Downloaded 182 times




























![MongoDB is:
Application Document
Oriented
High { author: “steve”,
date: new Date(),
Performanc
text: “About MongoDB...”,
tags: [“tech”, “database”]}
e
Horizontally Scalable](https://image.slidesharecdn.com/mongodb-slc2011-111020102909-phpapp01/75/MongoDB-30-2048.jpg)









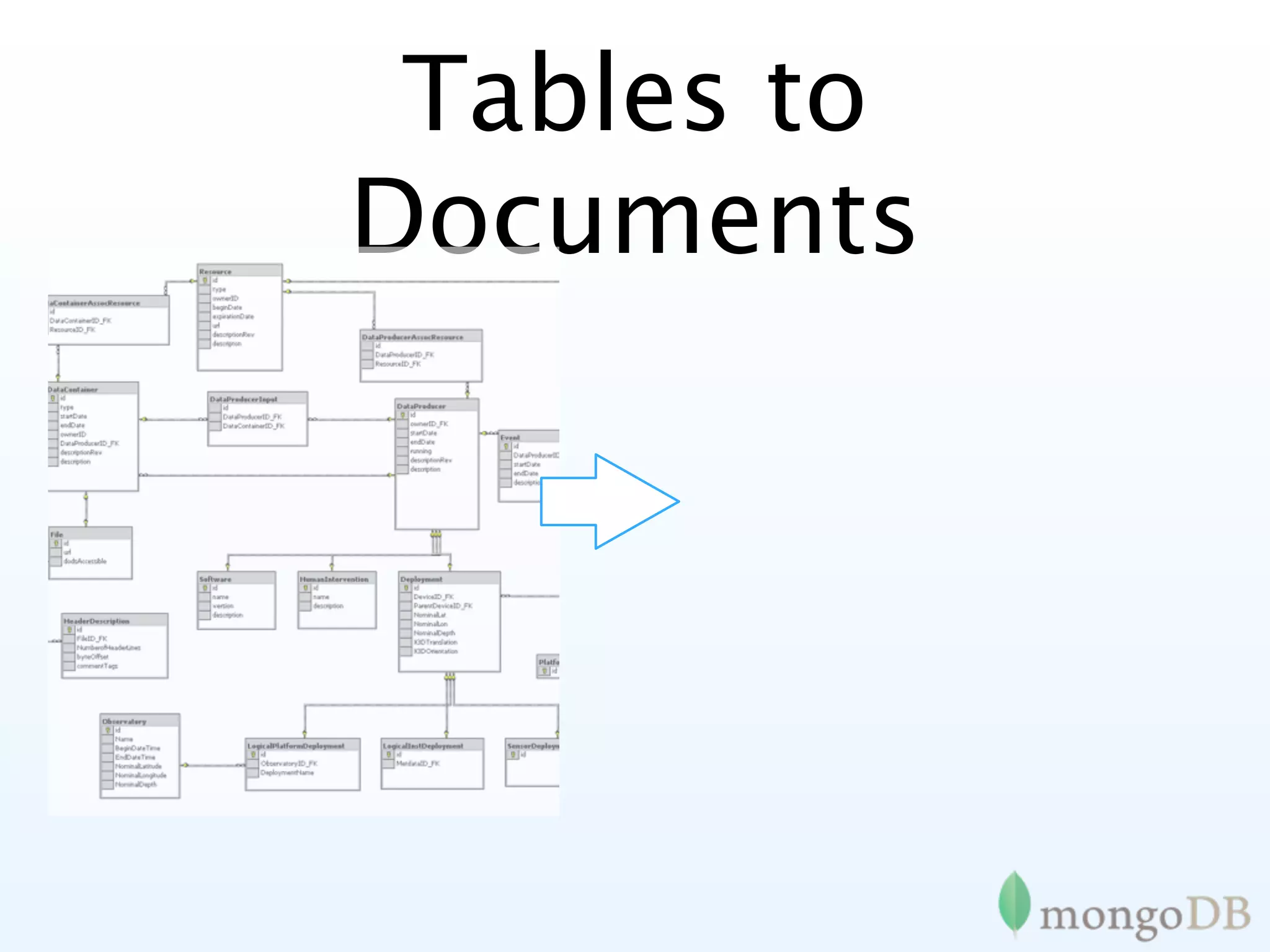
![Tables to
Documents
{
title: ‘MongoDB’,
contributors: [
{ name: ‘Eliot Horowitz’,
email: ‘eh@10gen.com’ },
{ name: ‘Dwight Merriman’,
email: ‘dm@10gen.com’ }
],
model: {
relational: false,
awesome: true
}](https://image.slidesharecdn.com/mongodb-slc2011-111020102909-phpapp01/75/MongoDB-44-2048.jpg)

![Documents
Blog Post Document
> p = {author: “roger”,
date: new Date(),
text: “about mongoDB...”,
tags: [“tech”, “databases”]}
> db.posts.save(p)](https://image.slidesharecdn.com/mongodb-slc2011-111020102909-phpapp01/75/MongoDB-46-2048.jpg)
![Querying
> db.posts.find()
> { _id : ObjectId("4c4ba5c0672c685e5e8aabf3"),
author : "roger",
date : "Sat Jul 24 2010 19:47:11",
text : "About MongoDB...",
tags : [ "tech", "databases" ] }
Note: _id is unique, but can be
anything you’d like](https://image.slidesharecdn.com/mongodb-slc2011-111020102909-phpapp01/75/MongoDB-47-2048.jpg)






![Nested Documents
{ _id : ObjectId("4c4ba5c0672c685e5e8aabf3"),
author : "roger",
date : "Sat Apr 24 2011 19:47:11",
text : "About MongoDB...",
tags : [ "tech", "databases" ],
comments : [
{
author : "Fred",
date : "Sat Apr 25 2010 20:51:03 GMT-0700",
text : "Best Post Ever!"
}
]
}](https://image.slidesharecdn.com/mongodb-slc2011-111020102909-phpapp01/75/MongoDB-54-2048.jpg)
![Secondary Indexes
// Index nested documents
> db.posts.ensureIndex( “comments.author”: 1)
> db.posts.find({‘comments.author’:’Fred’})
// Index on tags (multi-key index)
> db.posts.ensureIndex( tags: 1)
> db.posts.find( { tags: ‘tech’ } )
// geospatial index
> db.posts.ensureIndex( “author.location”: “2d” )
> db.posts.find( “author.location”: { $near : [22,42] } )](https://image.slidesharecdn.com/mongodb-slc2011-111020102909-phpapp01/75/MongoDB-55-2048.jpg)
![Rich Documents
{ _id : ObjectId("4c4ba5c0672c685e5e8aabf3"),
line_items : [ { sku: ‘tt-123’,
name: ‘Coltrane: Impressions’ },
{ sku: ‘tt-457’,
name: ‘Davis: Kind of Blue’ } ],
address : { name: ‘Banker’,
street: ‘111 Main’,
zip: 10010 },
payment: { cc: 4567,
exp: Date(2011, 7, 7) },
subtotal: 2355
}](https://image.slidesharecdn.com/mongodb-slc2011-111020102909-phpapp01/75/MongoDB-56-2048.jpg)




![Creating a Replica
Set
> cfg = {
_id : "acme_a",
members : [
{ _id : 0, host : "sf1.acme.com" },
{ _id : 1, host : "sf2.acme.com" },
{ _id : 2, host : "sf3.acme.com" } ] }
> use admin
> db.runCommand( { replSetInitiate : cfg } )](https://image.slidesharecdn.com/mongodb-slc2011-111020102909-phpapp01/75/MongoDB-66-2048.jpg)


![Safe Writes
• db.runCommand({getLastError: 1, w : 1})
• - ensure write is synchronous
• - command returns after primary has written to memory
• w=n or w='majority'
• n is the number of nodes data must be replicated to
• driver will always send writes to Primary
• w='myTag' [MongoDB 2.0]
• Each member is "tagged" e.g. "US_EAST", "EMEA",
"US_WEST"
• Ensure that the write is executed in each tagged "region"](https://image.slidesharecdn.com/mongodb-slc2011-111020102909-phpapp01/75/MongoDB-69-2048.jpg)


























![Tagging - example
{
_id : "mySet",
members : [
{_id : 0, host : "A", tags : {"dc": "ny"}},
{_id : 1, host : "B", tags : {"dc": "ny"}},
{_id : 2, host : "C", tags : {"dc": "sf"}},
{_id : 3, host : "D", tags : {"dc": "sf"}},
{_id : 4, host : "E", tags : {"dc": "cloud"}}]
settings : {
getLastErrorModes : {
allDCs : {"dc" : 3},
someDCs : {"dc" : 2}} }
}
> db.blogs.insert({...})
> db.runCommand({getLastError : 1, w : "allDCs"})](https://image.slidesharecdn.com/mongodb-slc2011-111020102909-phpapp01/75/MongoDB-102-2048.jpg)













The document provides an overview of MongoDB, detailing its advantages such as agility from a schemaless data model, scalability for handling large datasets, and cost-effectiveness. It discusses MongoDB's architecture, including features like replication, sharding, and its compatibility with various programming languages. Additionally, it highlights use cases demonstrating significant performance and cost improvements over traditional relational databases.
