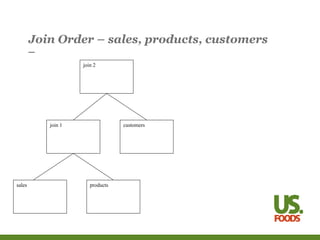
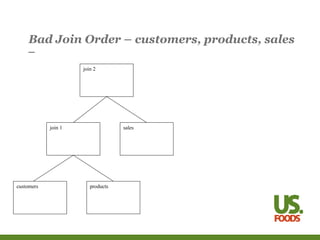
This document introduces several concepts for tuning SQL queries, including modifying the join order, join method, and access method. It discusses using hints, statistics, and initialization parameters to influence the execution plan and cause the database to run queries more efficiently. Examples are provided for improving a sample query that joins multiple tables using different techniques.










































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)







