Download to read offline




















![In MongoDB
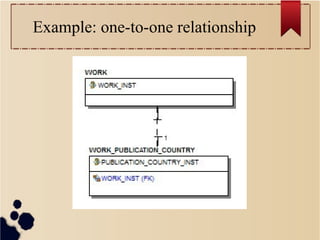
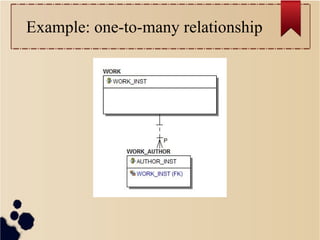
An array of “work contributors”
"work_contributor" : [
{
"contributorName" : "Ballauri, Jorgji S.",
"contributorRoleDescr" : "Author",
},
{
"contributorName" : "Maxwell, William",
"contributorRoleDescr" : "Editor",
},...
]](https://image.slidesharecdn.com/mongoboston2013-131029195141-phpapp02/85/No-More-SQL-22-320.jpg)














The document details the transition from a traditional relational database to MongoDB at the Copyright Clearance Center, highlighting the challenges and motivations behind this shift. Key issues addressed include data management practices, the need for horizontal scaling, and the benefits of MongoDB's flexible schema for handling diverse data types. Lessons learned during this migration underscore the importance of adapting relational practices to a document-oriented model and the complexities of data synchronization.

























![[Mas 500] Data Basics](https://cdn.slidesharecdn.com/ss_thumbnails/mas-500-4-data-basics-131120205428-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









