Introduction to MongoDB presented by Steve Francia, detailing his background and experience.
Key features of MongoDB include agility, scalability, and cost-effectiveness for modern data management.
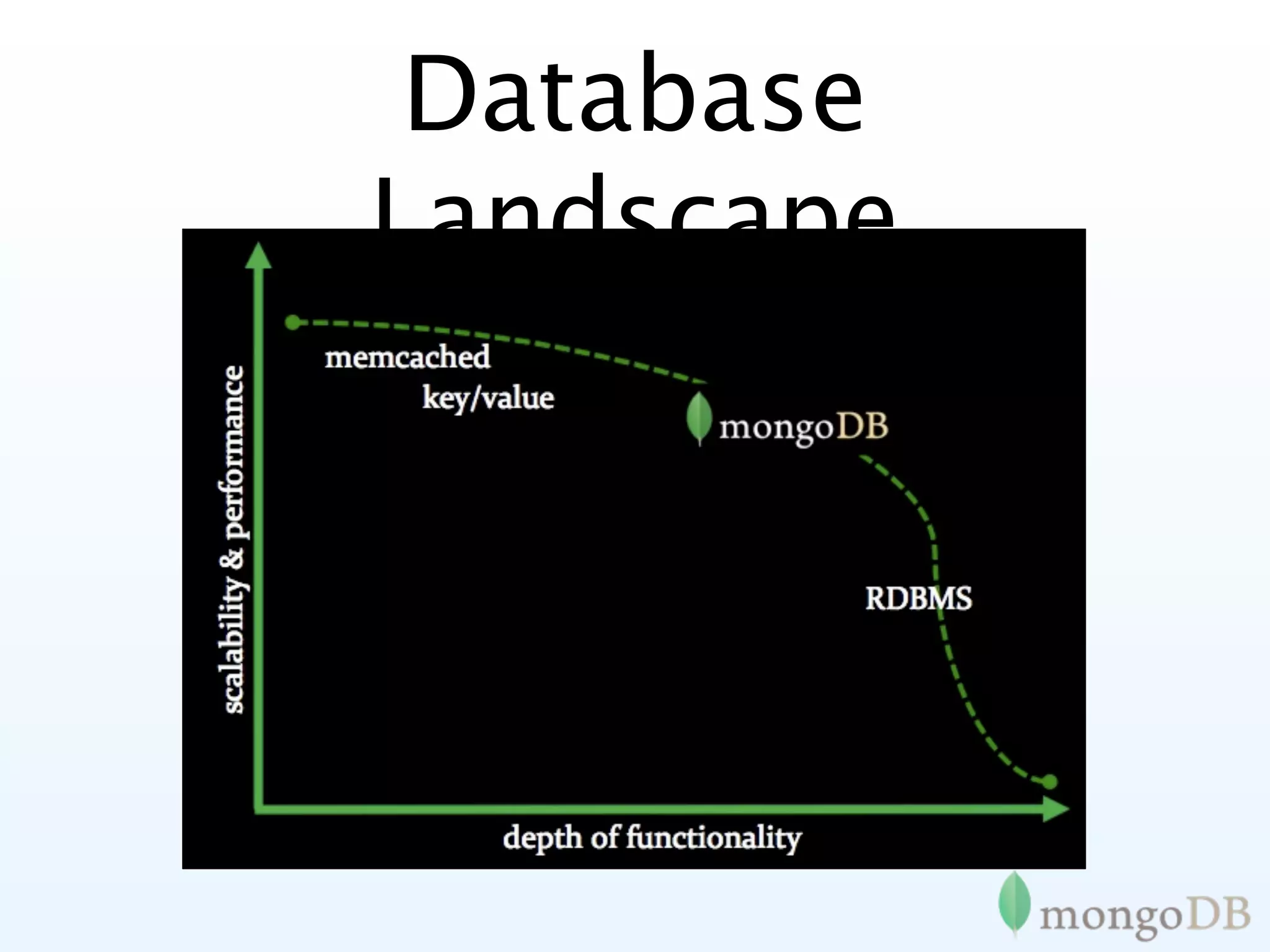
Timeline of database evolution highlighting the shift towards non-relational systems for scalability and flexibility.
