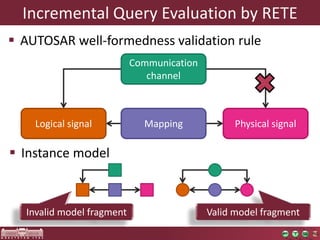
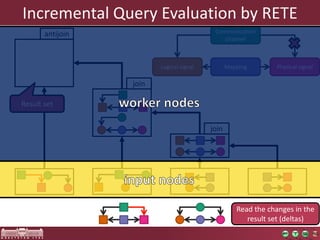
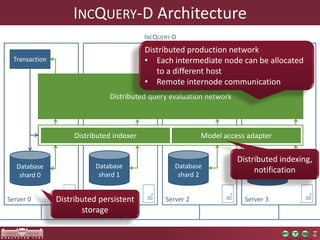
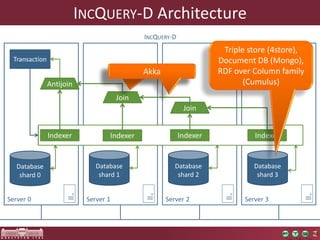
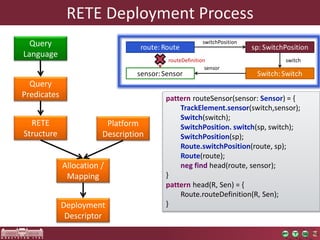
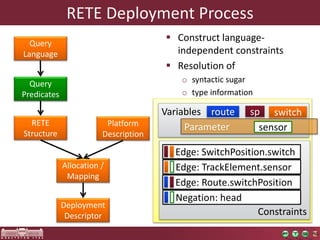
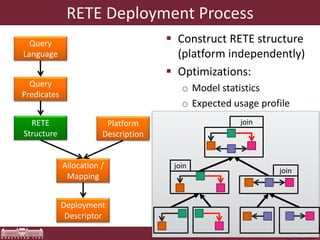
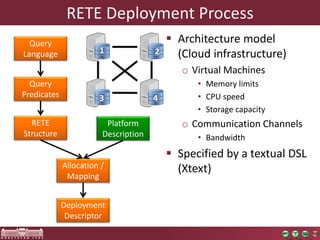
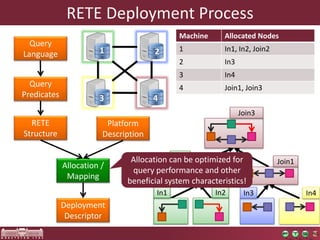
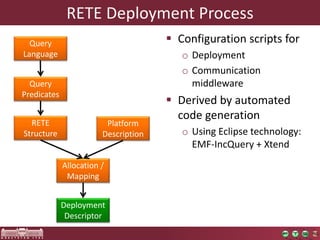
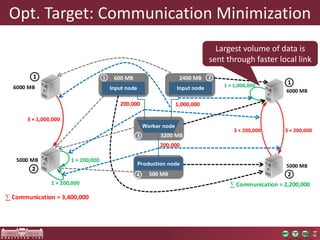
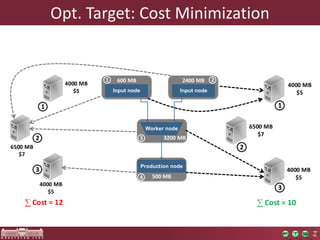
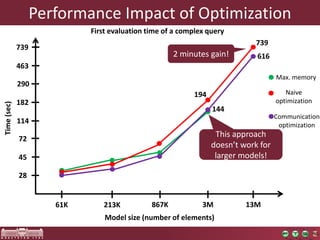
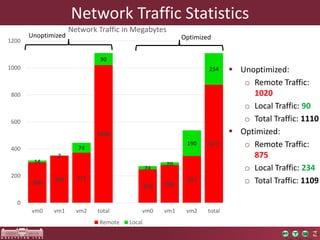
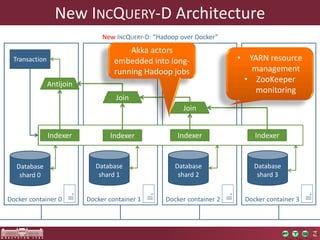
The document discusses the optimization of incremental queries in cloud-based systems through the IncQuery-D framework, highlighting its architecture and deployment processes. It emphasizes achieving scalability and performance improvements by optimizing resource allocation and minimizing network communication overhead. Future work includes enhancements for dynamic reallocation and support for Hadoop-based applications.