Download as PDF, PPTX

























![Map Hashtags in Python
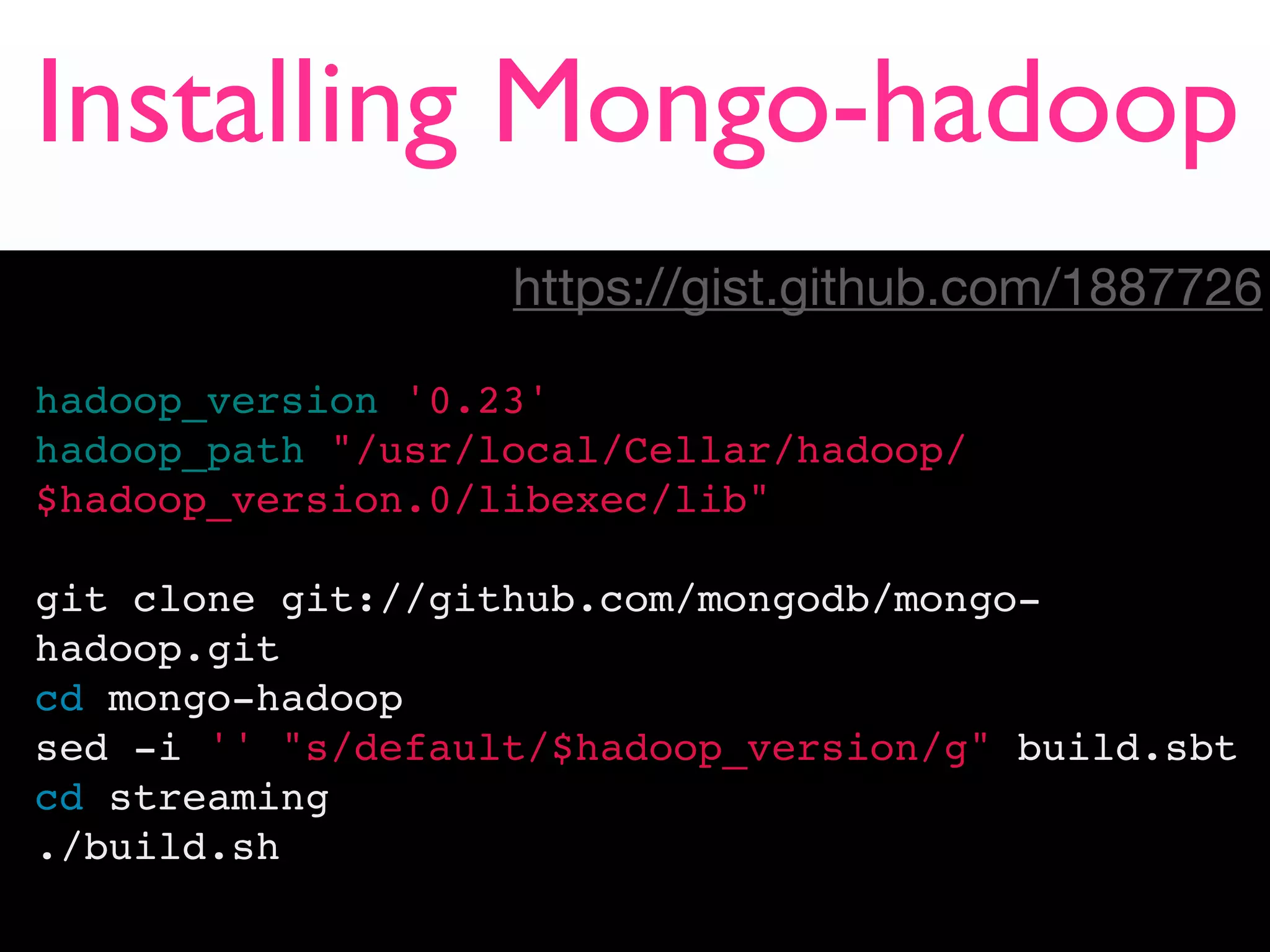
#!/usr/bin/env python
import sys
sys.path.append(".")
from pymongo_hadoop import BSONMapper
def mapper(documents):
for doc in documents:
for hashtag in doc['entities']['hashtags']:
yield {'_id': hashtag['text'], 'count': 1}
BSONMapper(mapper)
print >> sys.stderr, "Done Mapping."](https://image.slidesharecdn.com/mongodbhadoopandhumongousmongosv2012-121205192507-phpapp01/75/MongoDB-Hadoop-and-humongous-data-MongoSV-2012-36-2048.jpg)
![Reduce hashtags in Python
#!/usr/bin/env python
import sys
sys.path.append(".")