MongoDB aims for a non-relational approach that enhances agility, maintaining functionality while enabling scalability.
Description of MongoDB's document-oriented model, automatic sharding, and performance capabilities.
Examples illustrating MongoDB's effectiveness in various scenarios leading to significant cost and performance gains.
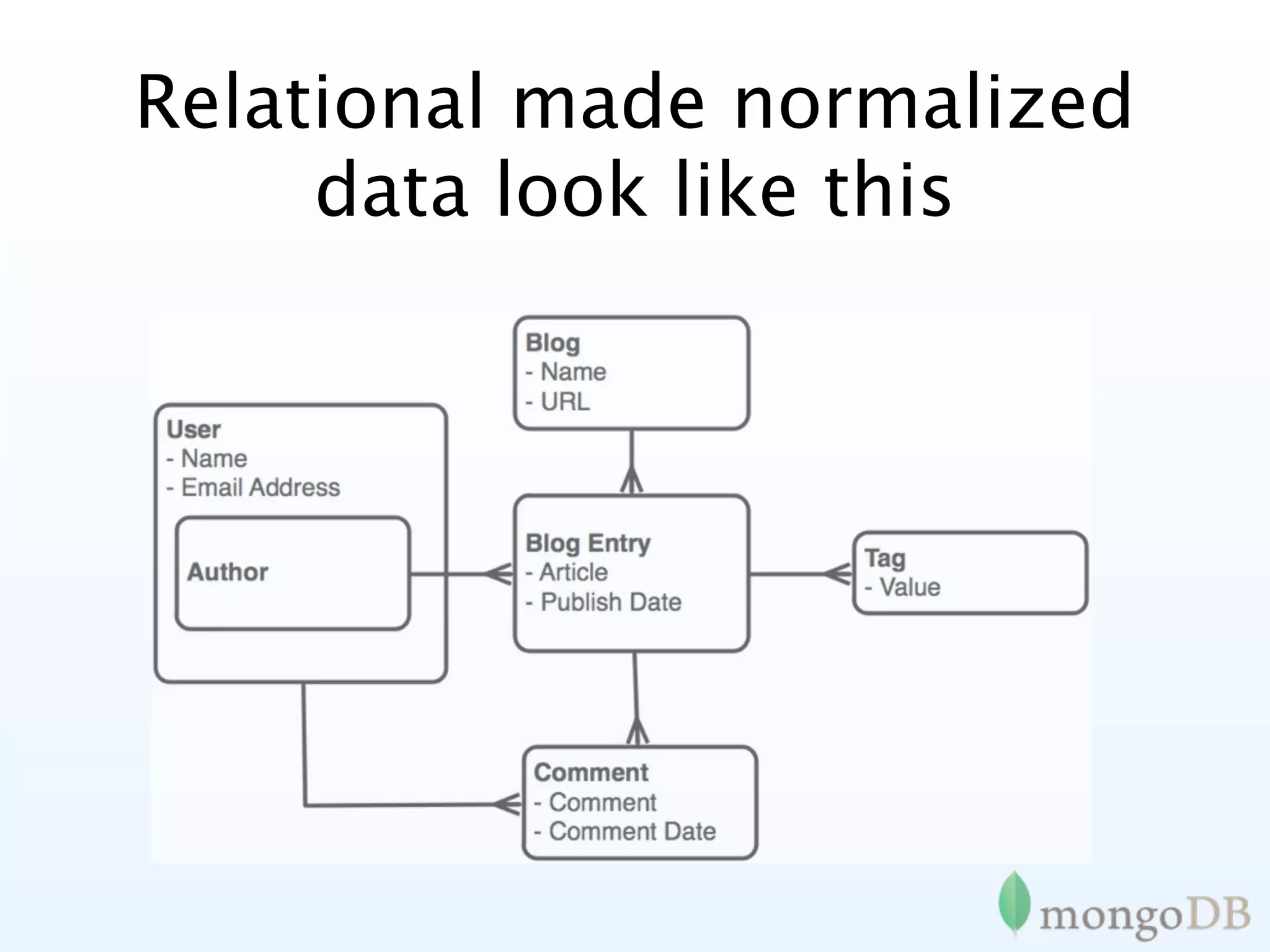
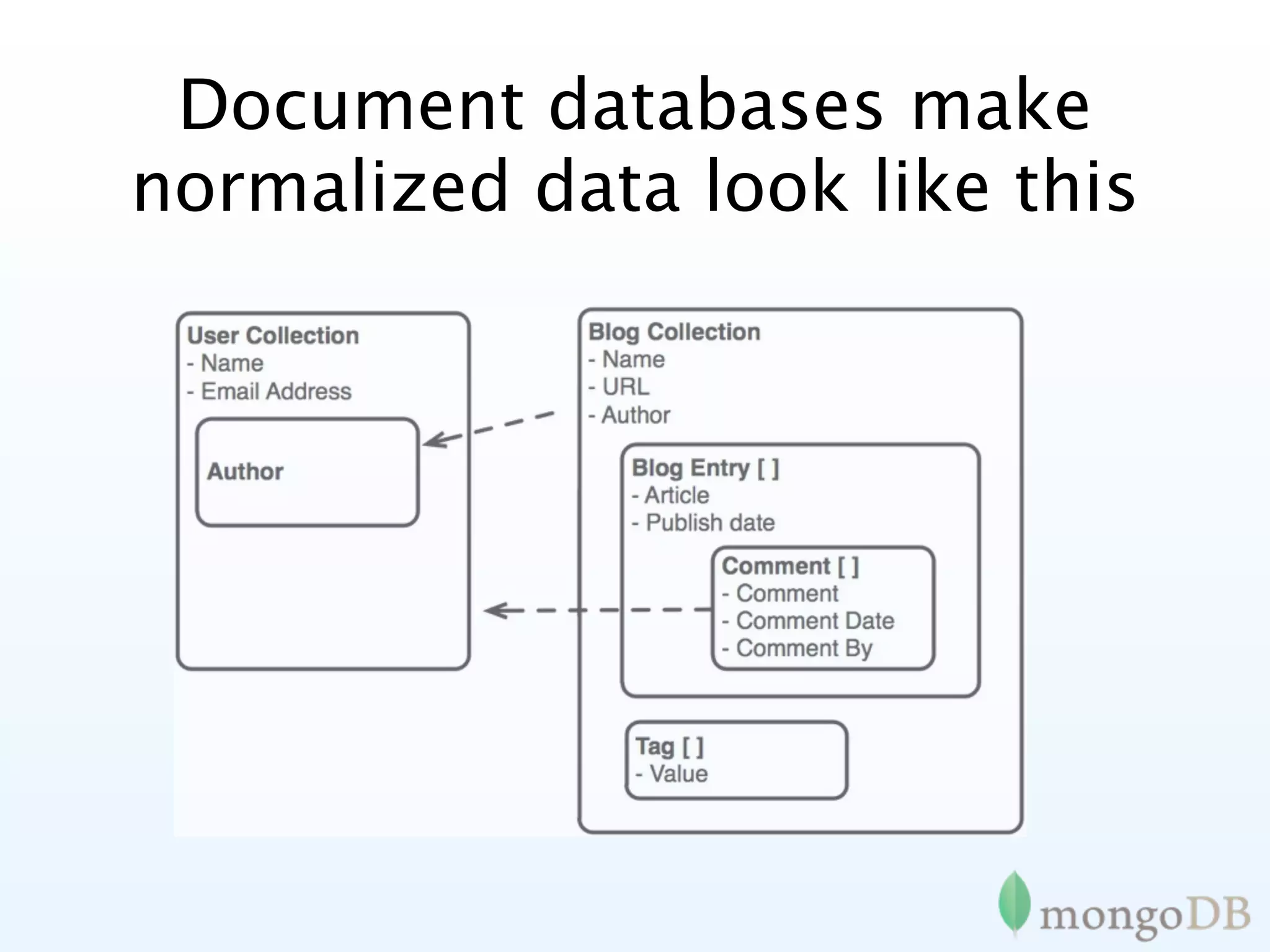
Contrast between relational and document databases, showcasing how MongoDB handles normalized data.
Demonstration of document handling, querying, and indexing in MongoDB, showcasing its functionalities.
