Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Kousuke Takeuhi
PPTX, PDF
387 views
Olearning-prml1
Learning ML at GrandFront in Osaka, chapter1
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 19
2
/ 19
3
/ 19
4
/ 19
5
/ 19
6
/ 19
7
/ 19
8
/ 19
9
/ 19
10
/ 19
11
/ 19
12
/ 19
13
/ 19
14
/ 19
15
/ 19
16
/ 19
17
/ 19
18
/ 19
19
/ 19
More Related Content
PDF
[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2
by
Teruyuki Sakaue
PDF
[DSO] Machine Learning Seminar Vol.2 Chapter 3
by
Teruyuki Sakaue
PPTX
JSAI2017:敵対的訓練を利用したドメイン不変な表現の学習
by
Yusuke Iwasawa
PDF
論文紹介 Semi-supervised Learning with Deep Generative Models
by
Seiya Tokui
PPTX
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
by
Yusuke Iwasawa
PPTX
Paper Introduction "RankCompete: Simultaneous ranking and clustering of info...
by
Kotaro Yamazaki
PDF
オブジェクト指向ワークショップ 201507版
by
Mao Ohnishi
PDF
KDD2014勉強会: Large-Scale High-Precision Topic Modeling on Twitter
by
sleepy_yoshi
[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2
by
Teruyuki Sakaue
[DSO] Machine Learning Seminar Vol.2 Chapter 3
by
Teruyuki Sakaue
JSAI2017:敵対的訓練を利用したドメイン不変な表現の学習
by
Yusuke Iwasawa
論文紹介 Semi-supervised Learning with Deep Generative Models
by
Seiya Tokui
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
by
Yusuke Iwasawa
Paper Introduction "RankCompete: Simultaneous ranking and clustering of info...
by
Kotaro Yamazaki
オブジェクト指向ワークショップ 201507版
by
Mao Ohnishi
KDD2014勉強会: Large-Scale High-Precision Topic Modeling on Twitter
by
sleepy_yoshi
Similar to Olearning-prml1
PDF
機械学習の理論と実践
by
Preferred Networks
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PPTX
MLaPP輪講 Chapter 1
by
ryuhmd
PPTX
実践:今日から使えるビックデータハンズオン あなたはタイタニック号で生き残れるか?知的生産性UPのための機械学習超入門
by
健一 茂木
PDF
Prml1.2.1~1.2.2
by
Tomoyuki Hioki
PDF
Prml1.2.5~1.2.6
by
Tomoyuki Hioki
PDF
PRML読書会1スライド(公開用)
by
tetsuro ito
PPTX
PRML読み会第一章
by
Takushi Miki
PDF
PRML上巻勉強会 at 東京大学 資料 第1章前半
by
Ohsawa Goodfellow
PDF
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
PPTX
Lecture1
by
Katsunori Yoshinaka
PDF
Machine learning for biginner
by
Atsushi Hayakawa
PPTX
Machine learning
by
TakahiroBaba3
PDF
機械の代わりに人間が学習入門
by
Shuyo Nakatani
PPTX
第一回 機械学習
by
Akira Maegawa
PDF
Guide for program Implement for PRML
by
Masato Nakai
PPTX
PRML1.1
by
Tomoyuki Hioki
PDF
PRML1.1
by
Tomoyuki Hioki
PDF
Prml1.2.3
by
Tomoyuki Hioki
PPTX
PRML1.2
by
Tomoyuki Hioki
機械学習の理論と実践
by
Preferred Networks
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
MLaPP輪講 Chapter 1
by
ryuhmd
実践:今日から使えるビックデータハンズオン あなたはタイタニック号で生き残れるか?知的生産性UPのための機械学習超入門
by
健一 茂木
Prml1.2.1~1.2.2
by
Tomoyuki Hioki
Prml1.2.5~1.2.6
by
Tomoyuki Hioki
PRML読書会1スライド(公開用)
by
tetsuro ito
PRML読み会第一章
by
Takushi Miki
PRML上巻勉強会 at 東京大学 資料 第1章前半
by
Ohsawa Goodfellow
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
Lecture1
by
Katsunori Yoshinaka
Machine learning for biginner
by
Atsushi Hayakawa
Machine learning
by
TakahiroBaba3
機械の代わりに人間が学習入門
by
Shuyo Nakatani
第一回 機械学習
by
Akira Maegawa
Guide for program Implement for PRML
by
Masato Nakai
PRML1.1
by
Tomoyuki Hioki
PRML1.1
by
Tomoyuki Hioki
Prml1.2.3
by
Tomoyuki Hioki
PRML1.2
by
Tomoyuki Hioki
More from Kousuke Takeuhi
PPTX
Chapter9
by
Kousuke Takeuhi
PDF
Olearning-prml13
by
Kousuke Takeuhi
PPT
Data Analysis - Chapter two
by
Kousuke Takeuhi
PPTX
Olearning-prml4
by
Kousuke Takeuhi
PPTX
Olearning-prml6
by
Kousuke Takeuhi
PDF
Olearning-prml8
by
Kousuke Takeuhi
PDF
自己組織化ネットワークについて
by
Kousuke Takeuhi
Chapter9
by
Kousuke Takeuhi
Olearning-prml13
by
Kousuke Takeuhi
Data Analysis - Chapter two
by
Kousuke Takeuhi
Olearning-prml4
by
Kousuke Takeuhi
Olearning-prml6
by
Kousuke Takeuhi
Olearning-prml8
by
Kousuke Takeuhi
自己組織化ネットワークについて
by
Kousuke Takeuhi
Olearning-prml1
1.
