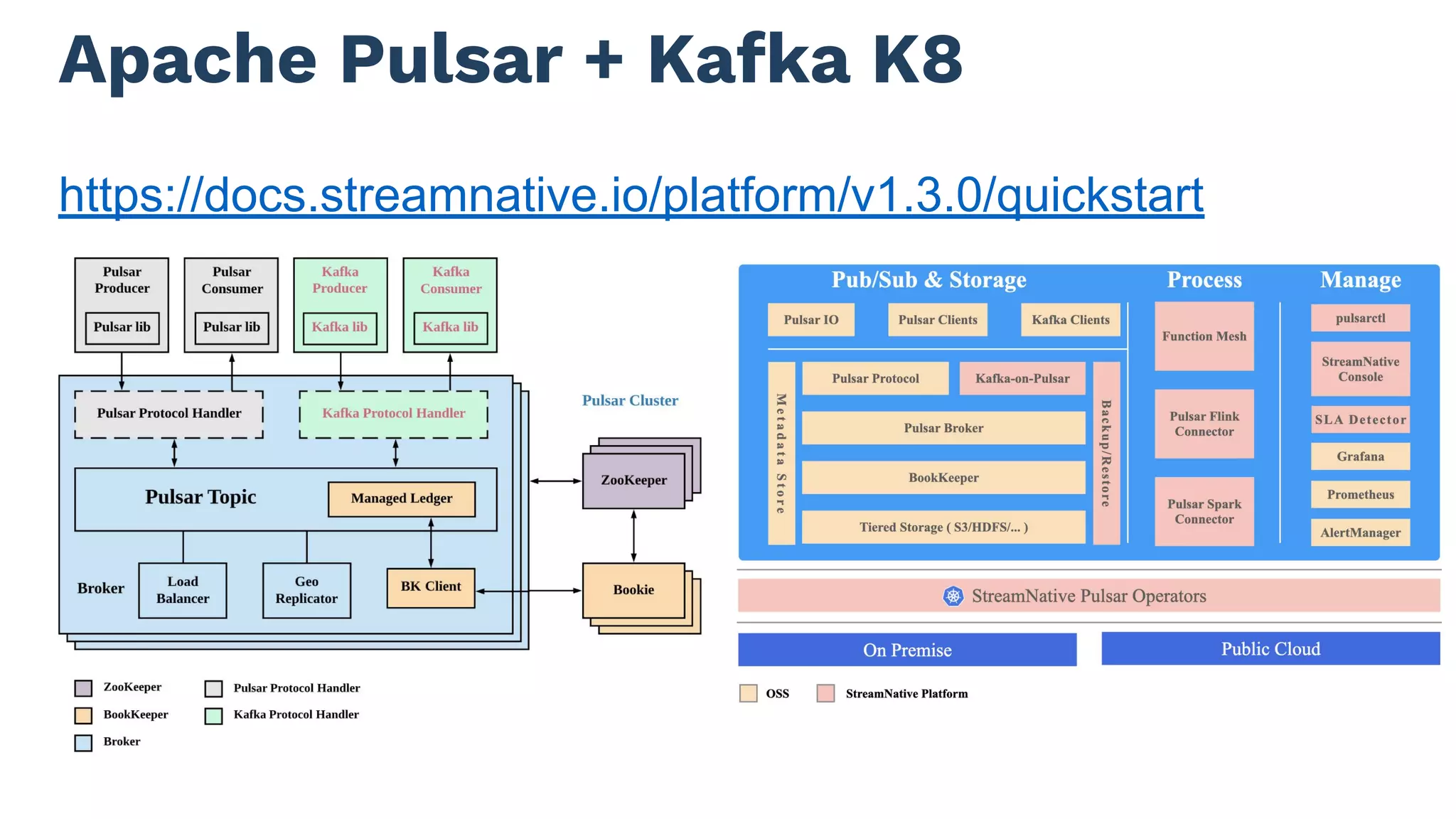
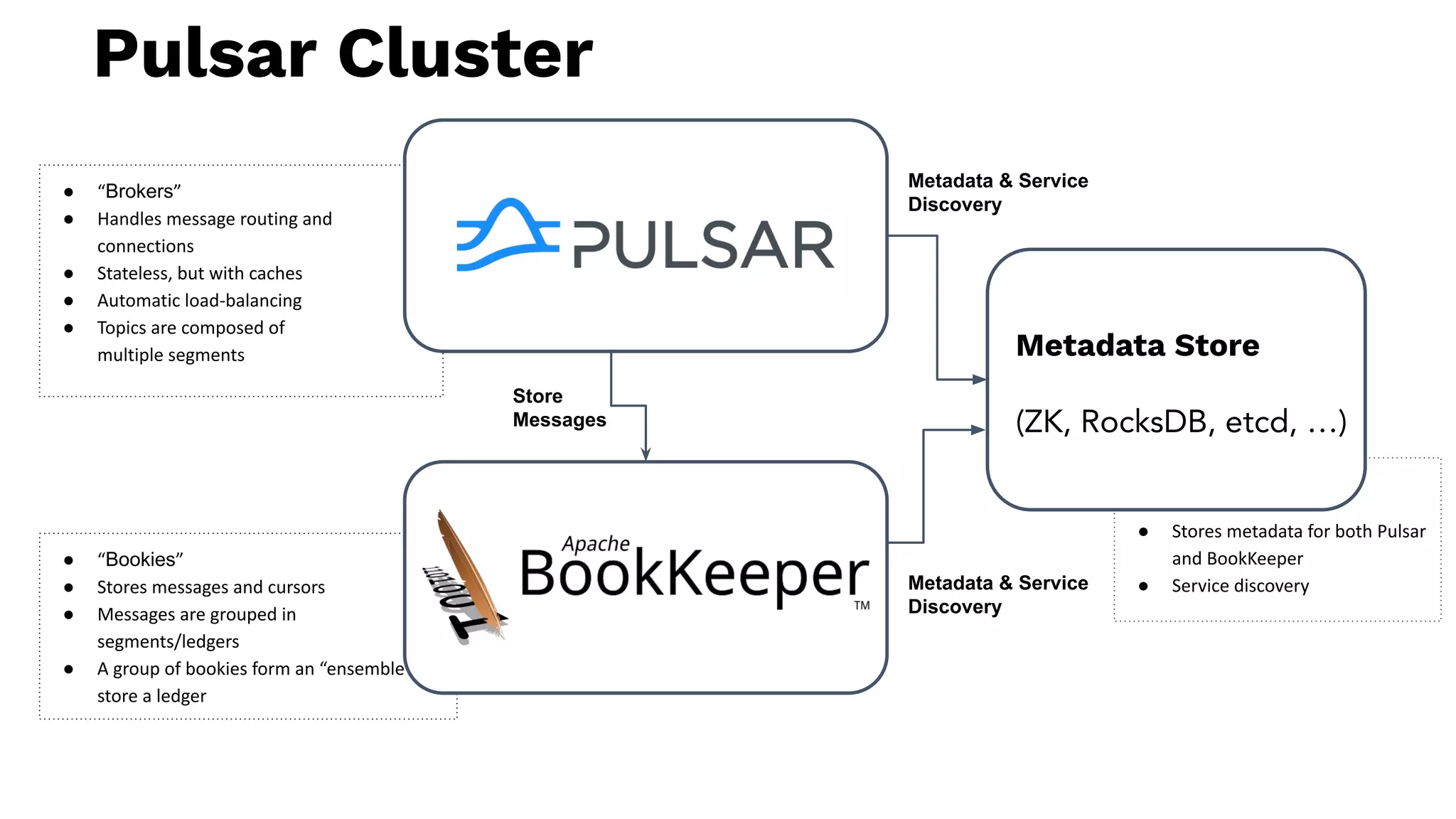
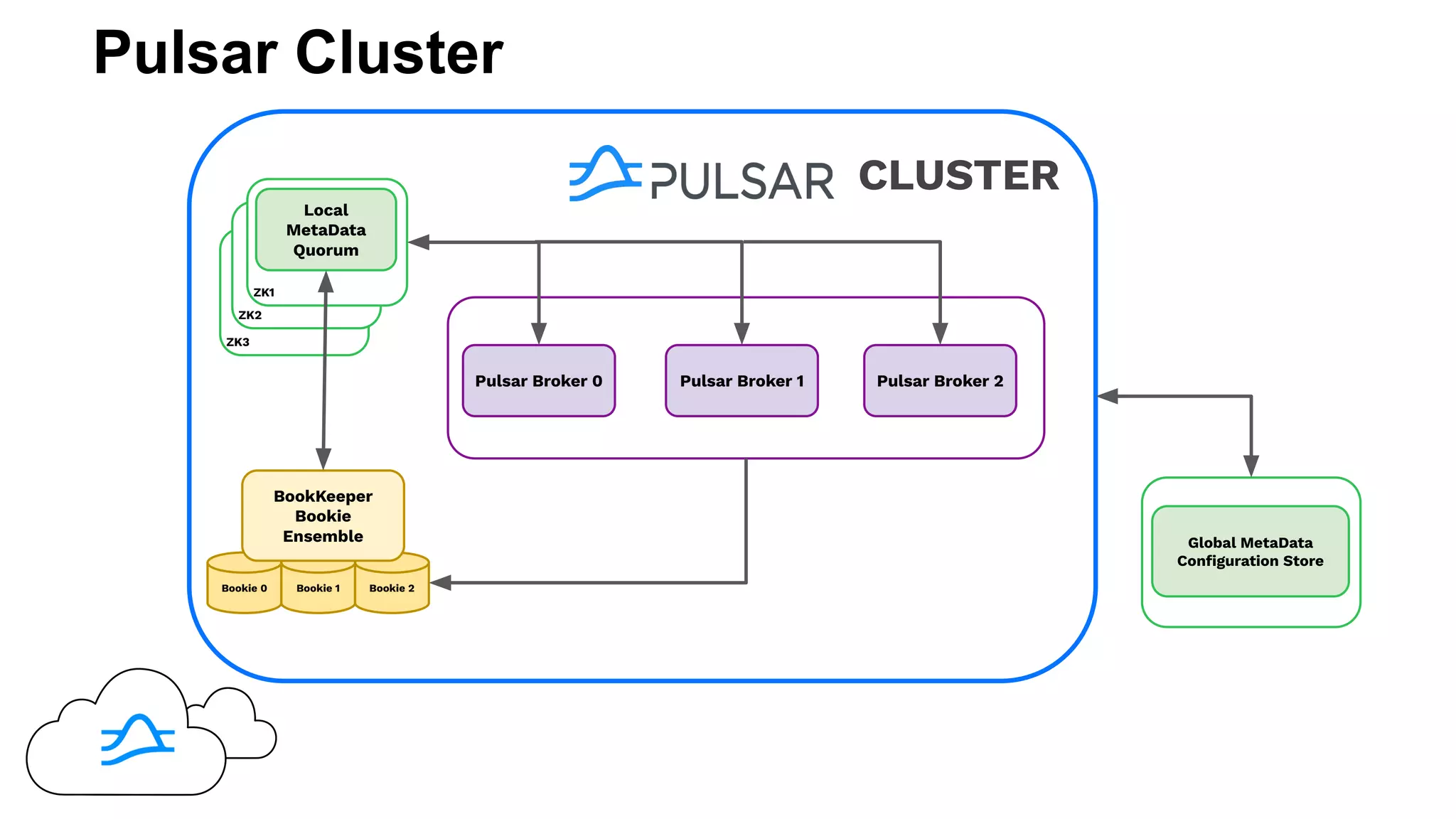
The document discusses building real-time applications using Apache Pulsar on Kubernetes, highlighting Tim Spann's experience and contributions to the Pulsar community. It outlines Pulsar's architecture, including its components like bookies and brokers, along with support for data processing through Pulsar functions and integration with programming languages. The document also references various resources and projects related to Pulsar and its ecosystem.



































