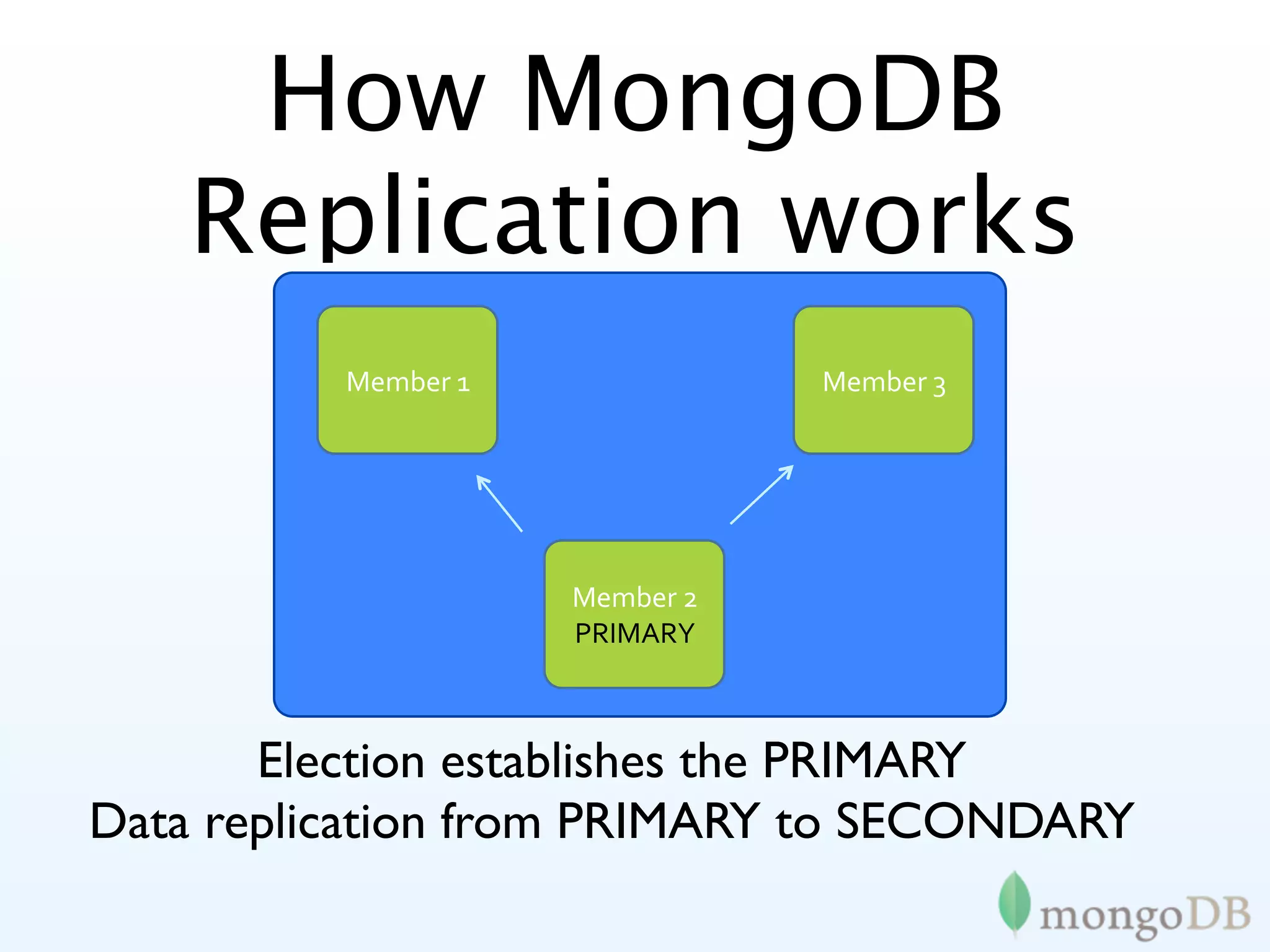
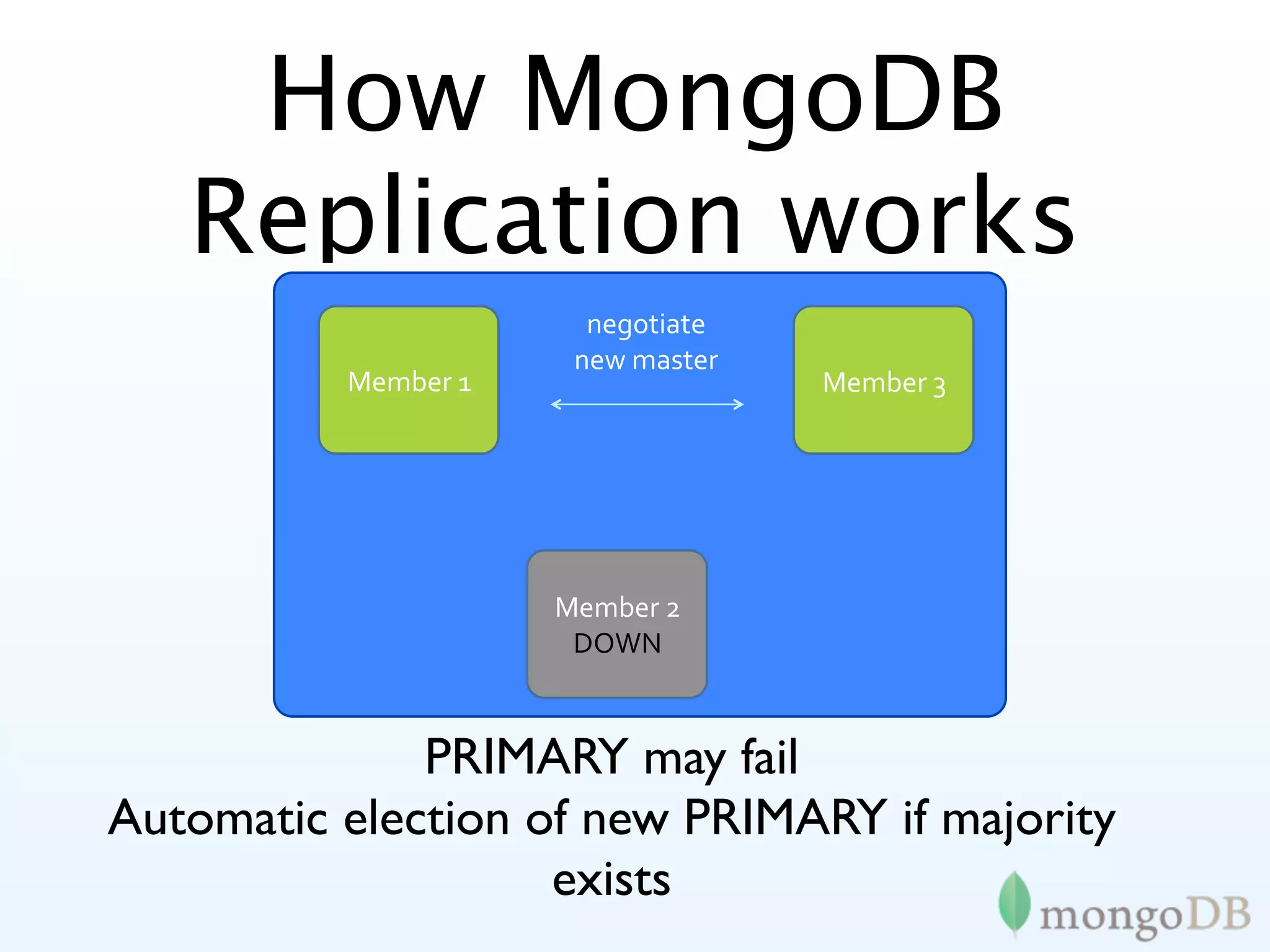
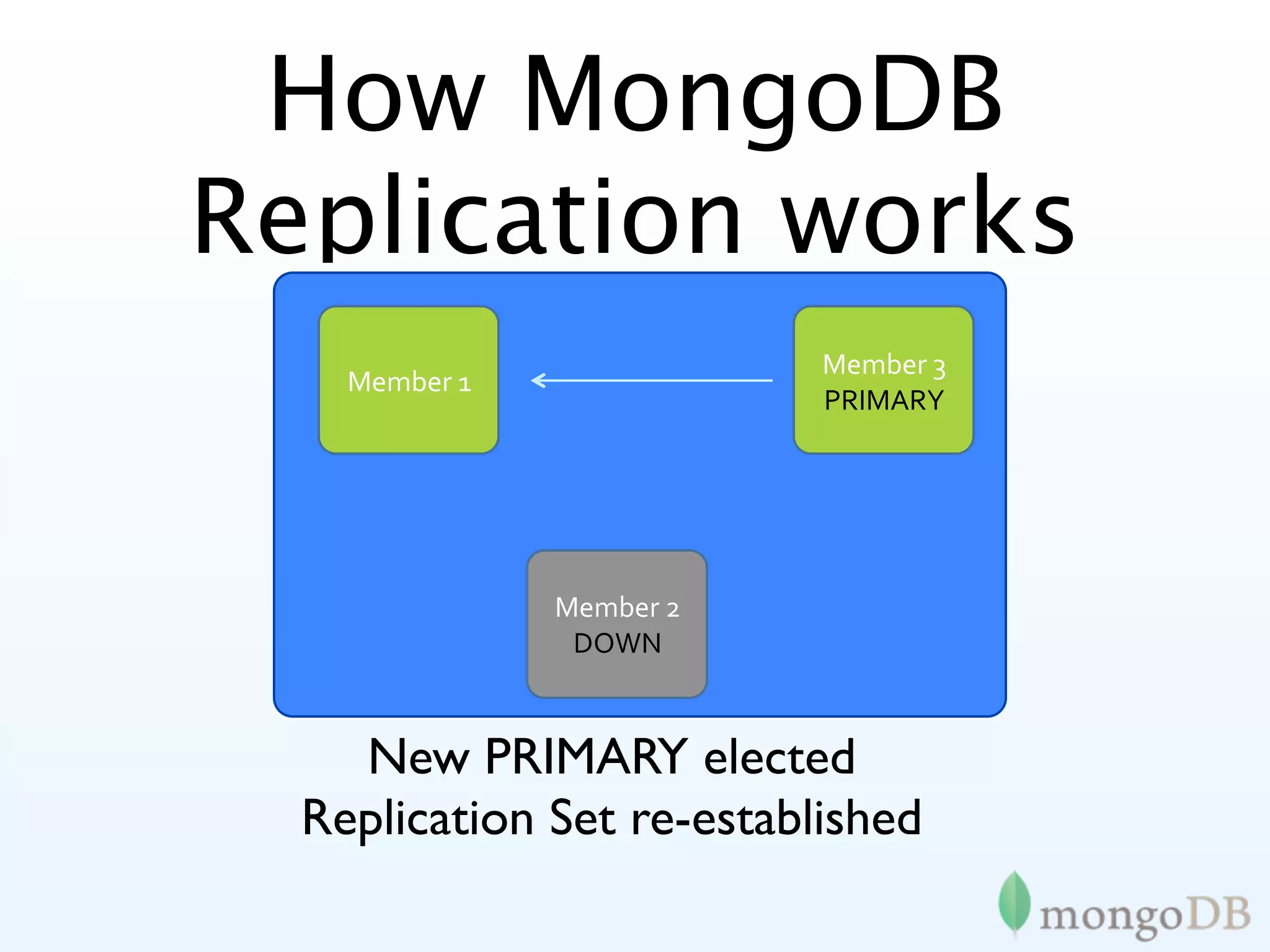
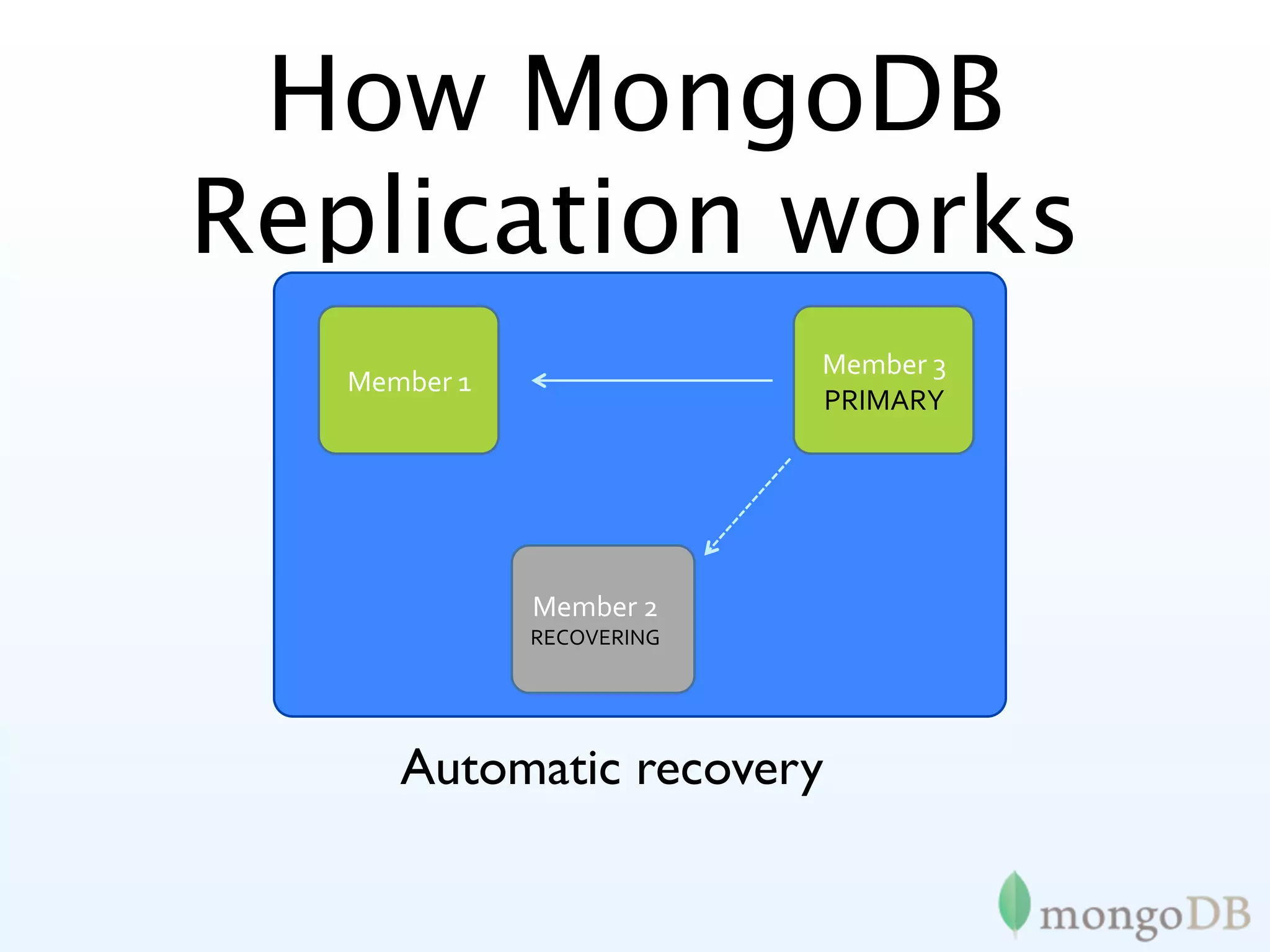
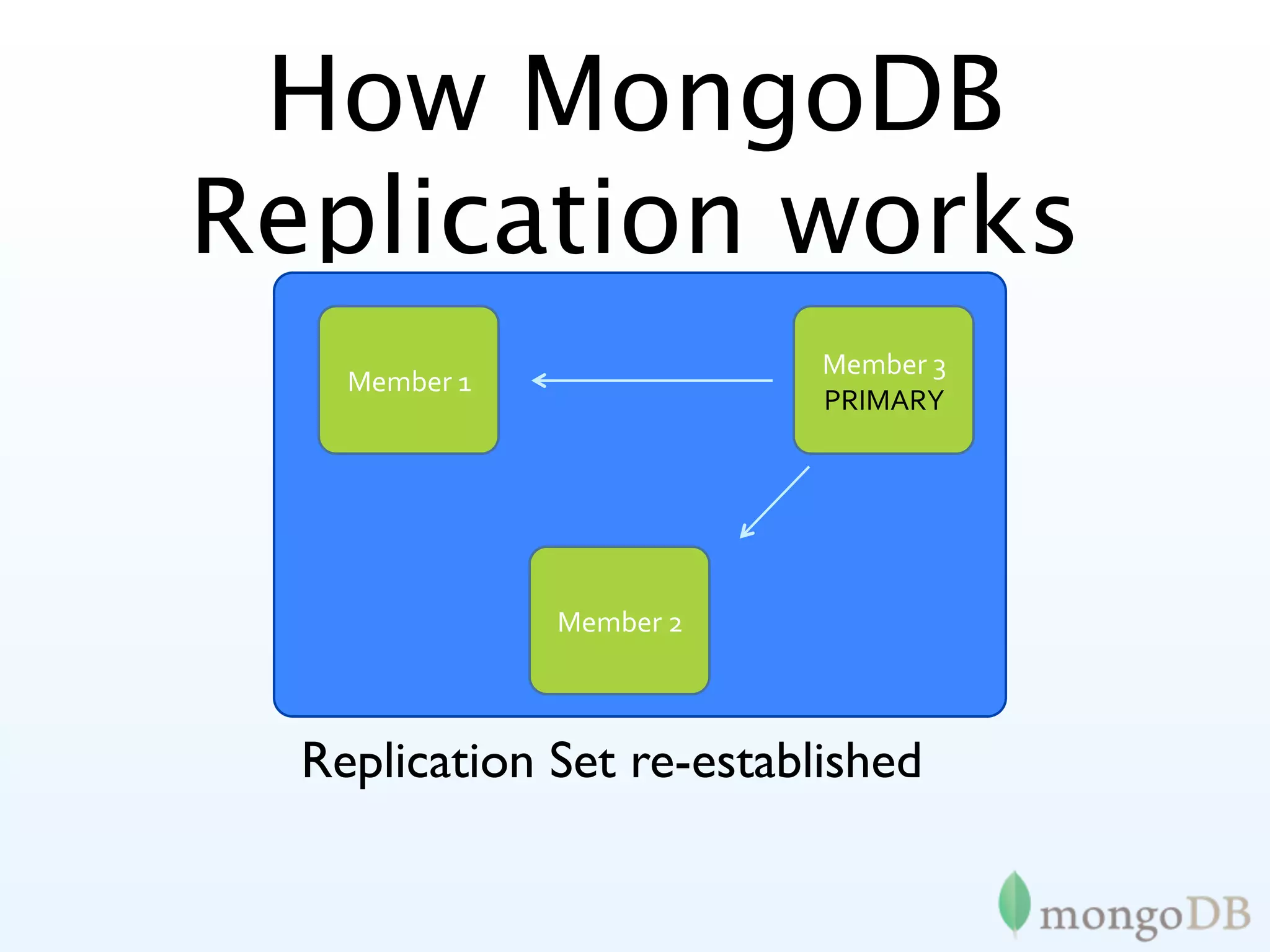
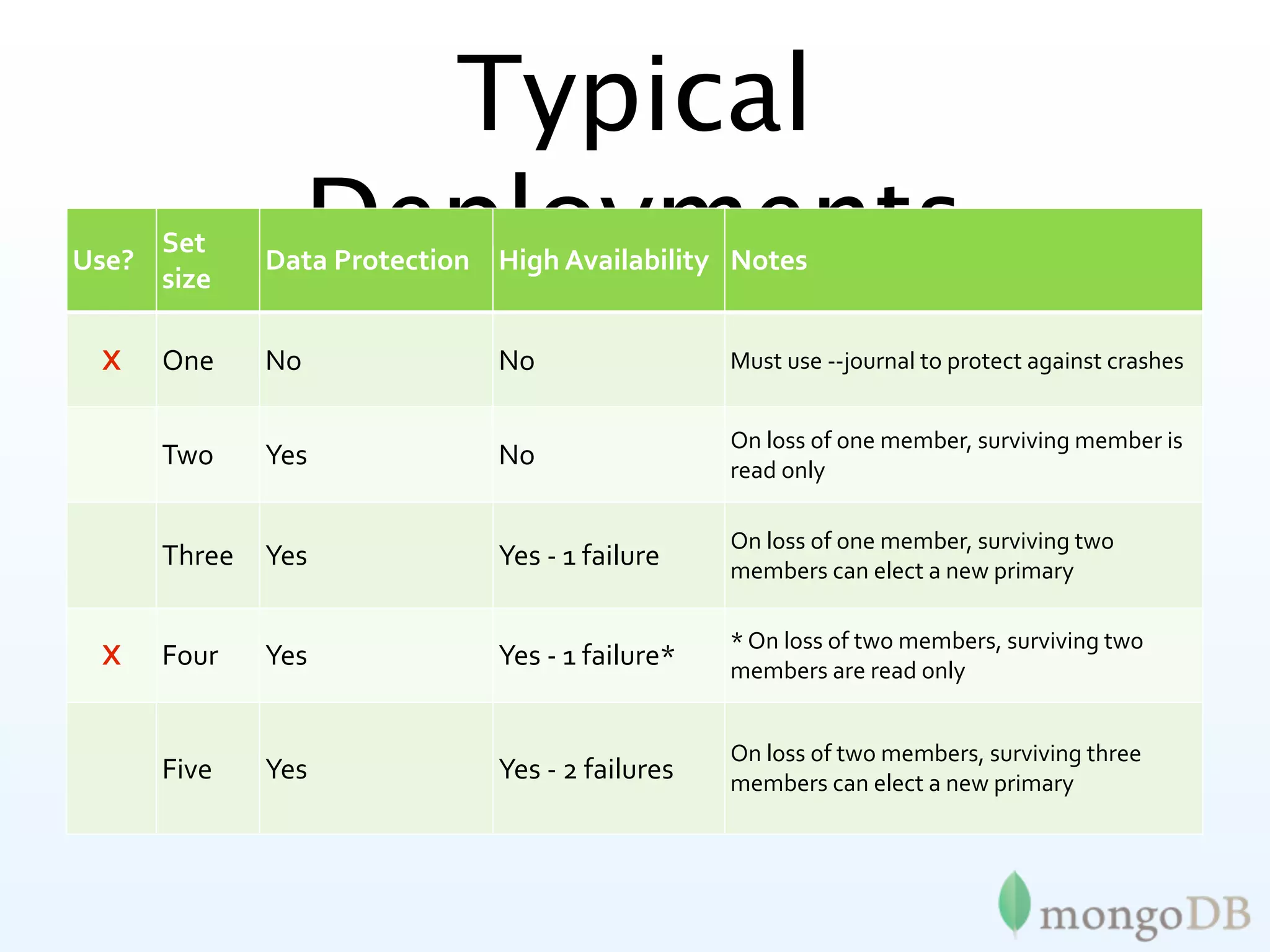
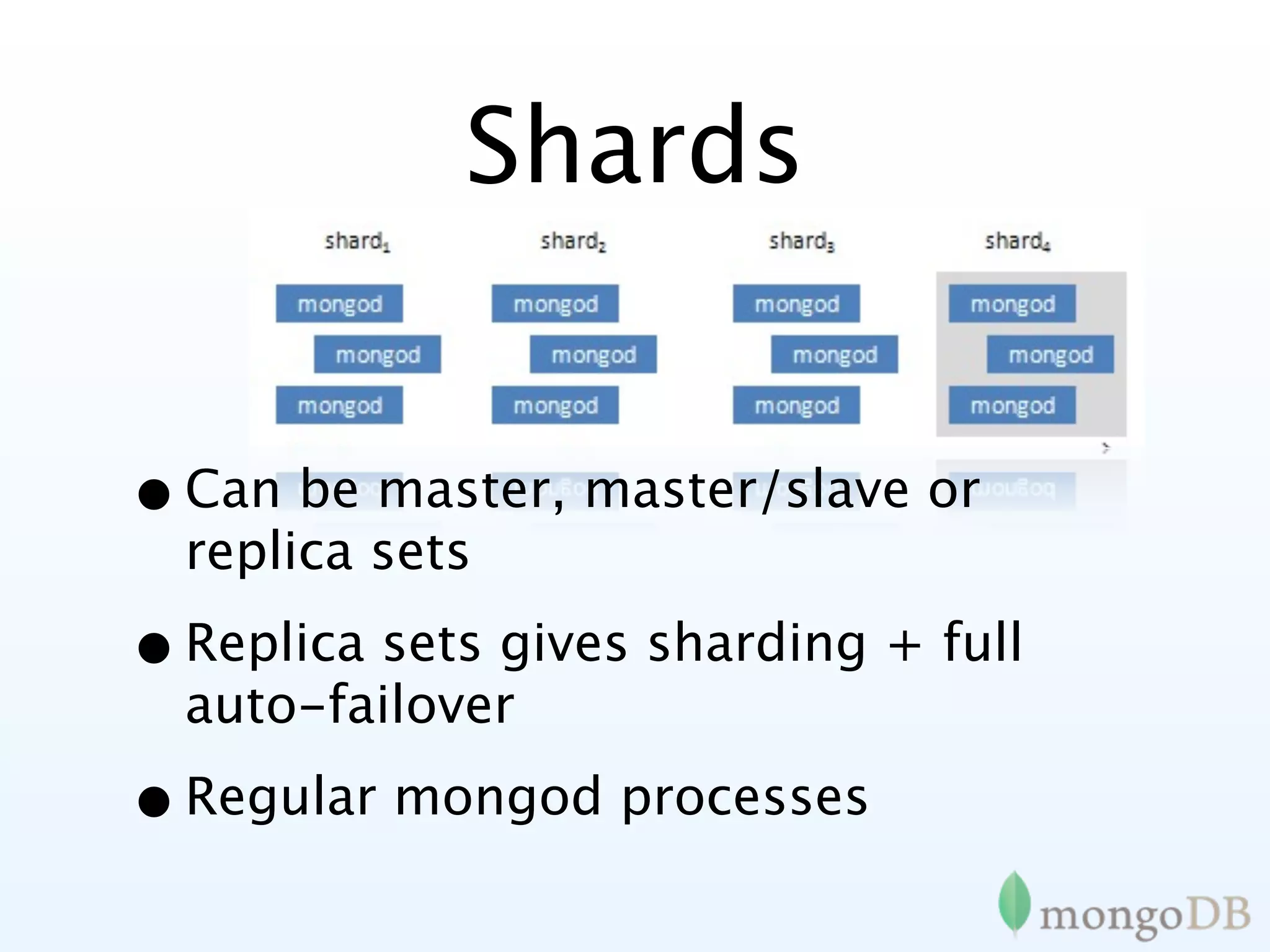
