Download to read offline













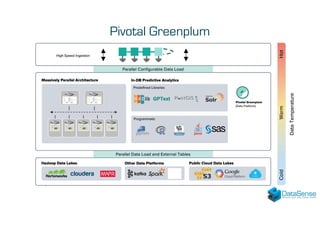
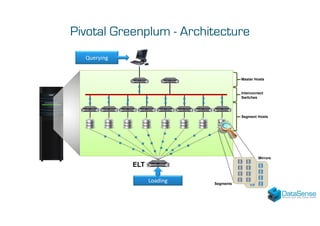










The document discusses Data Vault 2.0, a data modeling technique for integrating historical data from multiple sources. It then summarizes Pivotal Greenplum, an open source massively parallel processing database, and provides examples of reference cases using these technologies for data integration and analytics projects.






























![Dv decision makers presentation 310518[1]](https://cdn.slidesharecdn.com/ss_thumbnails/dvdecisionmakerspresentation3105181-180612001936-thumbnail.jpg?width=640&height=640&fit=bounds)
























































