Downloaded 62 times




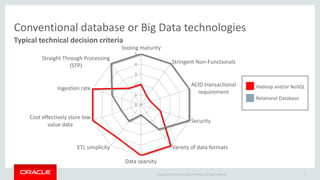
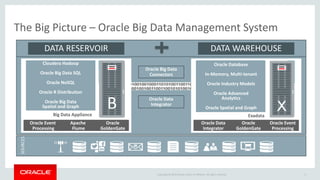






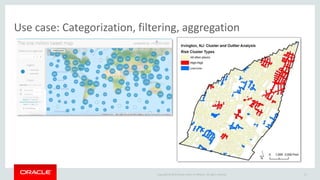
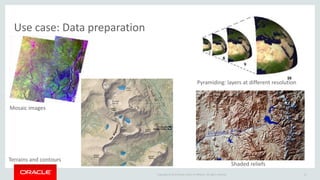

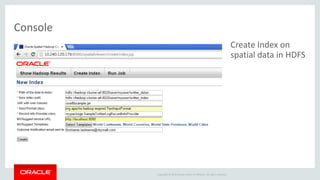
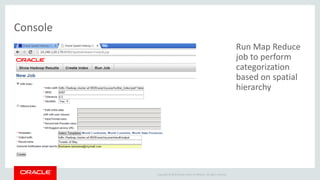
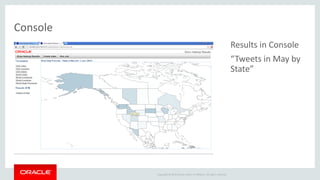




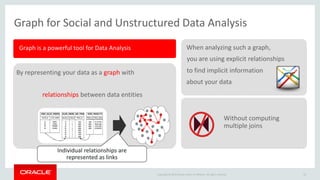
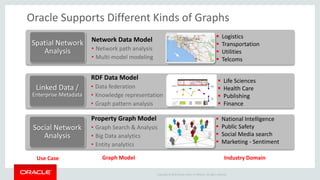
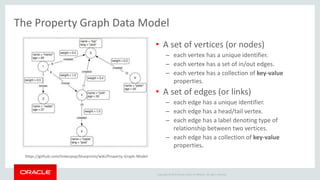
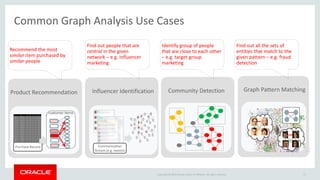

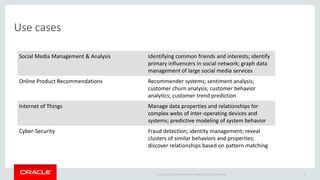

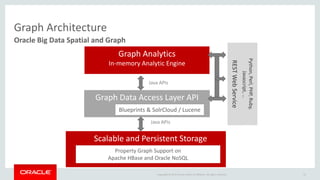






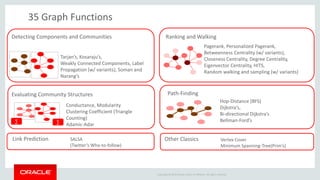
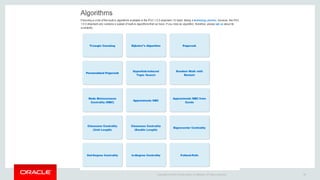

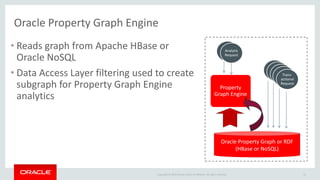


The document discusses Oracle's strategy to enable spatial and graph use cases on big data platforms. It provides an overview of Oracle's Big Data Spatial and Graph product, which allows for property graph analysis and spatial analysis on Hadoop. The spatial features allow for location data enrichment, proximity analysis, and preparation of map and imagery data. The graph features are useful for analysis of social media relationships, internet of things interactions, and cybersecurity.













































