MongoDB's replication strategies including replica sets, achieving high availability and data safety.
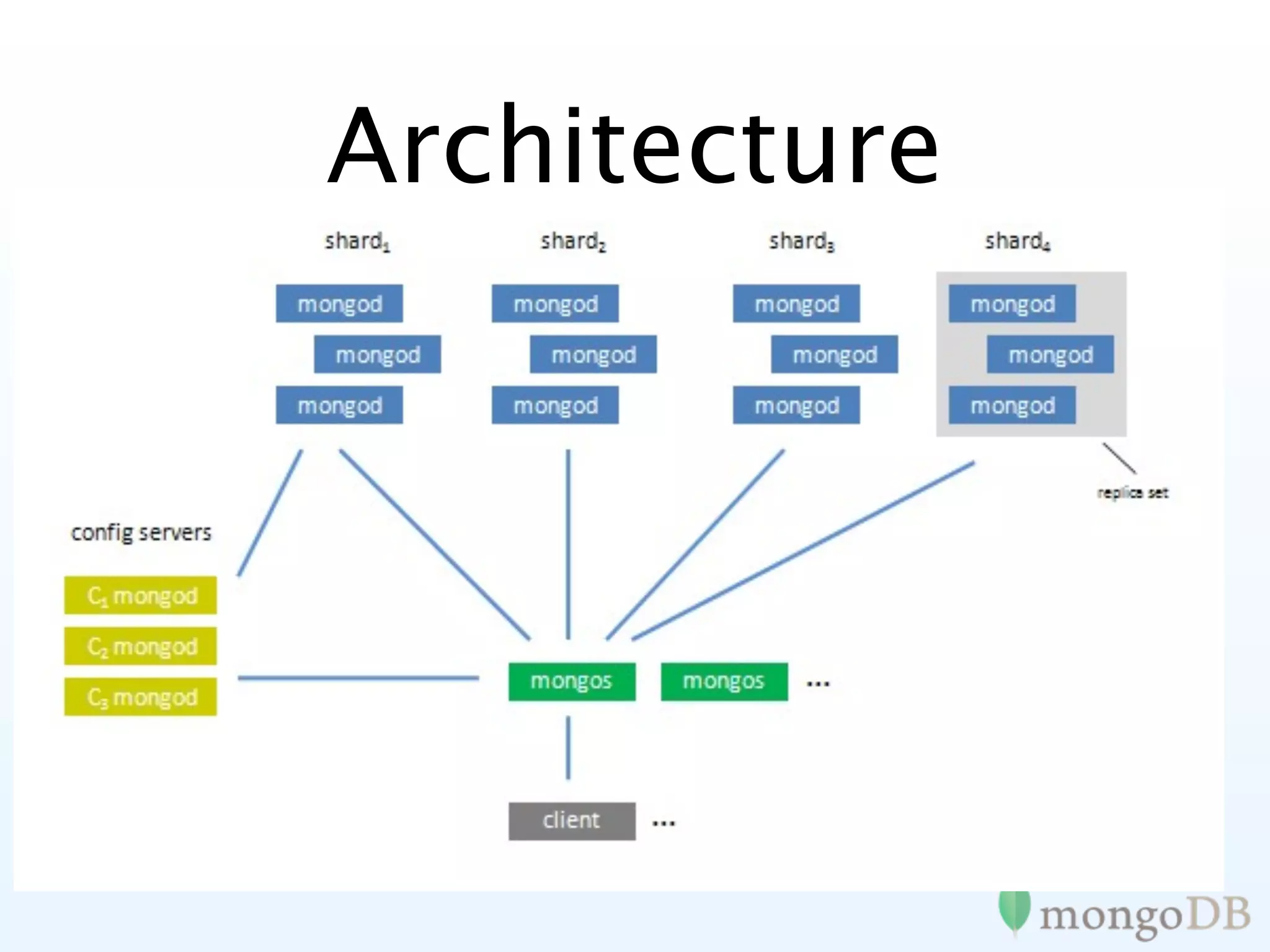
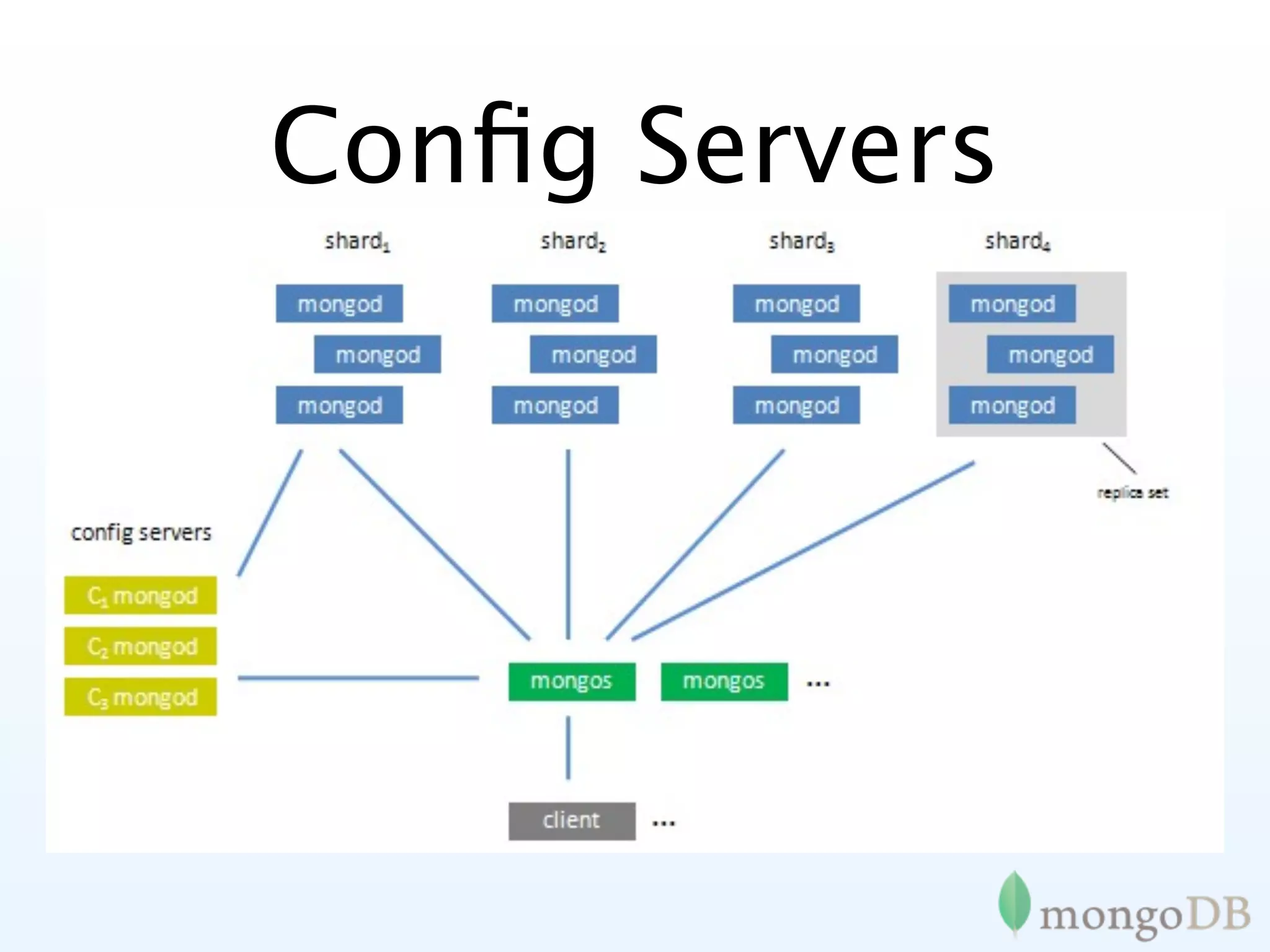
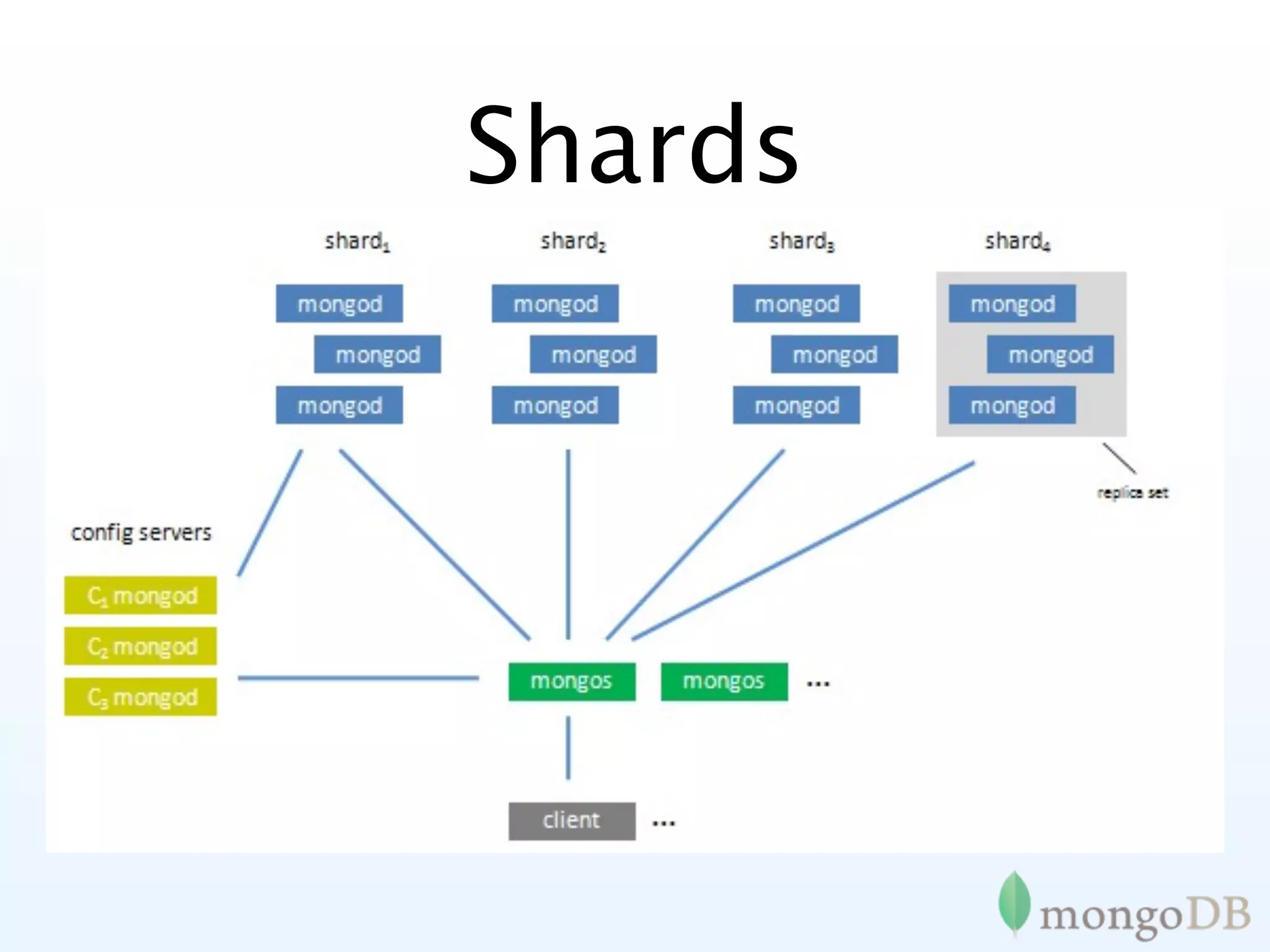
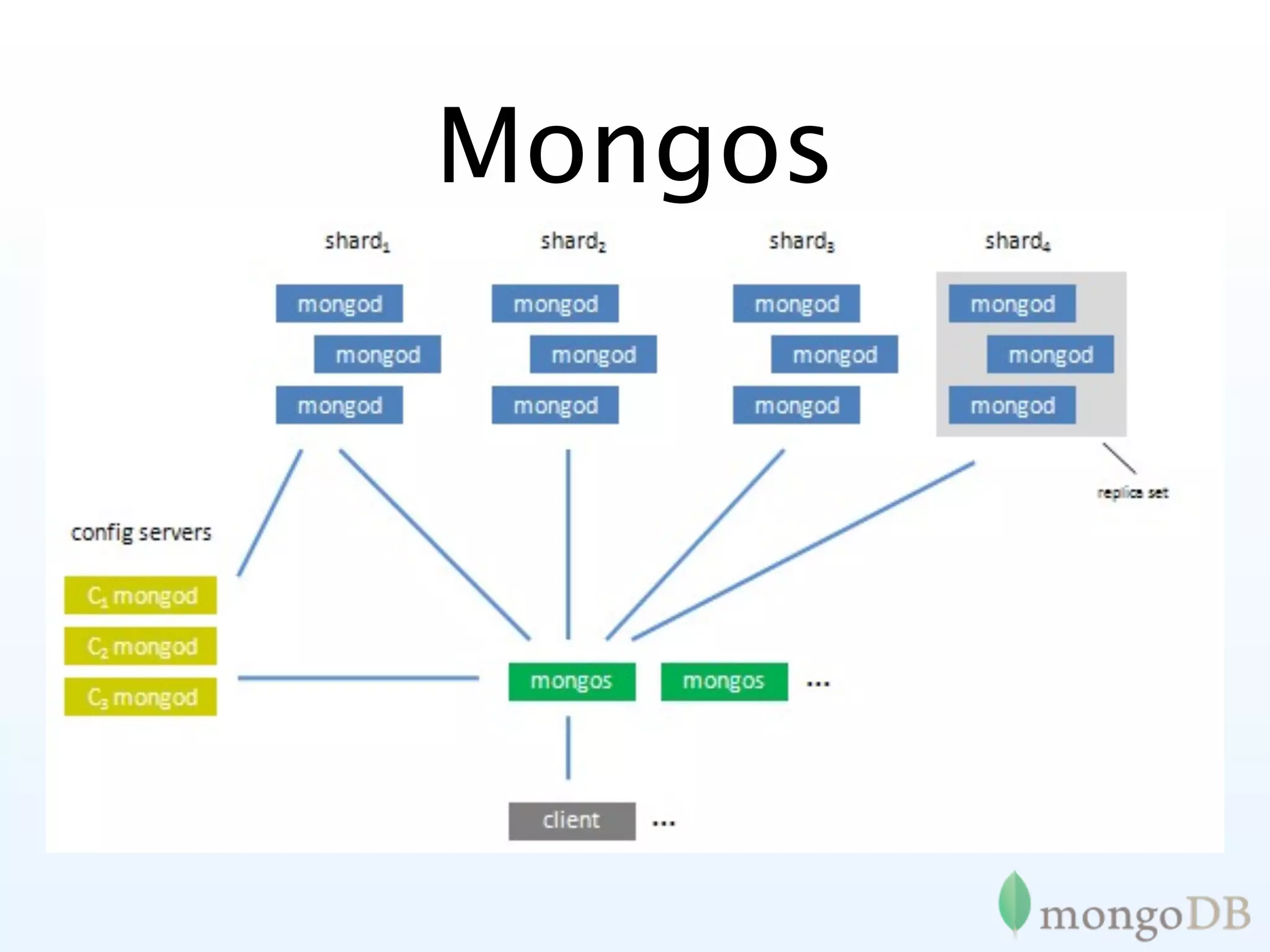
Introduction to sharding in MongoDB, explaining its automatic partitioning and management of data.
