Download to read offline

















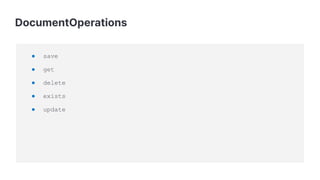

![StringQuery
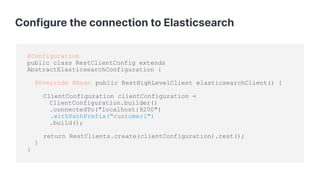
Query query = new StringQuery( "{" +
" "bool": {" +
" "must": [" +
" {" +
" "match": {" +
" "lastName": "Smith"" +
" }" +
" }" +
" ]" +
" }" +
"}");
SearchHits<Person> searchHits = operations.search(query,
Person.class);](https://image.slidesharecdn.com/copyofnextlevelelasticsearchintegrationwithspringdataelasticsearchelasticon-global-slides-16x9-2020-201030040210/85/Next-level-integration-with-Spring-Data-Elasticsearch-28-320.jpg)





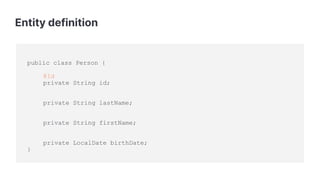
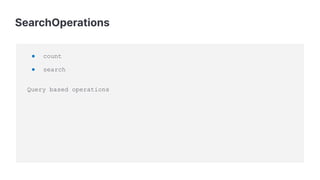
![Repository
count()
delete(T)
deleteAll()
deleteAll(Iterable<? extends T)
deleteById(ID)
existsById(ID)
findAll()
findAll(Pageable)
findAll(Sort)
findAllById(Iterable<ID>)
findById(ID)
save(T)
saveAll(Iterable<T>)
searchSimilar(T entity, String[] fields, Pageable pageable)](https://image.slidesharecdn.com/copyofnextlevelelasticsearchintegrationwithspringdataelasticsearchelasticon-global-slides-16x9-2020-201030040210/85/Next-level-integration-with-Spring-Data-Elasticsearch-35-320.jpg)






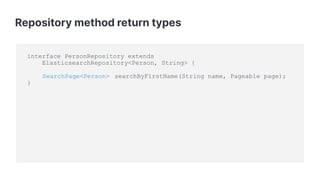



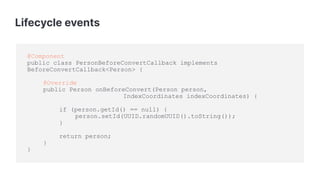




This presentation discusses Spring Data Elasticsearch, an open source project for integrating Elasticsearch with Spring applications. It provides an overview of key features like configuring Elasticsearch clients, defining entities, performing CRUD and search operations using repositories, and customizing behaviors through callbacks. The presenter encourages contributions to the community-driven project and provides contact details for further information.





![[ Pycon Korea 2017 ] Infrastructure as Code를위한 Ansible 활용](https://cdn.slidesharecdn.com/ss_thumbnails/pycon2017iacansible-170811160817-thumbnail.jpg?width=640&height=640&fit=bounds)






































![Modernising One Legal Se@rch with Elastic Enterprise Search [Customer Story]](https://cdn.slidesharecdn.com/ss_thumbnails/modernisingonelegalserchwithelastic-jsedit14thjune2021-210625013449-thumbnail.jpg?width=640&height=640&fit=bounds)













![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