from pymongo_hadoop import BSONReducer
def reducer(key, values):
print >> sys.stderr, "Hashtag %s" % key.encode('utf8')
_count = 0
for v in values:
_count += v['count']
return {'_id': key.encode('utf8'), 'count': _count}
BSONReducer(reducer)](https://image.slidesharecdn.com/mongodbhadoopandhumongousmongosv2012-121205192507-phpapp01/75/MongoDB-Hadoop-and-humongous-data-MongoSV-2012-37-2048.jpg)




![Popular Hash Tags
db.twit_hashtags.aggregate(a){
"result" : [
{ "_id" : "YouKnowYoureInLoveIf", "count" : 287 },
{ "_id" : "teamfollowback", "count" : 200 },
{ "_id" : "RT", "count" : 150 },
{ "_id" : "Arsenal", "count" : 148 },
{ "_id" : "milars", "count" : 145 },
{ "_id" : "sanremo","count" : 145 },
{ "_id" : "LoseMyNumberIf", "count" : 139 },
{ "_id" : "RelationshipsShould", "count" : 137 },
{ "_id" : "Bahrain", "count" : 129 },
{ "_id" : "bahrain", "count" : 125 }
],"ok" : 1
}](https://image.slidesharecdn.com/mongodbhadoopandhumongousmongosv2012-121205192507-phpapp01/75/MongoDB-Hadoop-and-humongous-data-MongoSV-2012-42-2048.jpg)


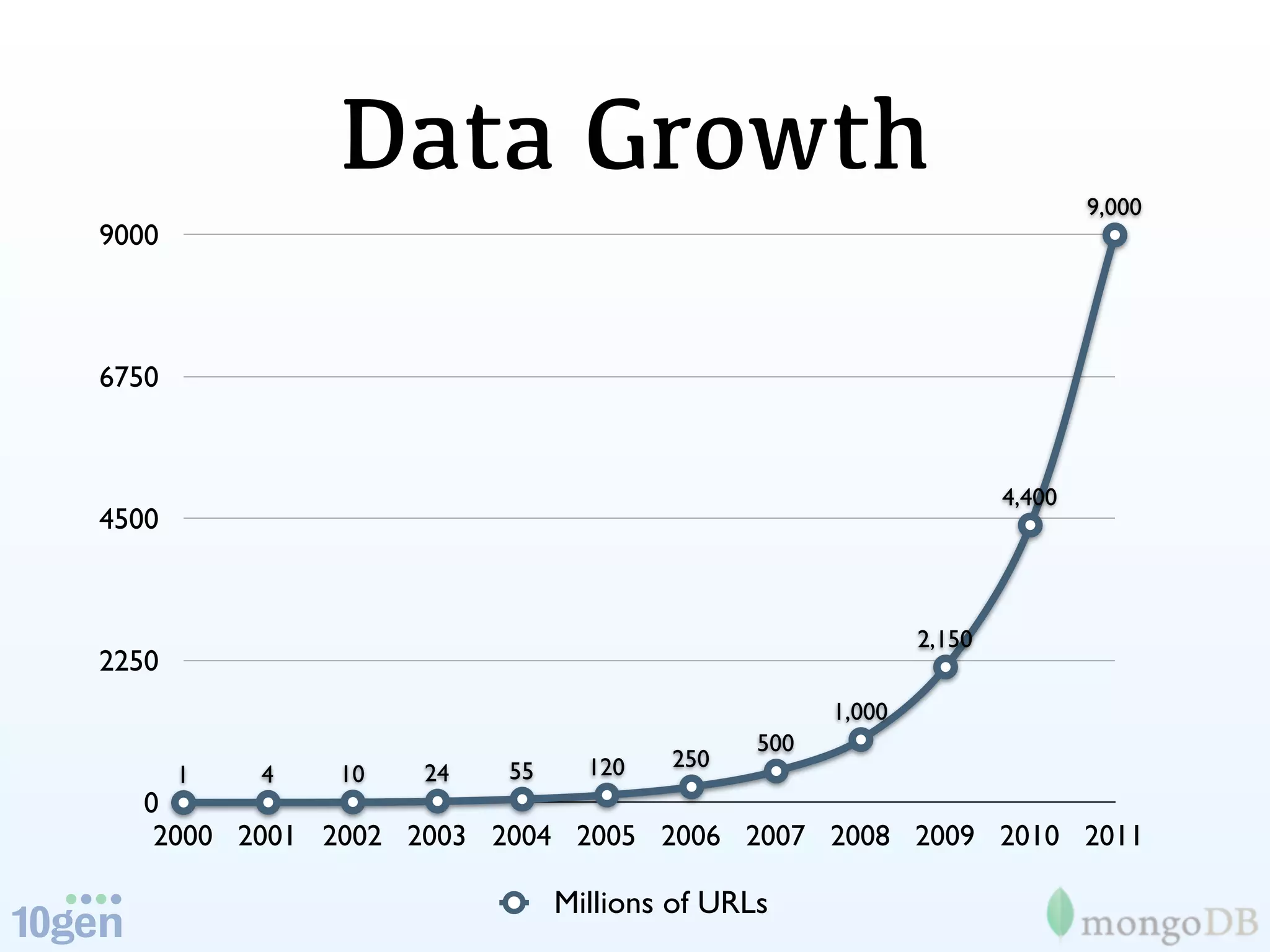
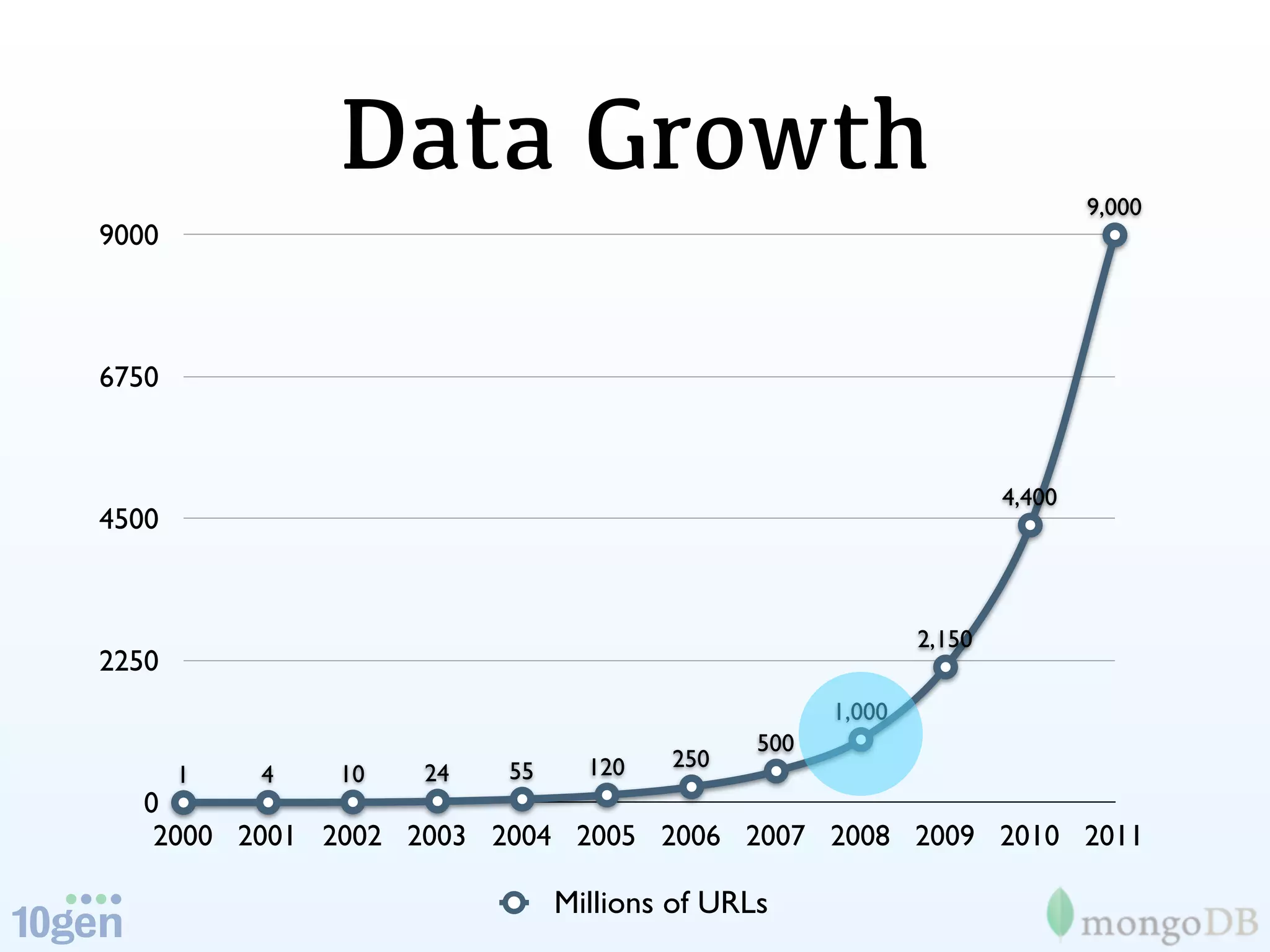







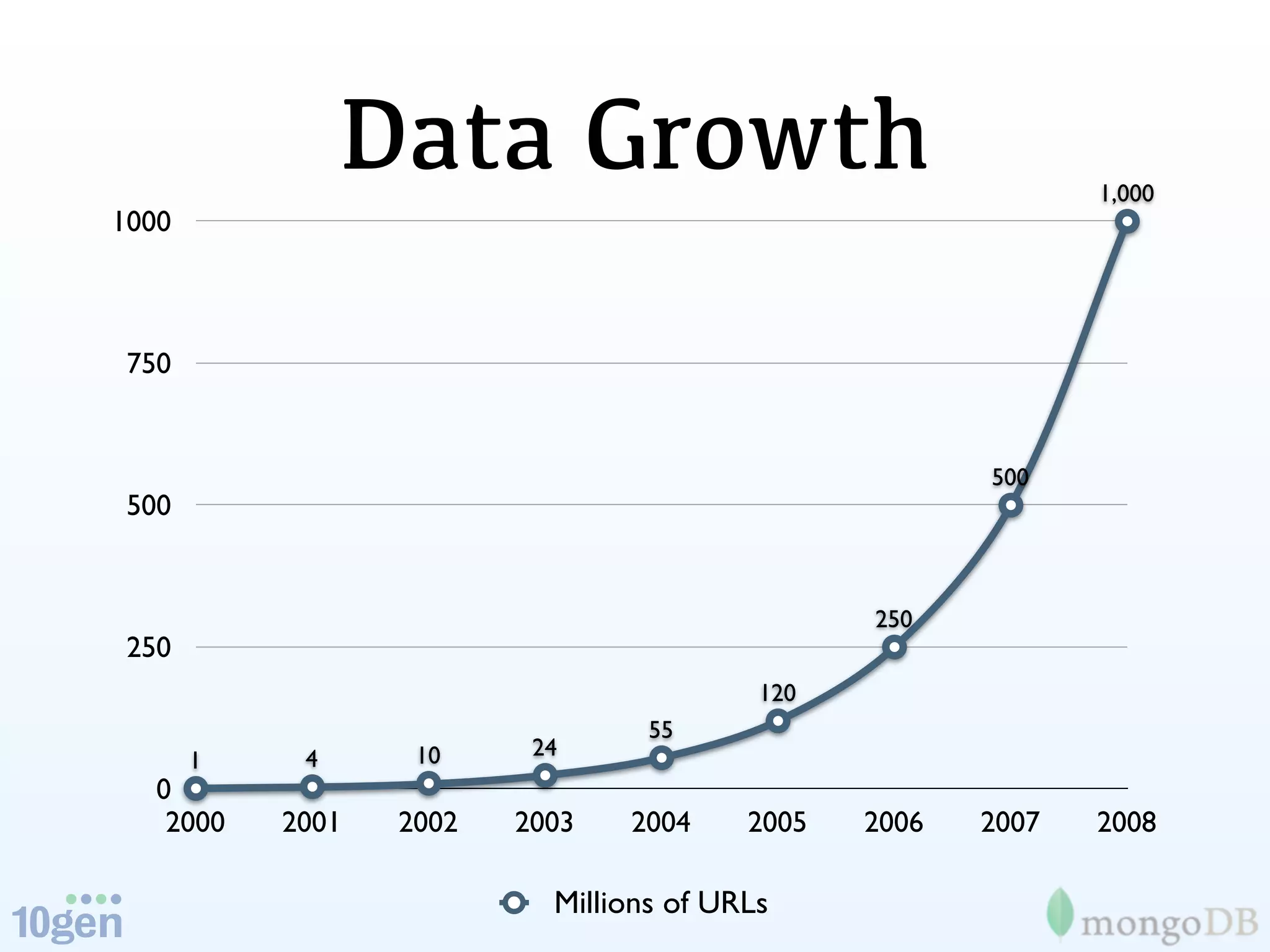