In-depth look at replica set configurations, election processes, and tagging for improved data writing control.
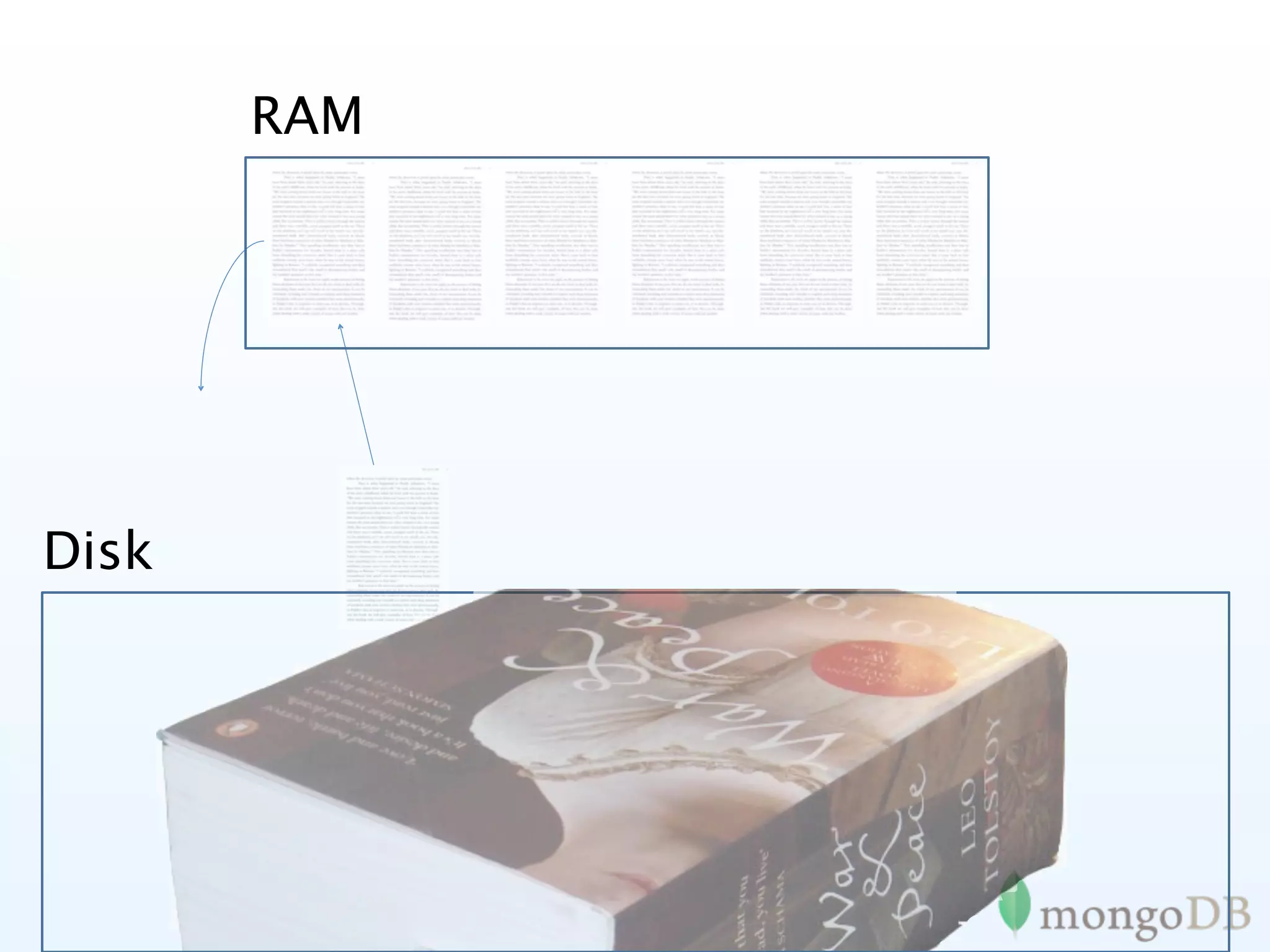
Strategies for optimizing application performance concerning data access patterns and minimizing memory turnover.
Final remarks by the speaker, inviting questions and providing resources for further engagement.















































![Understanding Oracle RAC 12c Internals OOW13 [CON8806]](https://cdn.slidesharecdn.com/ss_thumbnails/understandingoraclerac12cinternalsoow13con8806-131001010807-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










