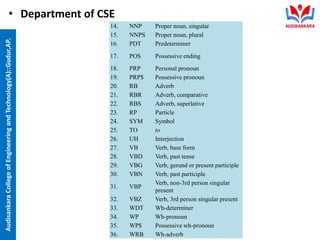
The document discusses natural language processing with a focus on syntactic analysis as part of the curriculum at Audisankara College of Engineering and Technology. Key topics include English word classes, part-of-speech tagging methods including Hidden Markov Models and Maximum Entropy Markov Models, treebanks, grammar rules, and lexicalized grammar. Various methods for part-of-speech tagging and the importance of syntax and semantics in language processing are outlined.









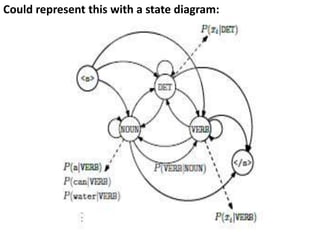
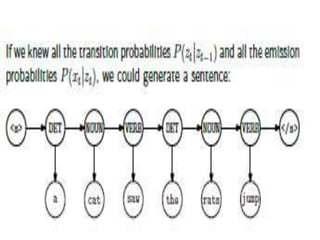



![We assumed that there are two states in the HMM and each of the
state corresponds to the selection of different biased coin.
Following matrix gives the state transition probabilities −
[Math Processing Error]=[11122122]](https://image.slidesharecdn.com/unit-iippts-240611041858-4d85ec60/85/Natural-language-processing-UNIT-II-PPTS-pptx-16-320.jpg)


























