Olearn-PRML1 Kousuke Takeuchi
2.
CAPTER1 機械学習とは
3.
どんなことに使える技術? ユーザーの好きな動画を見つけたり 購買履歴からおすすめの商品を推薦したり →
いわゆる推薦(レコメンド)システムの アルゴリズムとしてよく使われる
4.
機械学習の概要(種類) 学習段階 教師付き学習 ~>
音声認識 教師なし学習 ~> Facebookの友人検出 評価段階 強化学習 ~> FBで正しい友人を教える
5.
SECTION1 教師付き学習 (Supervised Learning)
6.
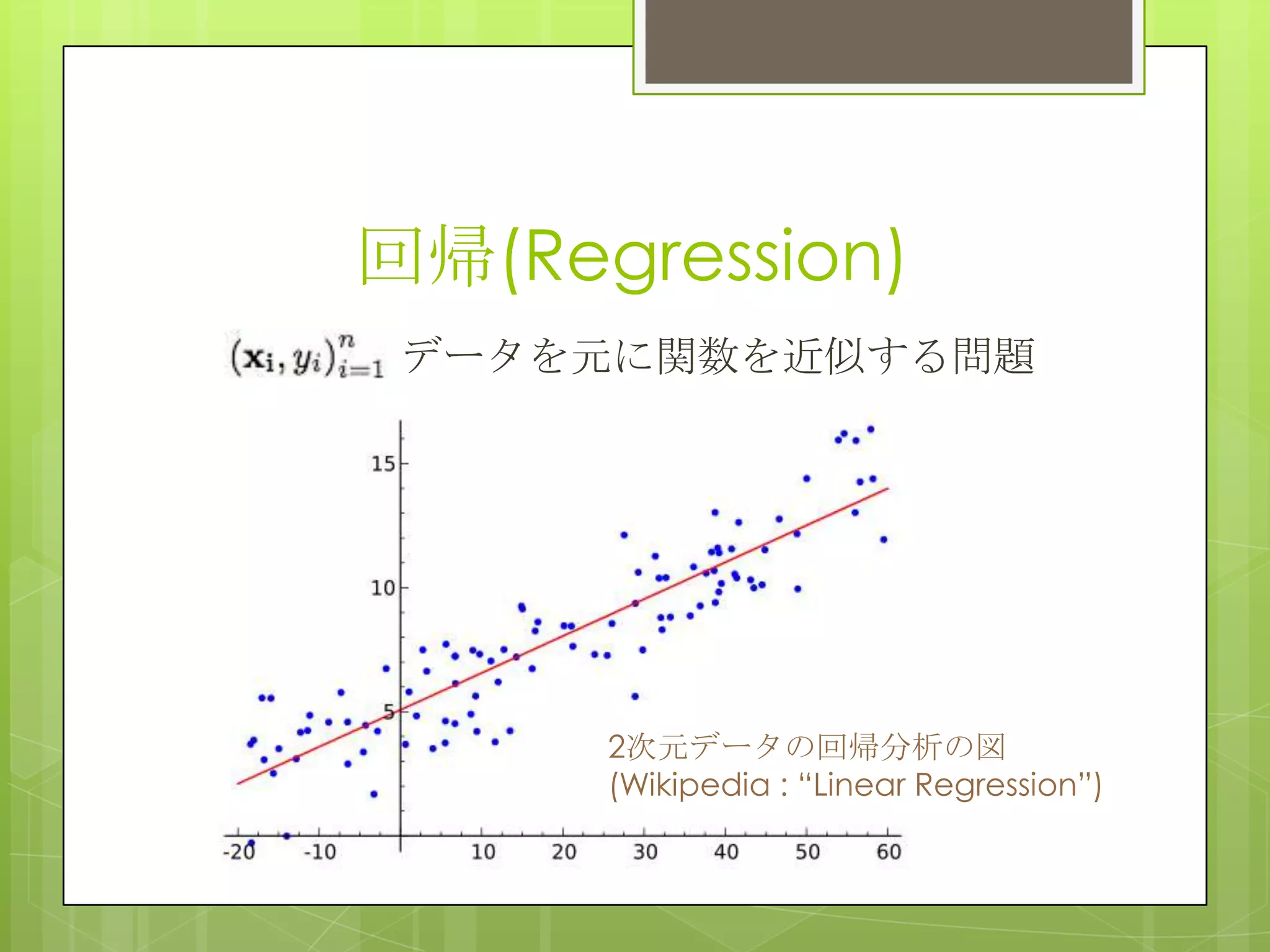
回帰(Regression) データを元に関数を近似する問題 2次元データの回帰分析の図 (Wikipedia : “Linear
Regression”)
7.
