Downloaded 58 times




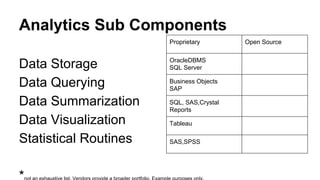
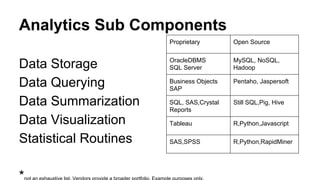






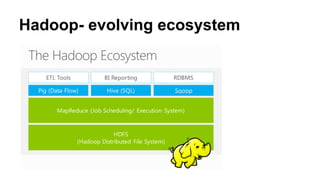
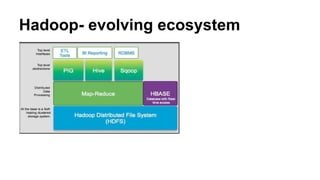
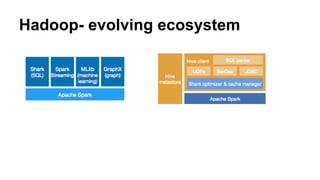
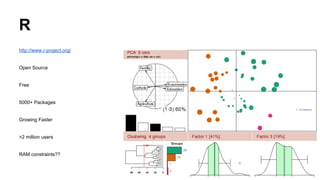
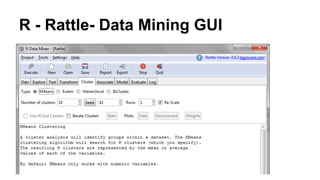
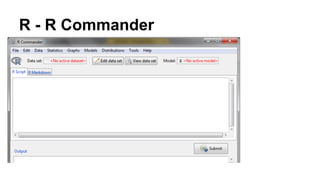
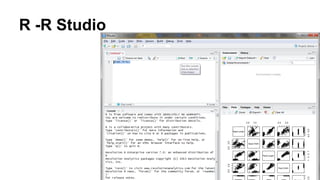

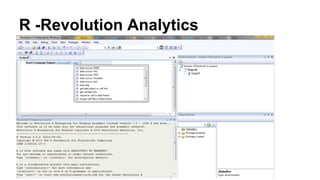

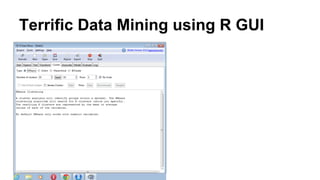
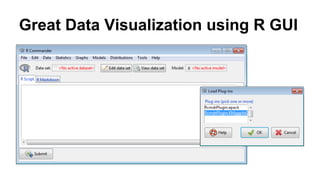


















This document discusses the rise of open source analytics tools and languages. It notes that SAS and SPSS previously dominated the market but were very expensive. R, Python, and Hadoop have provided lower-cost open source alternatives for data storage, querying, visualization, and statistical analysis. The document reviews popular open source tools like R, Python, RapidMiner, and Hadoop ecosystems. It also discusses commercial offerings that build on open source like Revolution Analytics. Overall, open source has helped reduce the costs of analytics software and enabled more organizations to benefit from data-driven insights.























































































