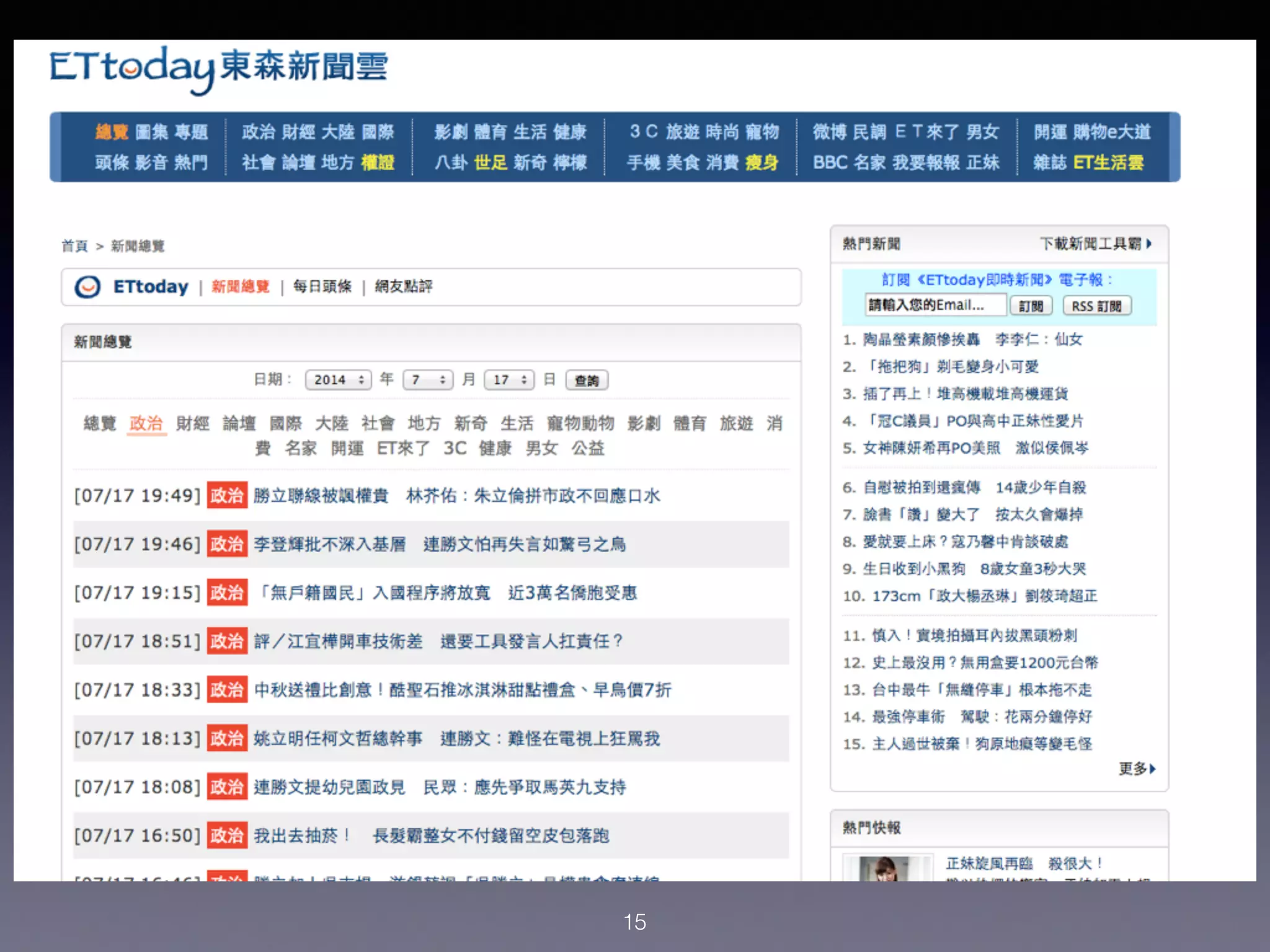
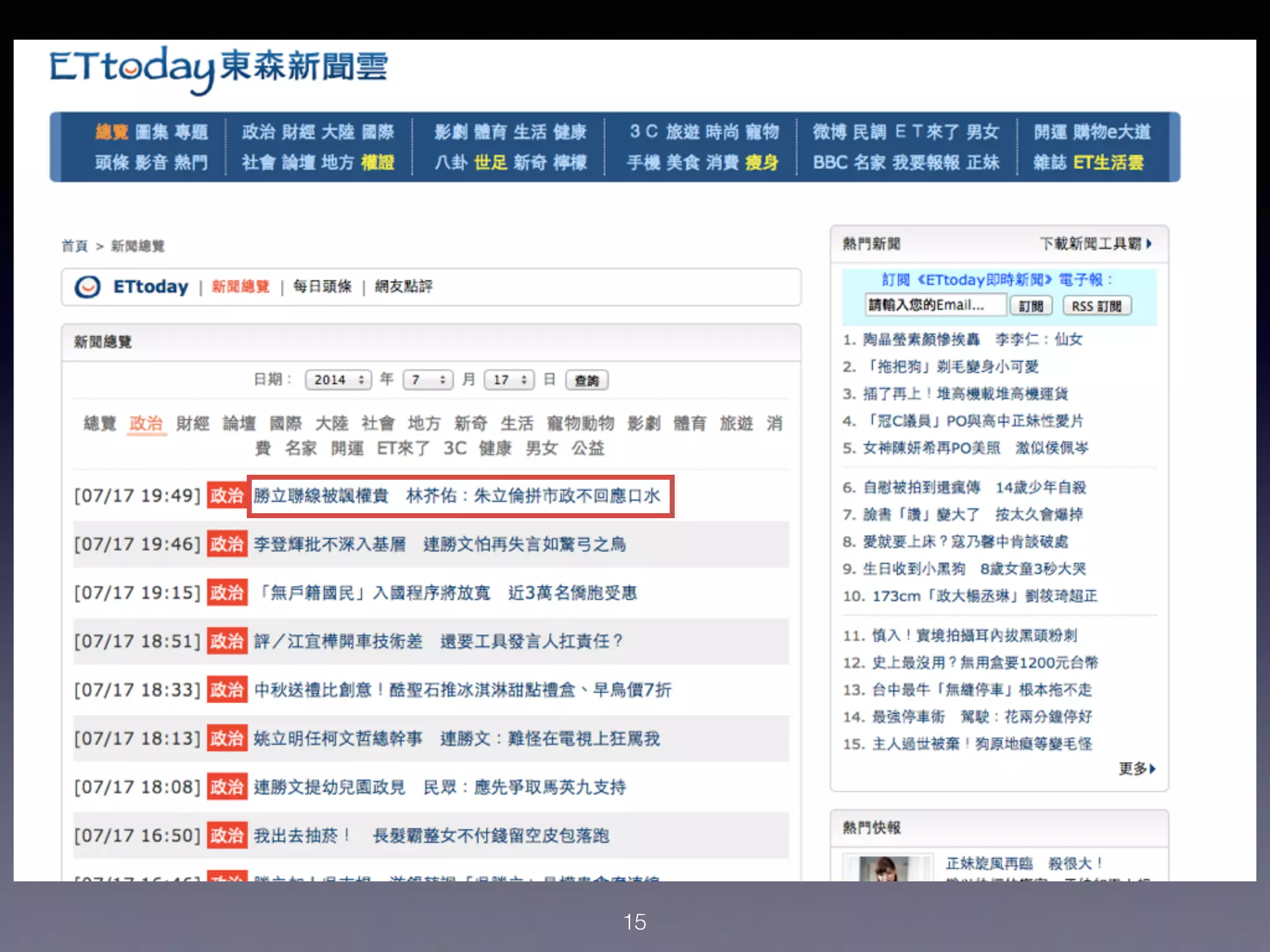
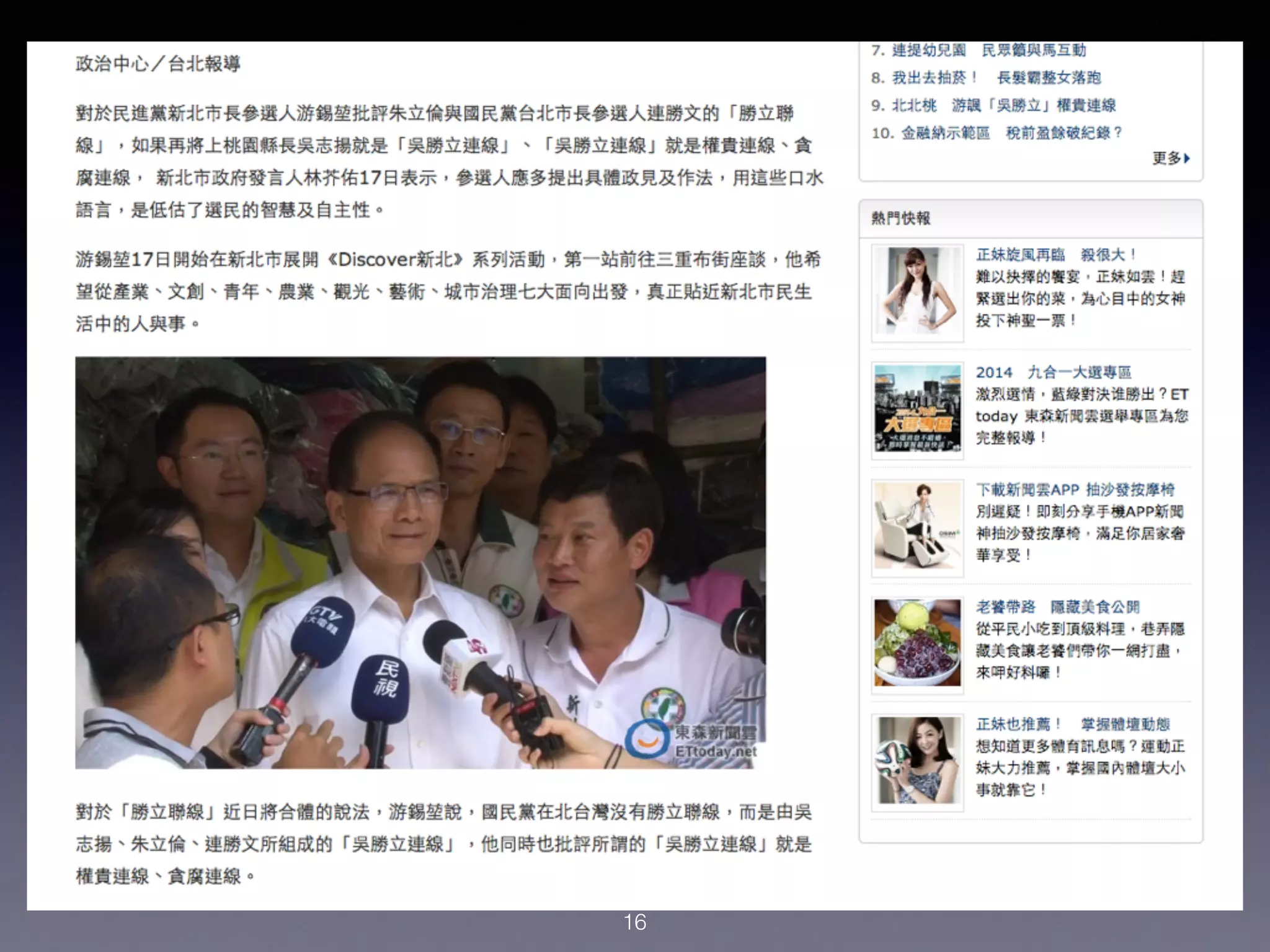
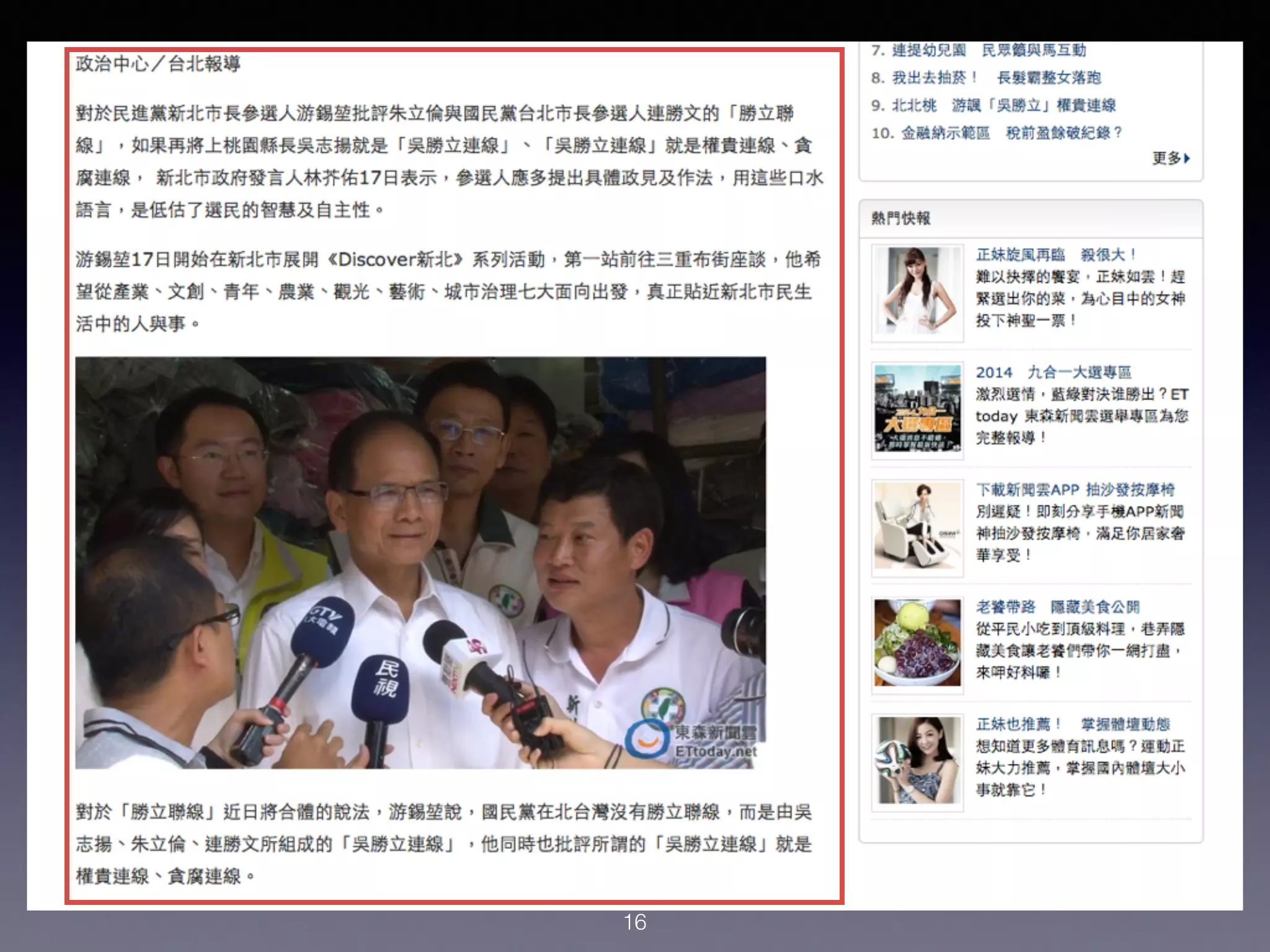
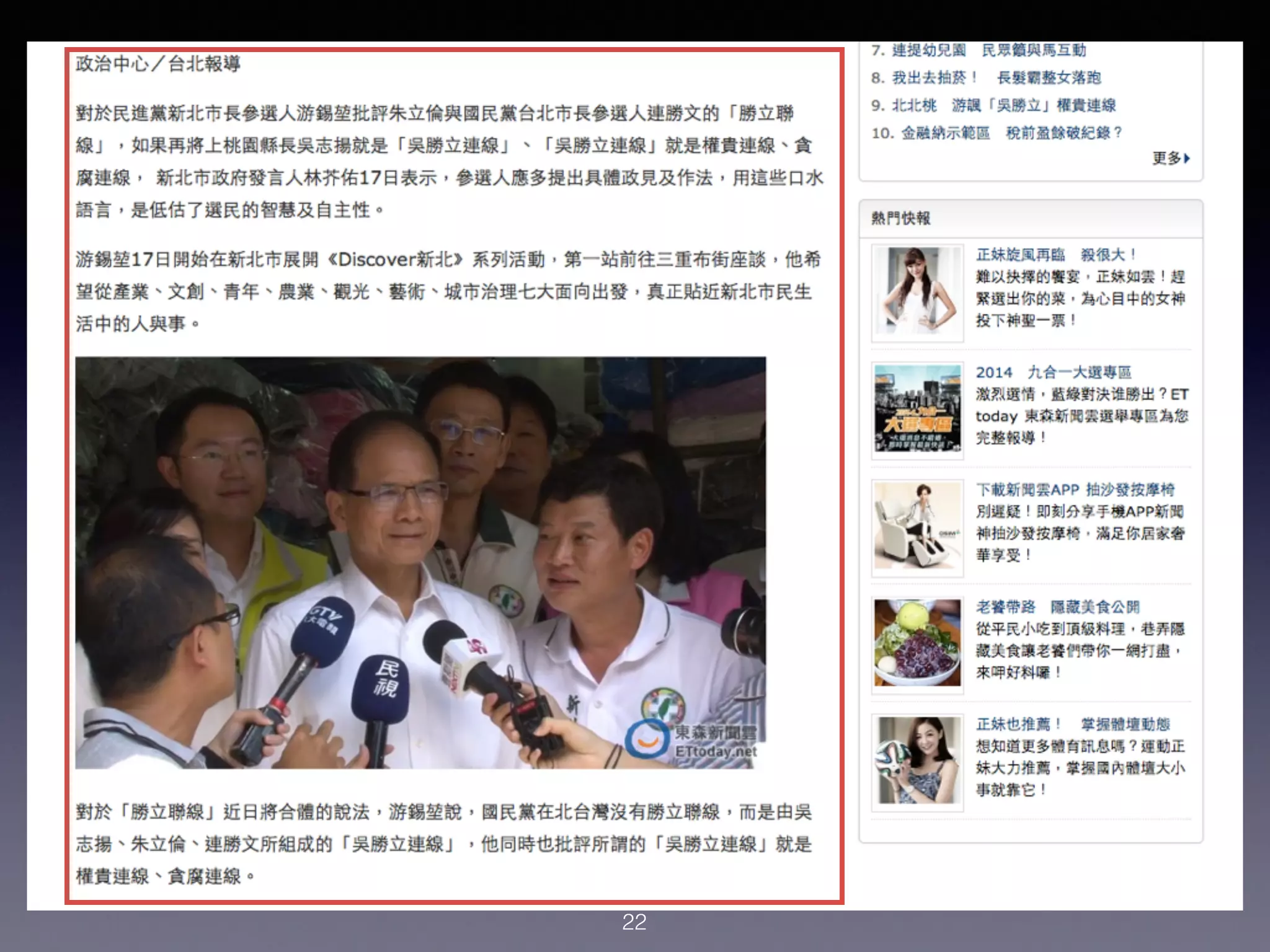
本讲座介绍了如何使用Python进行新闻抓取和简单的机器学习,以构建一个自动筛选新闻的系统。讨论了数据收集、特征提取以及如何应用机器学习算法来预测新闻的受欢迎程度。强调了整理数据的重要性以及Python在数据科学中的实用性。























![PyMongo
from pymongo import MongoClient!
!
client = MongoClient()!
db = client['news_database']!
news = db.news!
news.insert(data)!
news.find_one({'url': a['href']})!
26](https://image.slidesharecdn.com/news-140719112457-phpapp01/75/slide-30-2048.jpg)



















![[1, 0, 1, 0, 1…, 0, 1]
電腦看得懂這個...
41](https://image.slidesharecdn.com/news-140719112457-phpapp01/75/slide-51-2048.jpg)

























![[系列活動] Python 爬蟲實戰](https://cdn.slidesharecdn.com/ss_thumbnails/pythonafunjimv1-171213041823-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] Python 程式語言起步走](https://cdn.slidesharecdn.com/ss_thumbnails/python20170812-170808043244-thumbnail.jpg?width=640&height=640&fit=bounds)





![[台灣人工智慧學校] 人工智慧技術發展與應用](https://cdn.slidesharecdn.com/ss_thumbnails/version5-final-190319060225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] Python爬蟲實戰](https://cdn.slidesharecdn.com/ss_thumbnails/python-170809083644-thumbnail.jpg?width=640&height=640&fit=bounds)

