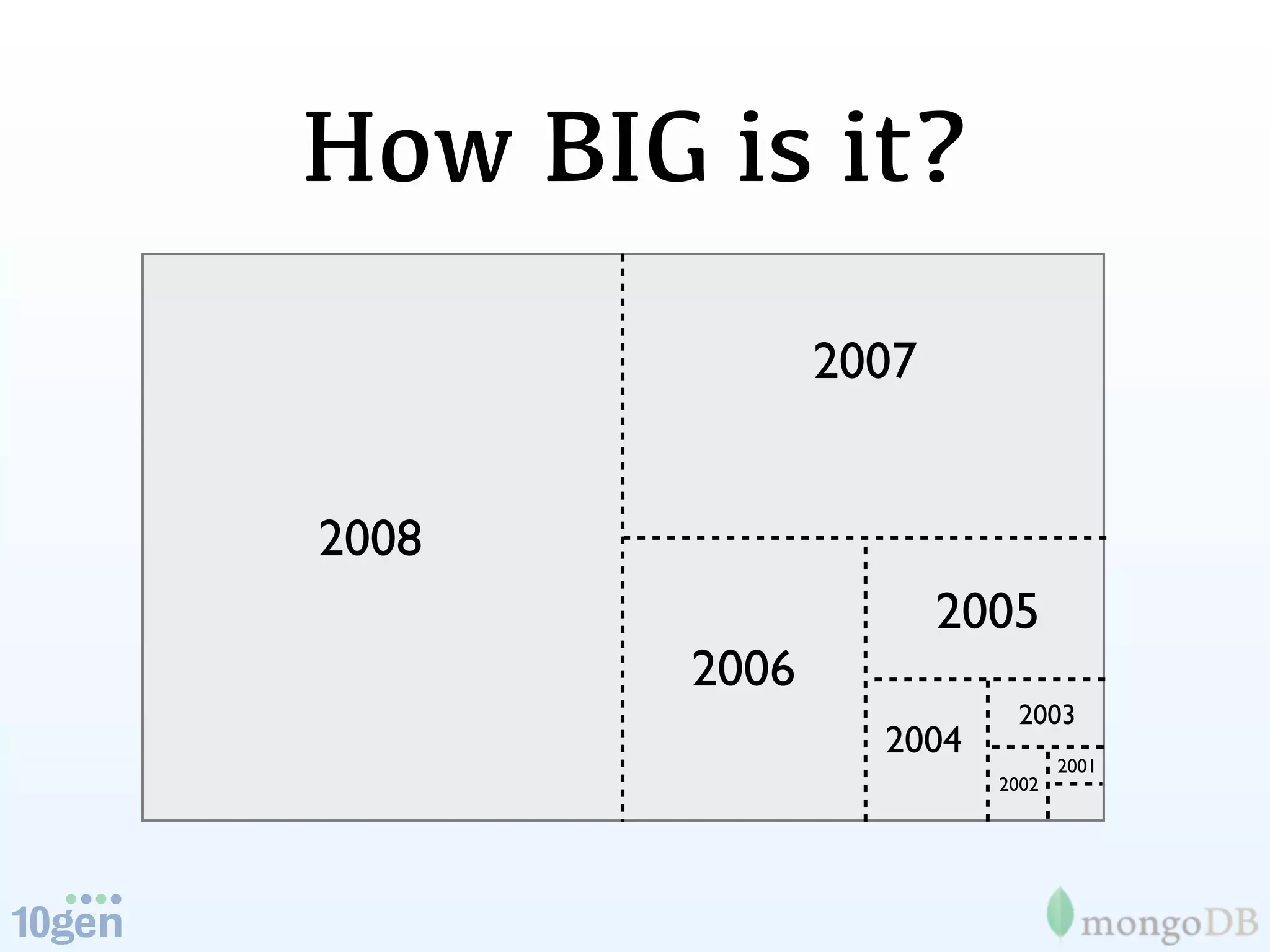
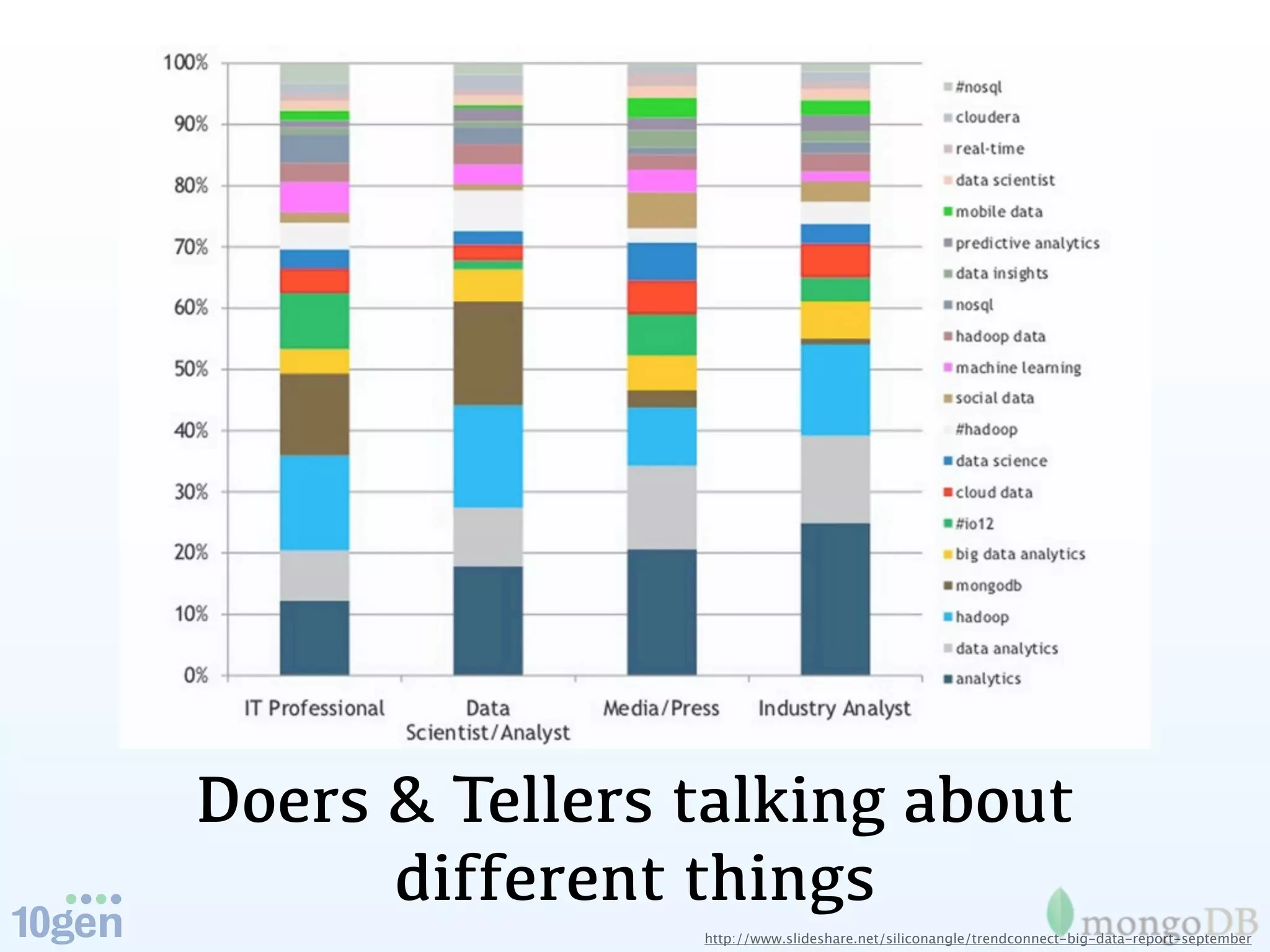
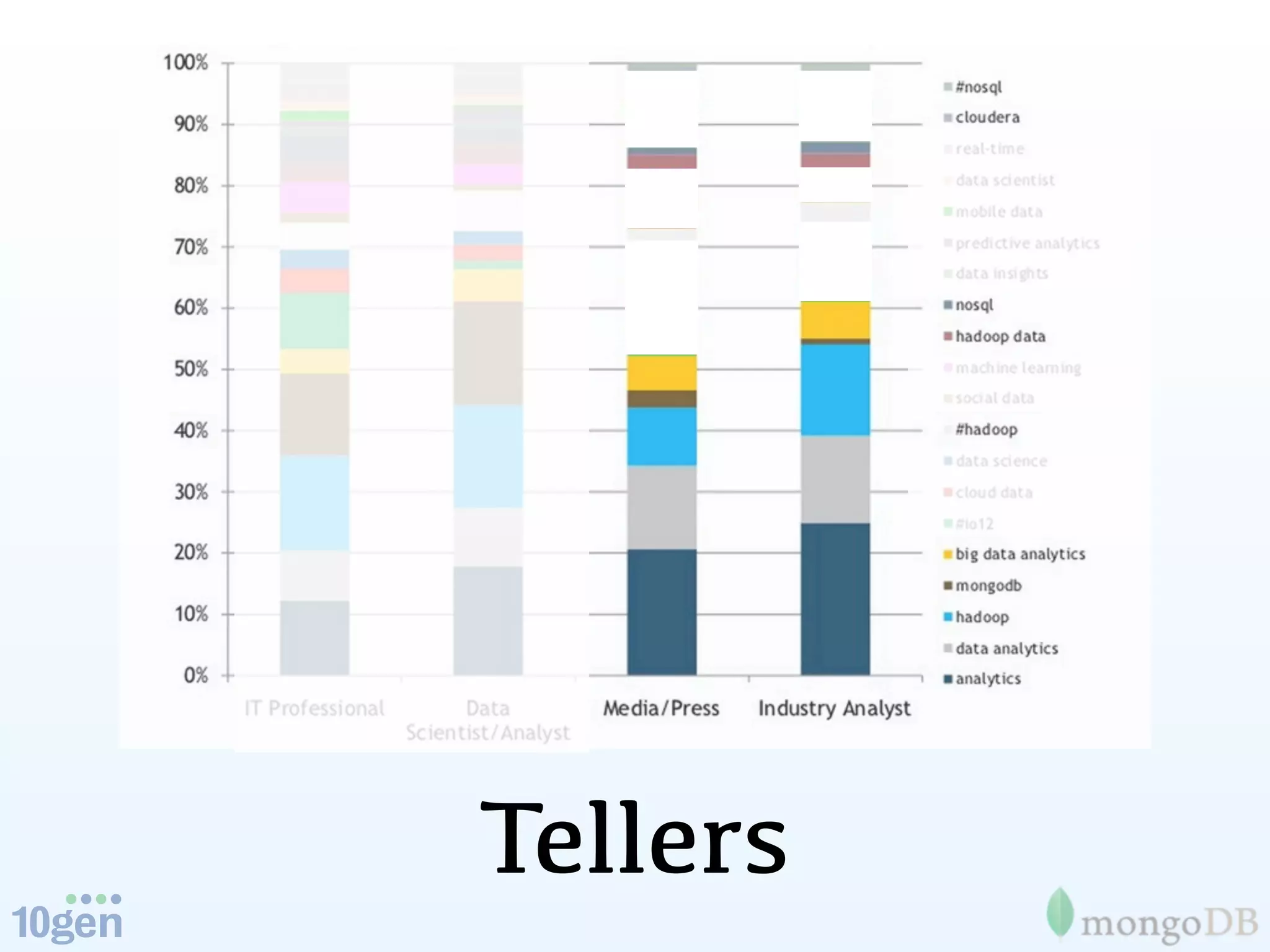
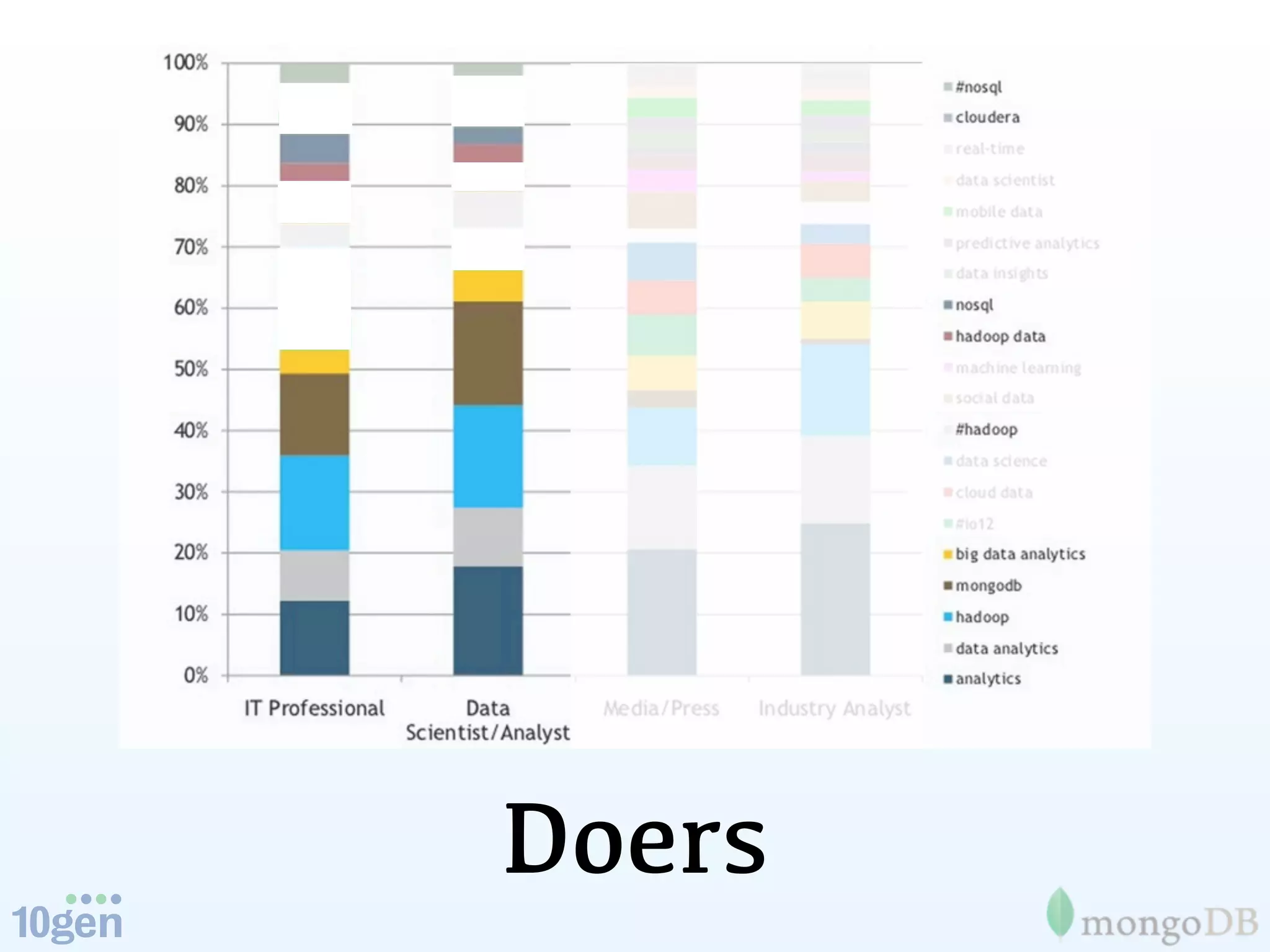
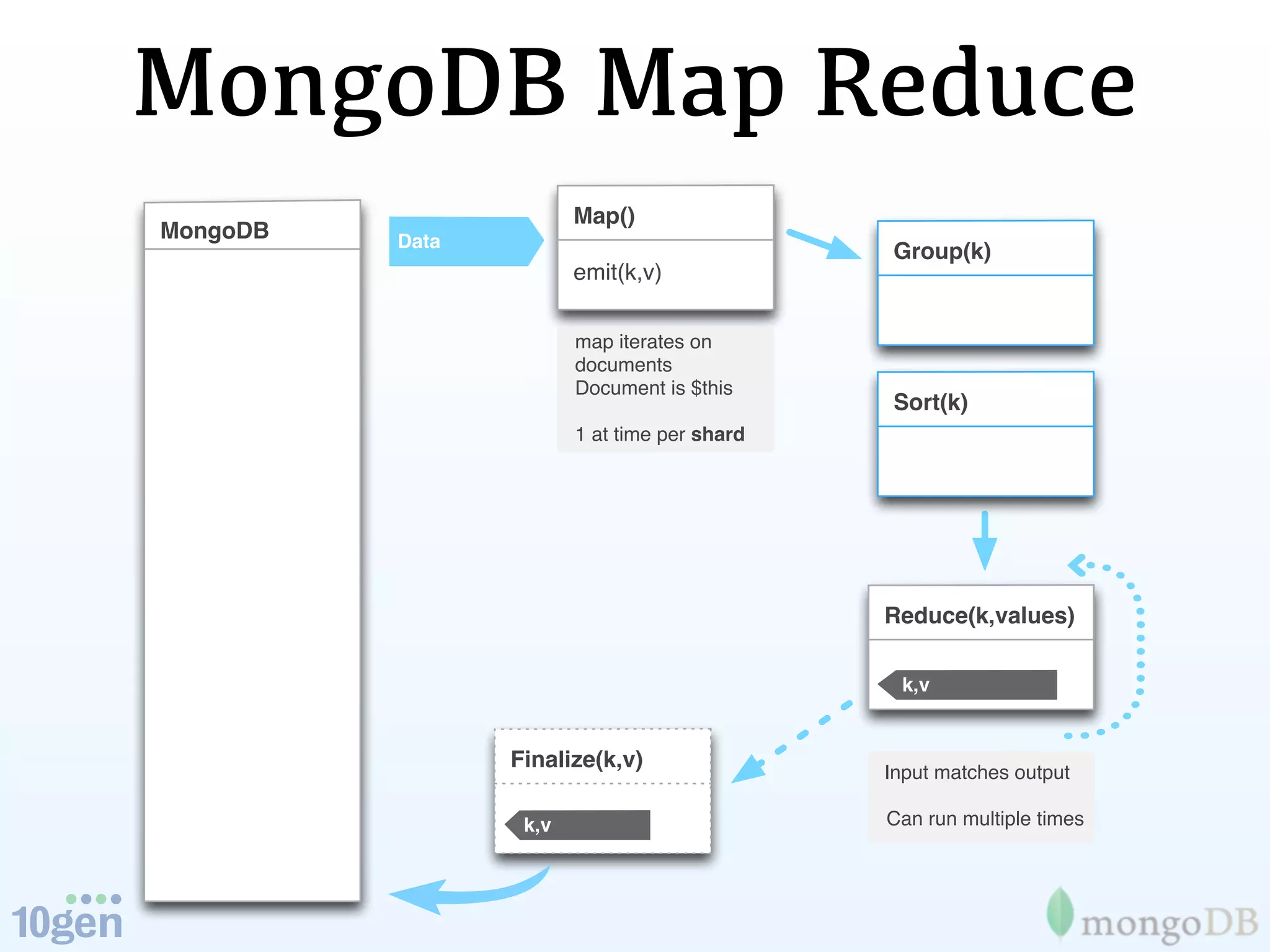
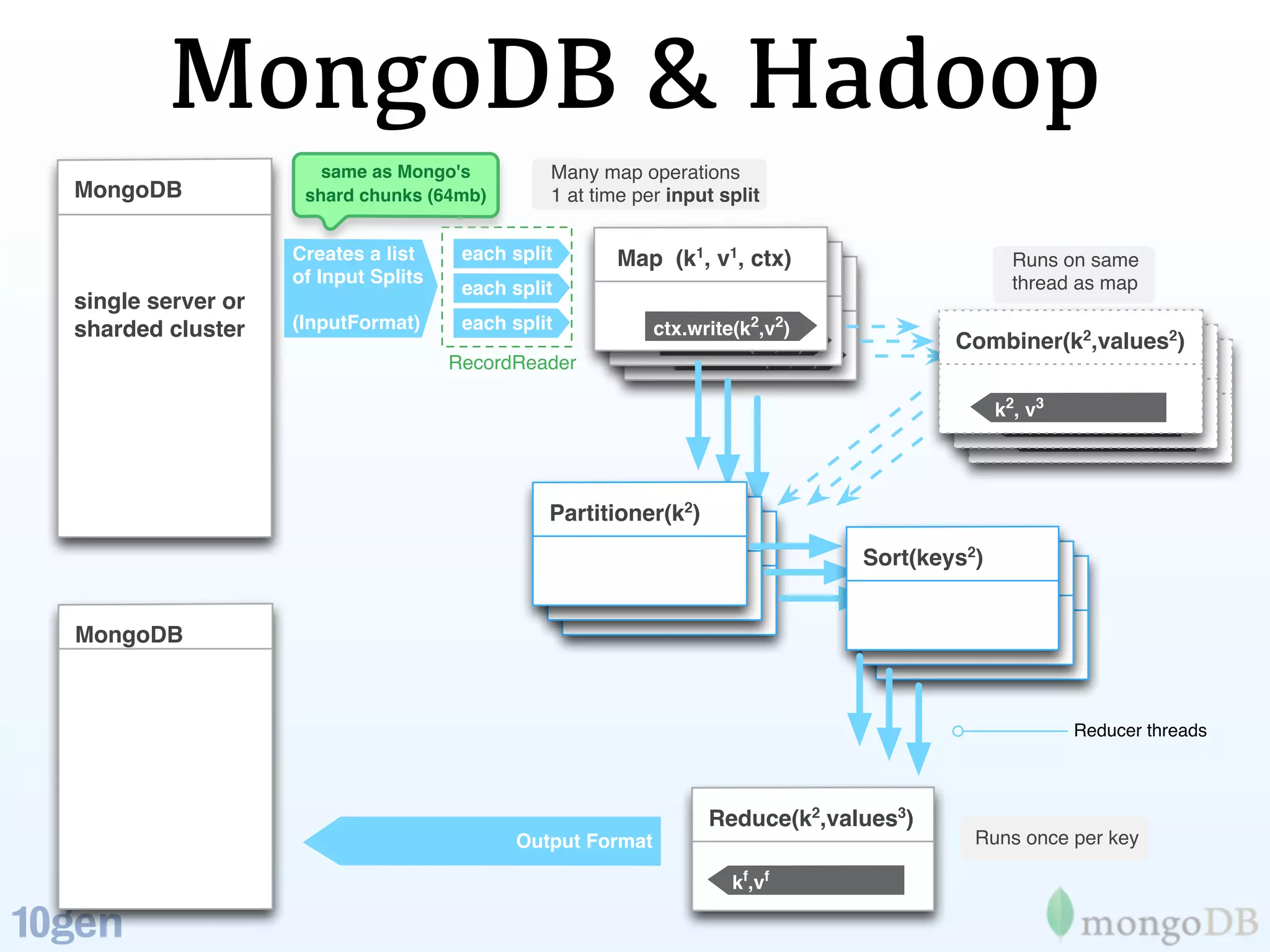
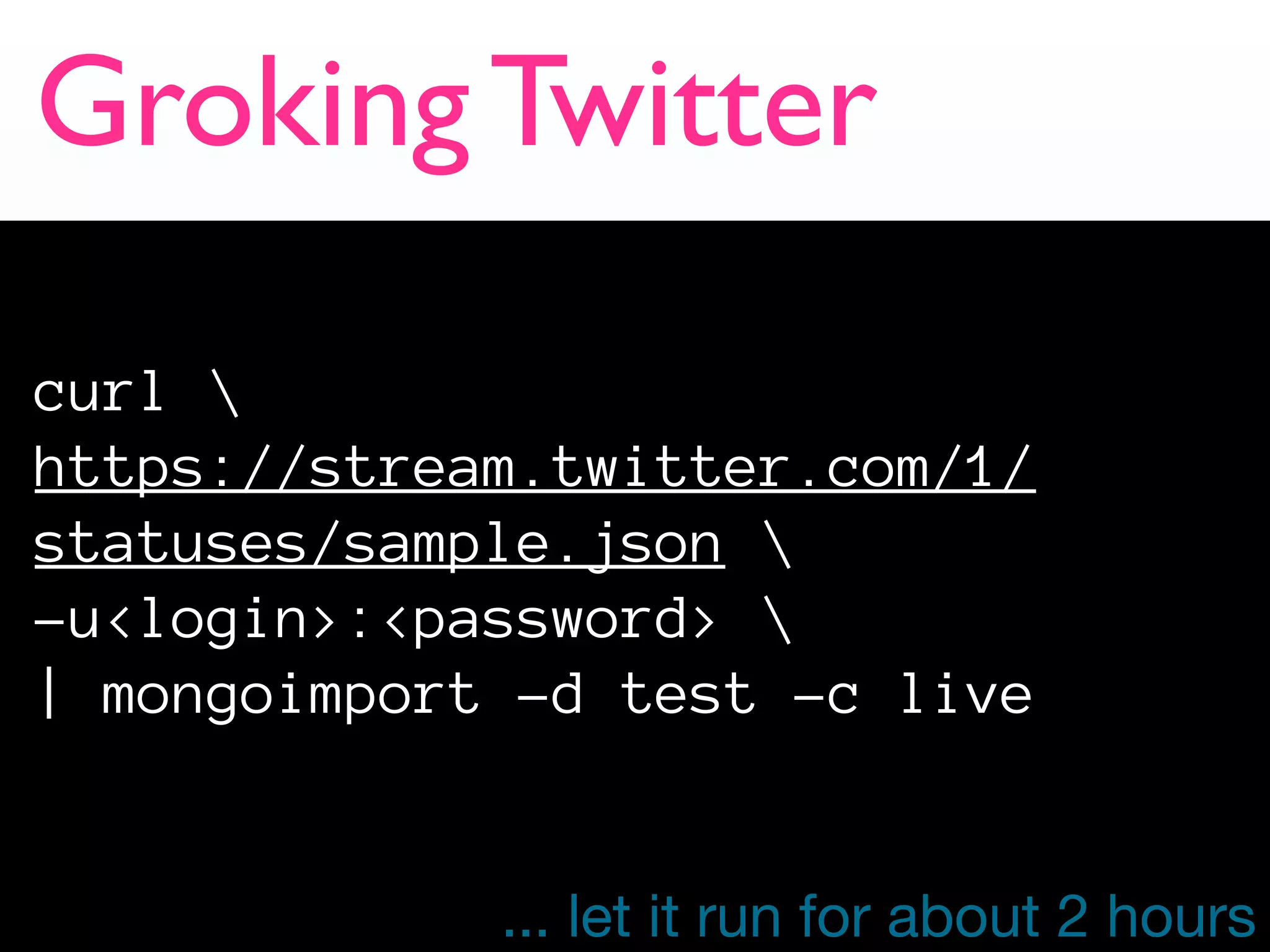
The document discusses the concept of 'humongous data' and the exponential growth of data from 2000 to 2012, highlighting the advancements in data processing technologies such as MongoDB and Hadoop. It explains the applications of these technologies in handling large datasets, including methods like map-reduce and aggregation for processing data. The future of data is emphasized, with predictions of continued growth and the importance of tools like Hadoop and Storm in managing and analyzing big data.




































































