分類(Classification) ・回帰と同様、y=f(x)を学習する問題 ・xi をc個のクラスに分ける Ex.) 2次元グラフにおける事象分け(c
= 4(事象)) (1, 3) ~> 第1事象 (1, -1) ~> 第4事象
8.
SECTION2 教師なし学習 (Unsupervised Learning)
9.
異常検出(Anomaly detection) 正常データと異常データの例が与えられてい る場合は教師付き学習
例が与えられていない場合は教師なし学習に なる 通常の異常検出問題では例が明示的に与えら れないことが多い
10.
クラスタリング(Clastering) 分類と同様のパターン認識問題 入力標本 を元にラベル(1..c)を振り分 ける。 (分類はラベルが明示的に与えられる)
11.
次元削減(Dimensionality redution) 入力標本の次元数dが非常に大きい時、計算 量T(d)が大きくなり、計算に時間がかかって しまうので、少ない次元(データ数)に変換 する問題
Ex. ) 人間の価値に対する次元削減
12.
SECTION3 頻度主義とベイズ主義 (Bayesianism and Frequency
Principle)
13.
頻度主義(Frenquency Principle) D =
{(xi , yi)} ( i = 1..n ) パラメータθ を用いて学習 訓練標本 例:最尤推定) q : 生成モデルの精度 → モデルの精度が一番よくなるθを計算
14.
ベイズ主義(Bayesianism) p(θ) 事後確率 p(θ|D)
事前確率 一般的には、ベイズ主義は「信頼度」で計算 する。(モンティ・ホール問題など)
15.
ベイズ確率の計算例(病気の診断) 医者は患者の症状(S)を診ていて、いくつか考え られる病気(D1, …
Dn)のどれかを宣告しなけれ ばいけない。 これまでの診断記録から、病気の事前確率P(Di) と条件付き確率P(Di|S)は与えられている。 最も確からしい原因の病気P(S|Di)を求める
16.
ベイズ確率の計算例(2) いま、以下の確率がわかってるとする 症状Sの全確率は以下のようになる
17.
ベイズ確率の計算例(3) 従って、P(D1|S)の確率が最も高く、症状Sの 原因はD1という病気にかかっているからだと いう説が一番尤もらしいことが分かる
18.
つまりベイズ主義とは… 頻度主義では、大数の法則に基づく実験的な 確率の計算方法を採用していた。 しかし今回の例では、症状に対して原因とな る病気の確率を実験なしで求めることが出来 た。 →
「おなかが痛い?多分それ盲腸や」 に対する信頼度数と捉えることが出来る
19.
課題1 教師付き学習、教師なし学習、強化学習につ いて少しだけ例を上げたが、実際の応用例を 上げると多岐に渡る。 これら3つの、今回紹介しなかった
Download



















![[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2](https://cdn.slidesharecdn.com/ss_thumbnails/chapter12slides-200211153032-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSO] Machine Learning Seminar Vol.2 Chapter 3](https://cdn.slidesharecdn.com/ss_thumbnails/chapter3slides-200226170409-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)





























